High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion) 논문 리뷰
High-Resolution Image Synthesis with Latent Diffusion Models (Stable diffusion) 논문리뷰
1. Introduction
이미지 합성은 엄청난 계산적 요구가 필요함에도 불구하고, 컴퓨터 비전 분야에 있어서 가장 많은 발전을 이룩한 주제이다.
특히 요즘들어 고해상도의 복잡하며 자연스러운 장면을 합성하는 것은, 몇 억개의 파라미터를 보유한 자기회귀(autoregressive) 트랜스포머 모델을 비롯한 likelihood-based 모델을 scale-up 하는 과정을 통해 이루어져 왔다.
반대로 같은 역할에 있어서 GAN(Generative Adversarial Networks) 모델은 적대적 학습 과정에서 멀티 모달 학습의 분포와 모델의 복잡도를 스케일링하는 것이 힘들어 비교적 제한된 데이터와 적은 다양성을 보이는 것으로 밝혀졌다.
최근들어 계층적 denoising autoencoder를 이용하여 만들어진 diffusion model은 이미지 합성에 더불어 class-conditional image synthesis와 super-resolution 분야에서 SOTA(stast-of-the-art)의 성능을 내어 인상적인 결과를 이룩하였다.
더욱이 unconditional DM(Diffusion Model)은 여타 생성모델과 달리, inpainting and colorization, stroke-based synthesis 등의 task에 사용될 수 있는 모델이다.
우도 기반(likelihood-based) 모델과 같이, unconditional DM은 GAN 종류의 모델이 보이는 단점인 mode-collapse(생성 모델이 특정 몇 가지 mode만을 생성하고 다른 mode는 생성하지 못 하는 현상)와 training instablilities의 에러가 없다. 그리고 이러한 DM 모델은 자동회귀 모델이 가진 몇 억개의 파라미터를 이용해 복잡하고 다양한 분포를 가진 자연스러운 이미지를 만들어낼 수 있다.
Democratizing High-Resolution Image Synthesis : 고해상도 이미지 합성의 대중화
데이터의 가능도(likelihood)를 최대화하는 방식으로 모델 학습을 진행하는 likelihood-based model은 모델의 mode-coverage를 높이기 위하여 수많은 자원과 데이터를 필요로 하고, diffusion model 또한 likelihood-based model에 속한다.
비록 초기의 노이즈 제거 단계에서 가중치 재설정을 통한 변분을 통해 노이즈 제거의 sampling 횟수를 줄임으로써 이러한 계산 문제를 해결하려고 하지만, diffusion model을 훈련시키고 평가하는 과정에서 RGB 이미지의 고차원 공간 상에서 이루어지는 반복적인 함수 평가와 기울기 계산을 필요로 하기 때문에 여전히 많은 계산적 요구가 존재한다.
가장 강력한 diffusion model을 학습할 때, GPU 사용에 있어서 많은 시간이 필요하다. 그리고 noisy한 버전의 input space에 대한 반복 평가 또한 모델의 추론 과정을 복잡하게 만들어, 50,000개의 샘플을 생성하는 데 하나의 A100 GPU로 약 5일이 걸린다고 한다.
이러한 상황은 연구자와 일반 유저들한테 다음과 같은 두 상황을 초래한다.
- diffusion model을 훈련시키기 위해서는 엄청난 컴퓨팅 자원이 필요하며, 이런 자원 사용량은 AI 분야의 소수의 집단만이 이용 가능하다. 또한 모델의 자원 사용량으로 인해 막대한 탄소 발자국을 남기게 된다.
- 이미 훈련이 완료된 모델을 평가하는 것은 시간과 메모리를 매우 비싸게 잡아먹는 행위이다. 왜냐하면 똑같은 모델 구조가 많은 수의 스텝(25~1000 step)동안 순차적으로 실행되어야 하기 때문이다.
강력한 diffusion model 클래스의 접근성을 높이면서 모델의 자원 사용량을 줄이기 위해, 훈련 과정과 샘플링 과정 모두에서의 계산 복잡도를 줄이기 위한 방법이 요구된다.
