Zero-shot learning & Few-shot learning, Chain of thought (COT)
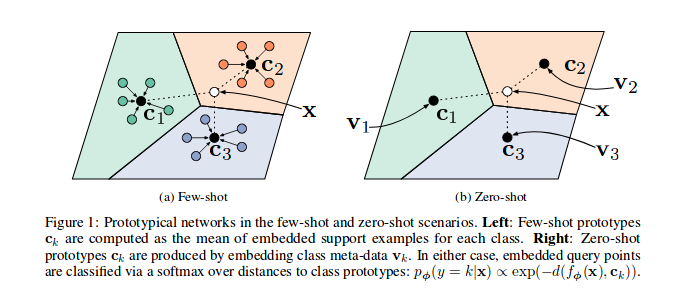
Zero-shot Learning & Few-shot Learning, Chain-of-thought
본 게시글은 2023년도 스탠포드 강의 CS224n의 lecture 11 -prompting, rlhf의 내용을 정리한 게시글입니다.
0. Introduction
0-1. Larger and Larger models
현재 개발되고 있는 언어 모델들의 computing scale은 점점 커지고 있다.
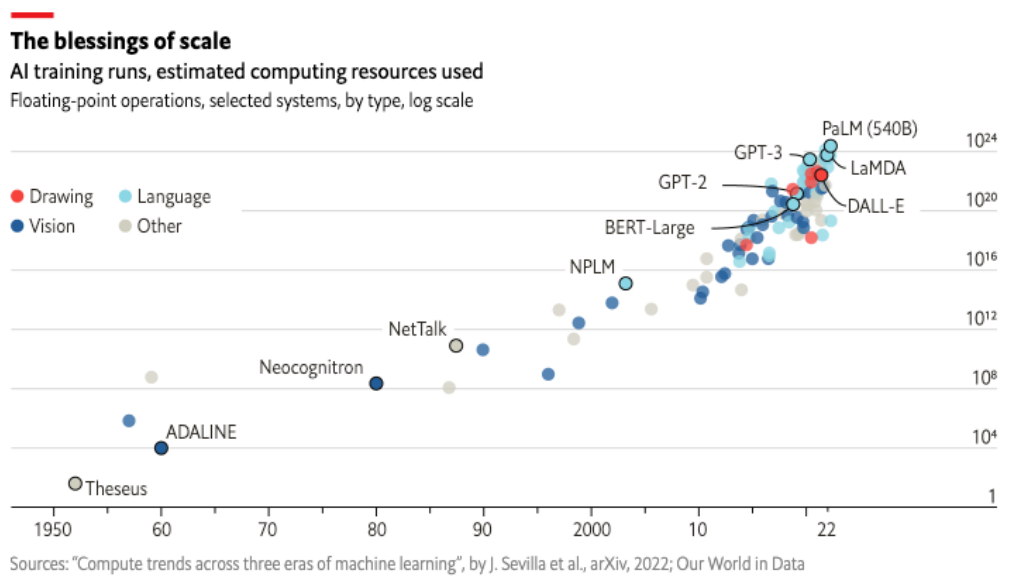
AI 모델이 요구하는 컴퓨팅 자원의 스케일은 기하급수적으로 증가하고 있고, 특히 요즘 시대의 LLM은 parameter를 tuning시키는 과정에서 엄청난 컴퓨팅 자원을 요구하고 있다.
0-2. Trained on more and more data

출처 : https://babylm.github.io/
더불어 언어 모델의 parameter를 tuning할 때 사용되는 데이터의 양 또한 어마어마하게 증가하고 있고, 2022년에 발표된 언어 모델 Chinchilla의 경우 학습을 할 때 1.4조(Trillion) 개의 토큰을 이용하는 것으로 드러났다.
0-3. Language models as World models & multitask assistants
우리는 언어 모델을 이용하여, 우리의 사고를 추론하는 과정에서 기초적인 도움을 받을 수 있다. 그 예시는 아래의 사진과 같다.