결국, diffusion model의 퍼포먼스를 손상시키지 않으면서 계산적 요구사항을 줄이는 것이 모델의 접근성을 높이는 데 가장 중요한 핵심이다.
Departure to Latent Space : 잠재 공간으로의 전환
우리의 접근은 훈련이 완료된 diffusion model을 픽셀 공간에서 분석하는 과정에서 시작된다.
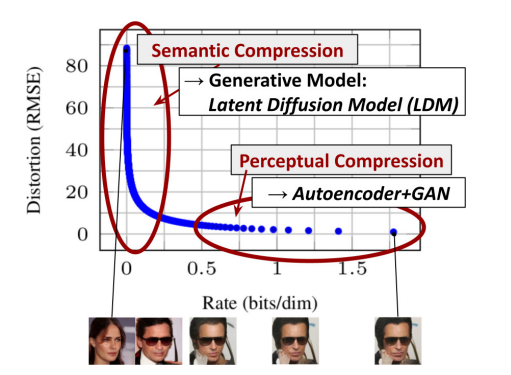
위의 그림은 훈련이 완료된 diffusion model의 rate-distortion tradeoff(비율-왜곡 트레이드오프)를 보여준다.
다른 여러 likelihood-based model와 같이, diffusion model의 학습 과정은 대략적으로 다음의 두 과정으로 나누어진다.
- 의미론적 변화(semantic variation)에 대한 학습을 어느 정도 적게 유지하면서 고주파의 세부 사항(high-frequency details)를 제거하는 인지적 압축 단계(perceptual compression stage)
- 실세 생성 모델이 데이터의 의미론적, 개념적 구성을 학습하는 의미론적 압축 단계(semantic compression stage)
우리는 먼저, 이 과정에서 인지적으로 동등하지만 계산적으로 더 적합한 공간을 찾아 그 공간 상에서 고해상도 이미지 합성을 위한 diffusion model을 훈련시킬 것이다.
일반적인 관행을 따라 우리는 학습 과정을 두 개의 단계로 구별할 것이다.
- 데이터의 공간과 인지적으로 동일한 저차원의 효율적인 표현 공간(representation space)를 제공하는 오토인코더를 훈련시킨다. 공간의 차원성에의 관점에서 더 나은 확장적 특성을 나타내는 잠재 공간 상에서 diffusion model을 훈련시킨다는 점에서 이전의 작업들과는 대조적으로, 이 과정을 통해 우리는 과도한 공간 압축에 의존할 필요가 없어진다.
- 이러한 과정을 통하여 감소된 모델의 복잡성은, 단일 네트워크 패스를 통해 잠재 공간 상에서 효율적인 이미지를 생성하여 제공할 수 있다.
위의 학습 과정을 거쳐 생성된 모델을 우리는 잠재적 확산 모델(Latent Diffusion Models : LDMs)라고 부른다.
이러한 접근 방법을 통해 우리는 universal autoencoding stage를 딱 한 번만 학습한다는 괄목할만한 장점을 얻을 수 있고, 따라서 여러 diffusion model의 학습에 이를 재사용하거나 완전히 다른 작업에 대한 탐구가 가능하다. 이는 image-to-image task, text-to-image task 등에 대한 diffusion model의 효율적인 탐구를 가능하게 한다.
text-to-image의 경우, 우리는 transformer 모델과 diffusion model의 UNet 기반 구조를 연결하여 만든 아키텍처를 설계하고 임의의 token-based 조절 메커니즘을 가능하게 만든다. 이 과정은 2.3 Conditioning Mechanism에서 자세히 설명한다.
요약하자면, 우리의 연구는 다음과 같은 기여를 한다.
- 순수 transformer-based 접근법과 달리 우리의 접근법은 더 높은 차원의 데이터로 우아하게 확장될 수 있고, 따라서 (a) 과거의 모델보다 더 충실하고 상세한 재구성을 제공하는 압축 수준에서 작동할 수 있고 (b) megapixel 단위의 이미지의 고해상도 합성에 효율적으로 적용될 수 있다.
- unconditional image synthesis, inpainting, stochastic super-resolution 등의 여러 작업 및 데이터셋에서 경쟁력 있는 성능을 달성하였고, 동시에 모델의 계산 비용을 크게 줄였다. 픽셀 기반 접근법과 비교하여 추론 비용 또한 크게 줄였다.
- 사전에 endocer/decoder 아키텍처와 score-based를 동시에 학습해야 하는 이전 모델과 달리, 우리의 접근은 이미지의 재구성과 생성 능력을 위한 미묘한 가중치 조절 과정이 필요하지 않다. 이로 인해 매우 충실한 이미지 재구성을 할 수 있으며, 잠재 공간의 규제(regularization)가 거의 필요하지 않게 된다.
- super-resolution, inpainting & semantic synthesis 등과 같은 밀도 높은 조건부 작업에 대해, 우리의 모델이 컨볼루션 방식으로 적용될 수 있으며 대략 $1024^2$ pixel의 크고 일관된 이미지를 렌더링할 수 있는 것을 발견하였다.
- 더욱, 우리는 cross-attention 기반의 다목적 범용 컨디셔닝 메커니즘을 구축하여 멀티 모달 학습을 가능하게 하였다. 이것을 사용하여 class-conditional, text-to-image, layout-to-image 모델을 훈련시킬 수 있다.
2. Method
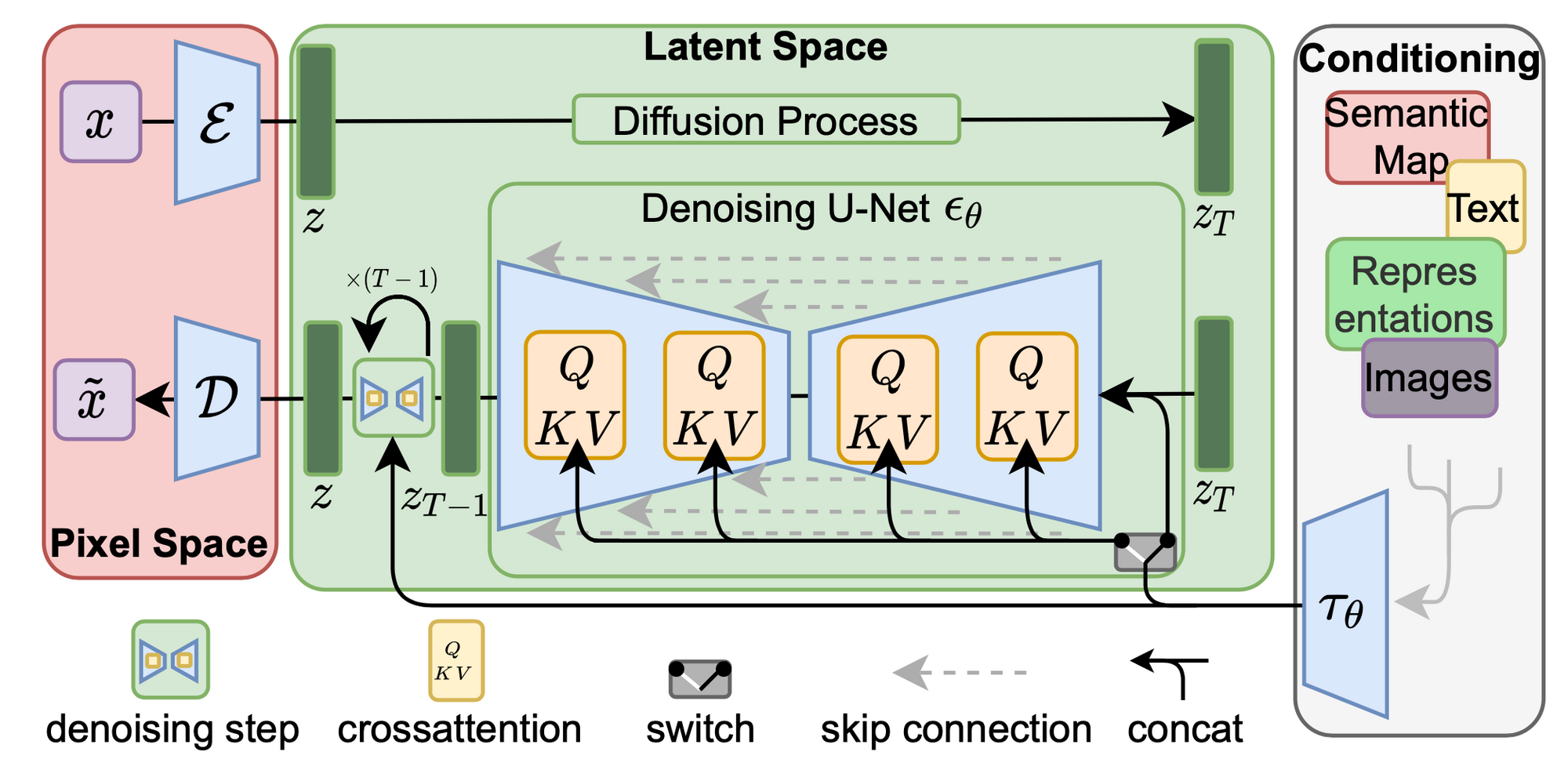
고해상도 이미지 합성 과정에서 diffusion model의 계산적 요구를 줄이기 위해서 우리는 diffusion model이 해당되는 손실 항목을 샘플링을 줄임으로써 지각적으로 중요하지 않은 세부 사항을 무시할 수 있음을 관찰했지만, diffusion model은 여전히 픽셀 공간 상에서의 함수 평가에서 많은 비용이 요구됨을 알 수 있다. 이로 인해 계산 시간과 에너지 자원에 대한 엄청난 요구가 발생한다.
우리는 모델의 압축 단계와 생성 학습 단계를 명확하게 분리함으로써 이러한 단점을 우회하도록 제안한다.
이러한 과정을 달성하기 위해, 우리는 image space와 지각적으로(perceptually) 동등한 공간을 학습하지만, 계산 복잡도를 훨씬 낮추어주는 autoencoding model을 활용할 것이다.
이런 접근 방식은 여러 가지 advantage를 제공한다.