$\uparrow$ 수학에 이용하는 경우
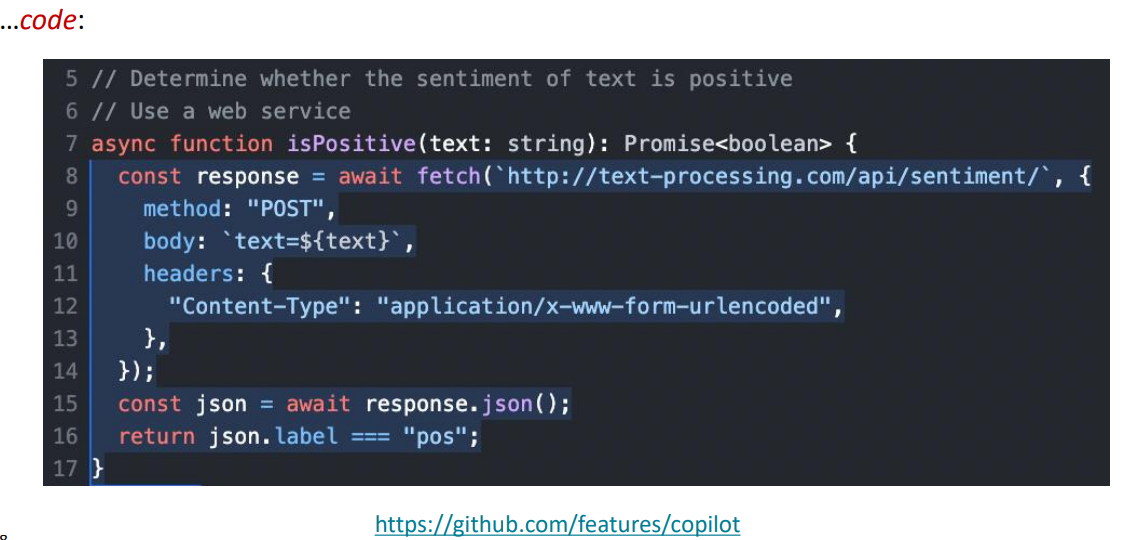
$\uparrow$ 코딩에 이용하는 경우

$\uparrow$ 의학에 이용하는 경우
또한 2023년부터 Bard(Gemini), ChatGPT 등 언어 모델을 이용한 QA Chatbot 서비스가 매우 유행이다. 언어 모델은 우리가 행하는 작업에 대한 보조 작업을 수행할 수 있다.
그러면 우리가 이러한 ChatGPT와 같은 언어 모델 챗봇에게 질문을 던졌을 때, 언어 모델은 어떻게 질문에 대한 답변을 예측할 수 있을까?

1. Zero-Shot (ZS) and Few-Shot (FS) In-Context learning
1-1. Emergent abilities of large language models
Emergent Ability (창발적 능력)
: 창발적 능력이란 소규모 모델에는 없지만 대규모 모델에는 존재하는 능력이다. 대규모 모델에 많은 데이터를 투입하여 학습시킬 때, 대규모 모델이 스스로 학습하고 발전함에 따라 예상치 못하게 발생하는 새로운 능력이다. 창발적 능력을 통해 기존 설계 예상보다 더욱 높은 수준의 성능을 발휘할 수 있게 된다.
Emergent Ability of large language models
- GPT (117M parameters, 2018)
- Transformer decoder with 12 layers & Trained on BooksCorpus - over 7000 unique books (4.6GB text) : 대규모 언어 모델의 사전 훈련, downstream task에서 효율성 입증.
- GPT-2 (1.5B parameters, 2019)
- GPT에서 더욱 증가된 parameters (117M → 1.5B), 더욱 많은 internet text data에서 학습 진행. (4GB → 40GB)
Emergent zero-shot learning
: GPT-2에서 발현되는 창발적 능력 중 하나는 바로 Zero-shot learning이라고 할 수 있다. zero-shot learning은, 언어 모델에 특별한 예시 자료나, gradient의 업데이트가 필요 없이 여러 분야의 task를 수행할 수 있는 학습 능력을 말한다.