- 고차원적인 이미지 공간을 벗어나 저차원의 공간에서 이미지를 샘플링함으로써, 계산적으로 훨씬 효율성있는 diffusion model을 이용할 수 있다.
- 우리는 UNet 아키텍쳐로부터 계승된 diffusion model의 inductive bias를 활용하여, 데이터의 공간적인 구조를 이용해 모델을 더 효율적으로 만들 수 있다. 이러한 과정을 통해 이전의 접근의 압축 과정의 퀄리티 저하를 상쇄시킬 수 있다.
- 마지막으로, 우리는 latent space(잠재 공간)를 이용하여 여러 종류의 생성 모델을 훈련시킬 수 있으며, 이렇게 훈련시킨 다목적 압축 생성 모델은 단일 이미지 CLIP-가이드 합성과 같은 여러 downstream application에 활용될 수 있다.
2.1. Perceptual Image Compression
우리의 지각적 압축 모델은 이전의 연구를 기반으로 하며, 지각 손실과 patch-based 적대적 목적함수의 조합을 이용하여 훈련된 오토인코더로 구성되어 있다. 이러한 구성은 이미지의 지역적인 특성을 강제함으로써 이미지 매니폴드 범위 안에서만 이미지 재구성이 일어나도록 제한하고, $L_2$나 $L_1$과 같은 픽셀 공간에서의 손실에만 의존함으로써 발생하는 이미지의 bluriness를 막아줄 수 있다.
더 상세하게 RGB 공간 상에서 이미지 x가 $x \in \R^{H\times W\times 3}$로 표현될 때, 인코더 $\xi$는 x를 잠재 표현(latent representation) $z$로 인코딩한다. 즉 $z=\xi(x)$이며, 디코더 $D$는 $z\in\R^{h\times w\times c}$인 잠재 표현 $z$로부터 이미지를 재구성하여 $x=D(z)=D(E(x))$를 산출한다.
인코더는 인자 $f = H/h = W/w$ 를 이용하여 이미지를 다운샘플링하는데, 이 때 우리는 $m \in \N$을 만족하는 다른 다운샘플링 인자 $f = 2^m$ 를 연구하였다.
임의의 잠재 공간이 높은 분산을 갖는 것을 피하기 위해, 우리는 두 가지의 규제 방법을 연구하였다.