$\downarrow$ 간단한 예시

GPT-2는 zero-shot learning을 통하여, 특별한 task-specific fine-tuning 없이 출시 당시 여러 SoTA(State-of-The-Arts) 언어 모델의 성능 지표를 앞지르는 성과를 보였다.
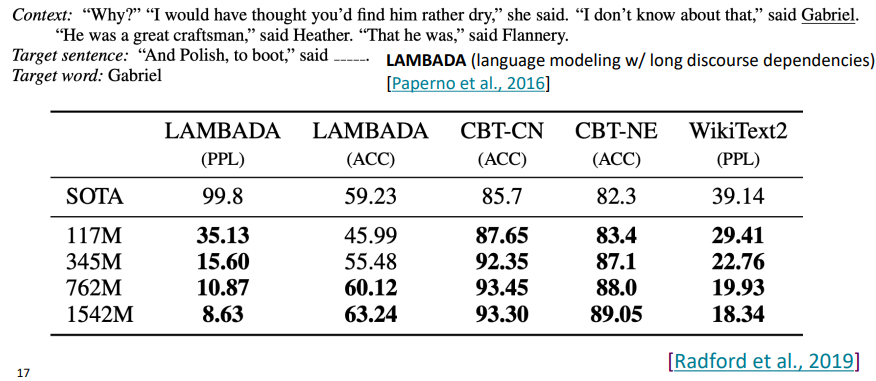
이후 시간이 지남에 따라 GPT-2에서 더 진화한 GPT-3가 발표되었다.
Emergent ability on GPT-3 (175B parameters, 2020)
- GPT-2보다 훨씬 증가한 parameters (1.5B → 175B)
- and data (40GB → over 600GB)
Emergent few-shot learning
: GPT-3에서 발현되는 창발적 능력 중 하나는 few-shot learning으로, 수행해야 하는 task를 소수의 간결한 예시를 통해 언어 모델에게 지시하는 학습 방법이다. 