첫 번째 변형인 KL-reg는 학습된 잠재 변수에 표준 정규 분포에 가까운 약간의 KL-penalty를 부과하는데, 이는 VAE(Variational AutoEncoder)와 유사한 과정이다. 반면 VQ-reg는 디코더 내에 벡터 양자화(Vector Quantization) 계층을 이용하여 규제를 적용한다.
이 모델은 VQGAN으로 해석될 수 있지만, 양자화 계층이 디코더에 의해 흡수되어 있다는 점에서 다르다. 우리의 후속 diffusion model(LDM)이 2차원 구조의 학습된 잠재 공간 $z=E(x)$로 작동되도록 설계되었기 때문에, 우리는 상대적으로 약한 압축률을 이용할 수 있고 더 질 좋은 이미지 재구성을 달성할 수 있다.
이것은 학습된 공간 $z$의 분포를 순차적으로 모델링하기 위해 $z$ 내부의 종속적 구조를 무시하며 임의적으로 1차원으로 순서화시킨 것에 의존하였던 과거의 모델과 대조적이다.
따라서, 우리의 압축 모델은 이미지 $x$의 디테일을 더 잘 보존할 수 있다.
2.2. Latent Diffusion Models
Diffusion Model은 데이터 분포 $p(x)$를 학습하기 위해 설계된 확률론적 모델로, 정규 분포로 이루어진 변수를 점진적으로 denoising하며 학습을 진행한다. 이는 길이 $T$의 고정된 마르코프 체인을 역으로 학습하는 것과 대응된다.
이미지 합성 분야에서, 가장 성공적이었던 모델들은 p(x)에 대한 가중치가 다른 변분 하한에 의존하며 이는 denoising score-matching을 반영한다.
이 모델들은 동일한 가중치 시퀀스의 denoising 오토인코더 $\epsilon_\theta (x_t, t); t=1…T$ 로 해석될 수 있고, 이것은 변수 $x$의 noisy한 변수인 $x_t$를 인풋으로 하여 $x_t$의 noise를 제거한 변수를 예측하도록 훈련된다.
이 훈련에 대응되는 목적함수는 아래와 같이 표현된다.
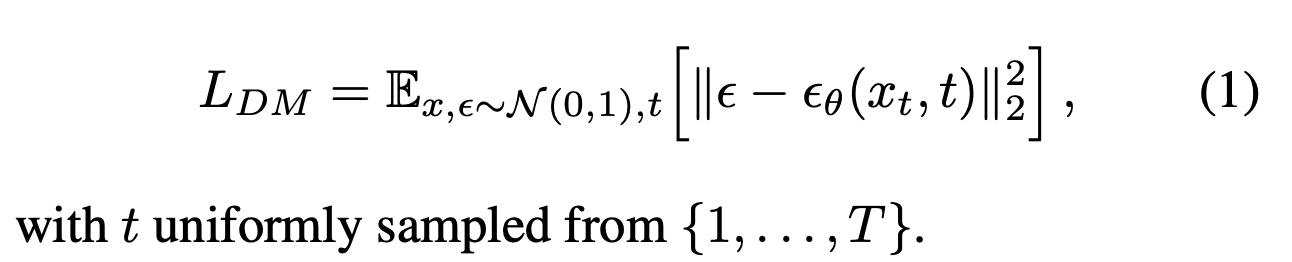
Generative Modeling of Latent Representations
E와 D를 포함하여 우리가 훈련시킨 지각적 압축 모델을 이용해, 우리는 고주파의 감지하기 어려운 디테일이 추상화된 효율적이고 저차원적인 잠재 공간에 접근할 수 있게 됐다. 고차원의 픽셀 공간과 비교했을 때, 이 잠재 공간은 데이터의 중요하고 의미있는 공간에 집중할 수 있고, 더 낮은 차원의 계산적으로 효율적인 공간에서 훈련할 수 있기 때문에 likelihood-based 생성 모델에 더욱 적합하다.
자기회귀(autoregressive) 모델, 고압축, 이산적 잠재 공간에서의 attention-based 트랜스포머 모델에 기반한 과거의 작업과는 다르게, 우리는 latent diffusion model이 제공하는 image-specific inductive bias의 이점을 취할 수 있다.
이 이점에는 2D convolutional layer로 기본적인 UNet을 구축하는 능력을 포함하며, 가중치가 조절된 경계를 이용하여 이미지에서 지각적으로 가장 관련된 부분에 포커징하는 것을 포함한다. 이 방법의 효율성과 정확성은 아래의 수학적 표현과 설명을 통해 강조된다.
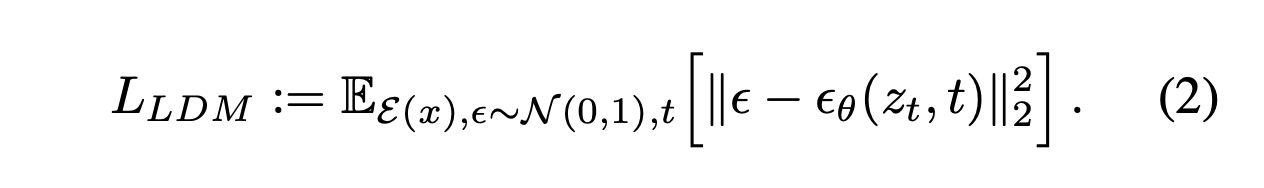
이 모델의 신경 구조 $\epsilon_{\theta}(\circ, t)$는 time-conditional UNet을 통하여 구현된다. 전방 프로세스가 고정되어 있기 때문에, $z_t$는 훈련 과정 중에서 $E$를 통하여 효율적으로 획득할 수 있다. 그리고 $p(z)$에서 추출한 샘플들은 $D$를 통한 단일 패스에서 이미지 공간으로 decode될 수 있다.
2.3. Conditioning Mechanisms
다른 유형의 생성 모델과 마찬가지로 diffusion model은 $p(z|y)$ 형태의 조건부 분포를 모델링할 수 있다. 이는 conditional denoising 오토인코더 $\epsilon(z_t, t, y)$로 구현될 수 있으며, text, semantic maps, image-to-image translation 등과 같은 인풋 $y$를 통해 합성 과정을 제어하는 방법을 제공할 수 있다.
그러나, 이미지 합성 과정에서 클래스-라벨 또는 입력 이미지의 흐릿한 변형을 넘어서 diffusion model의 생성력과 다른 conditional variant를 결합하는 것은 아직 연구되지 않은 미지의 영역이다.
우리는 diffusion model을 cross-attention 메커니즘을 이용하여 UNet의 기본 구조를 확장함으로써 보다 유연한 conditional 이미지 생성기로 전환할 수 있다. 이 메커니즘은 다양한 모달리티의 입력을 이용하여 학습하는 attention-based 모델에서 효과적이다.
다양한 모달리티(예: 언어 프롬프트)에서 $y$를 전처리하기 위해, 우리는 도메인 특화적인 인코더 $\tau_{\theta}$를 도입했다. 이것은 $y$를 중간 표현 $\tau_{\theta}$로 projection하여 UNet의 중간 계층으로 cross-attention 계층을 통해 매핑된다.
cross-attention 계층에서의 매핑은 $Attention(Q, K, V) = softmax(\dfrac{QK^T}{\sqrt d})$를 통해 구현된다. 여기서 $Q$(Query), $K$(Key), $V$(Value)는
\(Q = W^{(i)}_Q\cdot\varphi_i(z_t), K = W^{(i)}_K \cdot \tau_{\theta}(y), V = W^{(i)}_V \cdot \tau_{\theta}(y)\) 이다.
여기서, $\varphi_i(z_t) \in \R^{N \times d^i_{\epsilon}}$은 $\epsilon_{\theta}$를 구현하는 UNet의 평탄화된 중간 표현을 나타내며 \(W^{(i)}_V \in \R^{d\times d^i_{\epsilon}}, W^{(i)}_Q \in \R^{d \times d_{\tau}} \& W^{(i)}_K \in \R^{d \times d_{\tau}}\)는 학습 가능한 projection 행렬들이다.
image-conditioning pair를 기반으로, 우리는 아래의 수식을 통해 conditional LDM을 학습할 수 있다.
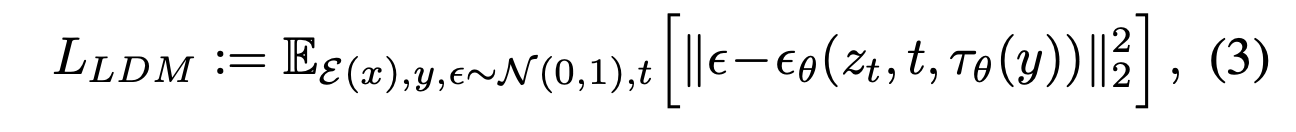
이 방정식을 통해 $\tau_{\theta}$와 $\epsilon_{\theta}$가 공통으로 최적화된다. 이러한 조건화 메커니즘은 $\tau_{\theta}$가 도메인에 특화된 전문가로 parameterinzing될 수 있기 때문에 매우 유연하다. 예를 들어, $y$가 text prompt일 경우 모델로 unmasked transformer를 사용할 수 있다.
3. Limitations & Societal Impact
Limitations
pixel-based 접근에 비해 Latent Diffusion Model의 계산적 요구를 매우 감소시켰음에도 불구하고, 아직 GAN에 비해 모델의 순차적 샘플링 프로세스의 처리 속도는 매우 느린 편이다.
더욱이, 높은 정밀도가 필요할 때 LDM의 사용에는 의문 부호가 붙는다. downsampling factor $f=4$인 오토인코딩 모델의 이미지 품질의 loss는 매우 작지만, LDM의 이미지 재구성 능력은 픽셀 공간에서의 미세한 정확도(fine-grained)가 필요한 작업에서 병목 현상으로 발휘될 수 있다.
우리는 우리의 초고해상도(superresolution) 모델들이 이미 이런 관점에서 제한적이라고 생각한다.
Societal Impact
이미지와 같은 미디어를 위해 사용되는 생성 모델은 양날의 검과 같다.
한 편으로는 이것은 다양한 창의적 응용 프로그램을 만들 수 있게 하며, 특히 우리의 모델과 같이 훈련 비용과 추론 비용을 줄이는 과정은 이런 기술에 대한 접근성을 높이고, 기술에 대한 연구를 대중화할 수 있는 잠재력을 갖고 있다.
반면에, 이것은 조작된 데이터를 생성하고 전파하거나 잘못된 거짓 정보와 스팸을 퍼뜨리기가 더 쉬워진다는 것을 의미한다. 특히, 의도적인 이미지 조작(deep fakes)는 이러한 유형의 문제중 가장 대표적인 문제이고, 특히 여성들이 이로 인한 영향을 더욱 과도하게 받고 있다.
생성 모델은 모델의 훈련 데이터를 공개하는 것 또한 가능하다. 데이터가 민감하거나 개인 정보를 포함하고 있고 명시적인 동의 없이 수집되었을 때, 이것은 큰 우려사항이 될 수 있다. 그러나, 이미지가 diffusion model에 얼마나 어느 정도로 적용되는 지에 대해서는 아직 완전히 이해되지 않은 영역이다.
마지막으로, 딥러닝 모듈은 데이터에 존재하는 편향을 재현하거나 확대하는 경향이 있다. diffusion model이 GAN 기반 접근법보다 더 포괄적으로 주어진 데이터에 대한 분포를 학습할 수 있지만, 우리의 likelihood-based와 적대적 훈련을 혼합한 두 단계의 접근법이 주어진 데이터를 얼마나 잘 못 나타낼 지에 대한 범위는 중요한 연구 주제로 남겨져있다.
4. Conclusion
우리는 Denoising Diffusion Model을 훈련과 샘플링의 퀄리티를 유지하면서 그 과정의 효율을 모두 크게 증대시키는 Latent Diffusion Model(잠재적 확산 모델)을 공개하였다.
LDM과 cross-attention conditioning 메커니즘을 기반으로 하여, 우리의 연구는특정 task-specific 아키텍처의 필요가 없이 다양한 조건적인 이미지 합성에 있어서 SOTA(State-Of-The-Art) 모델과 비교하여 더욱 만족스러운 결과를 내는 결과를 보여줄 수 있었다.