이것은 in-context learning이라고도 불리며, zero-shot과 같이 gradient의 업데이트가 진행되지 않는다는 장점이 있다 (계산 용이성 증가).
$\downarrow$ Few-shot learning의 예시

대표적인 언어 모델의 자연어처리 벤치마크인 SuperGLUE(General Language Understanding Evaluation)을 통해 GPT-3의 Zero-shot / One-shot / Few-shot Learning의 성능을 살펴보겠다.
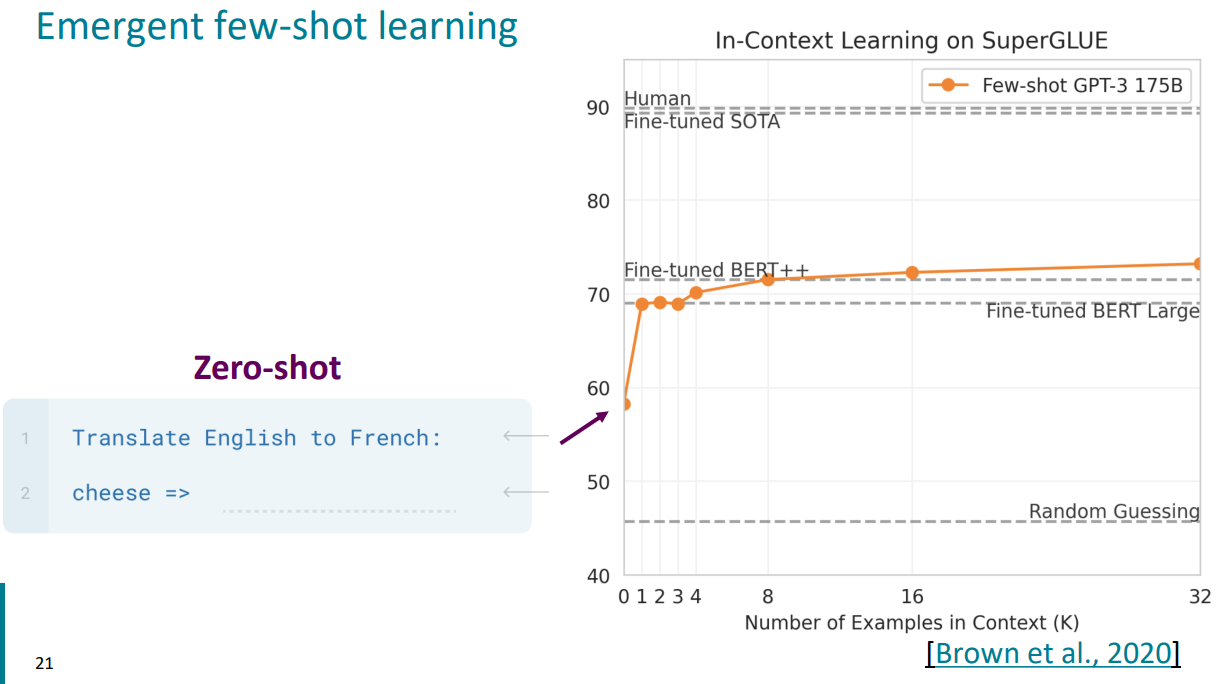
$\uparrow$ Zero-shot Learning
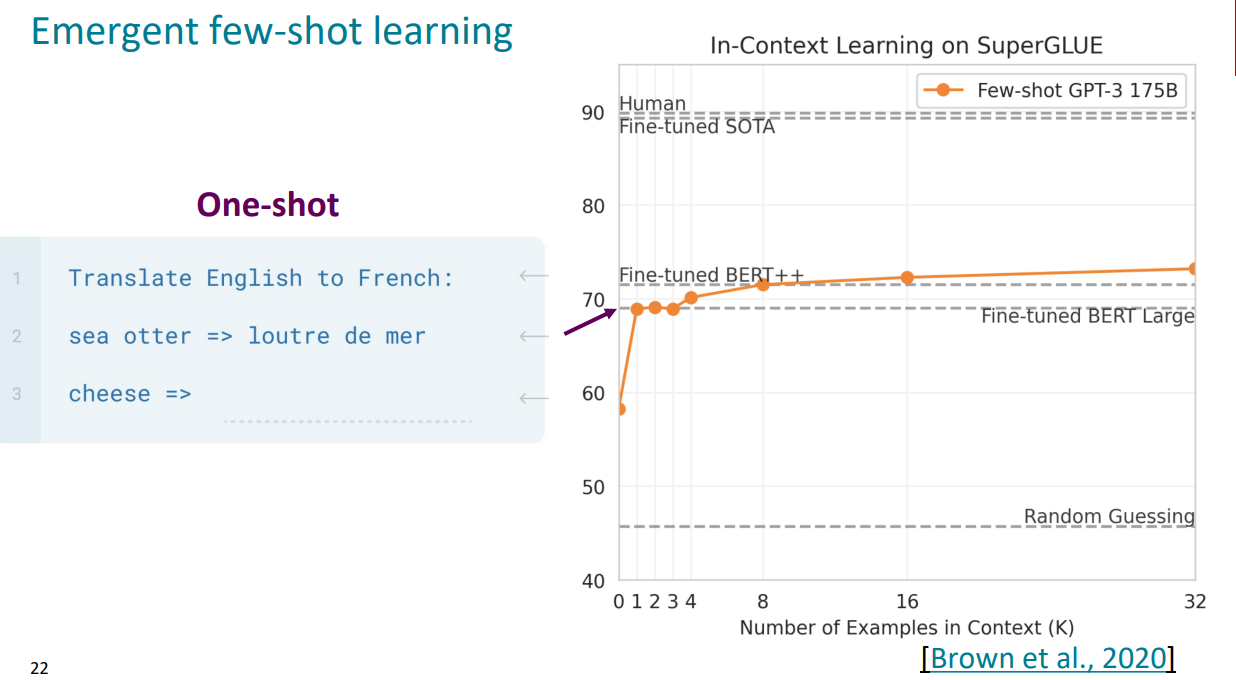
$\uparrow$ 딱 하나의 Context example을 제시하여 모델의 Output에 영향을 주는 One-shot Learning을 통해 Zero-shot보다 대략 10%정도의 성능 향상을 보인 것을 알 수 있다.
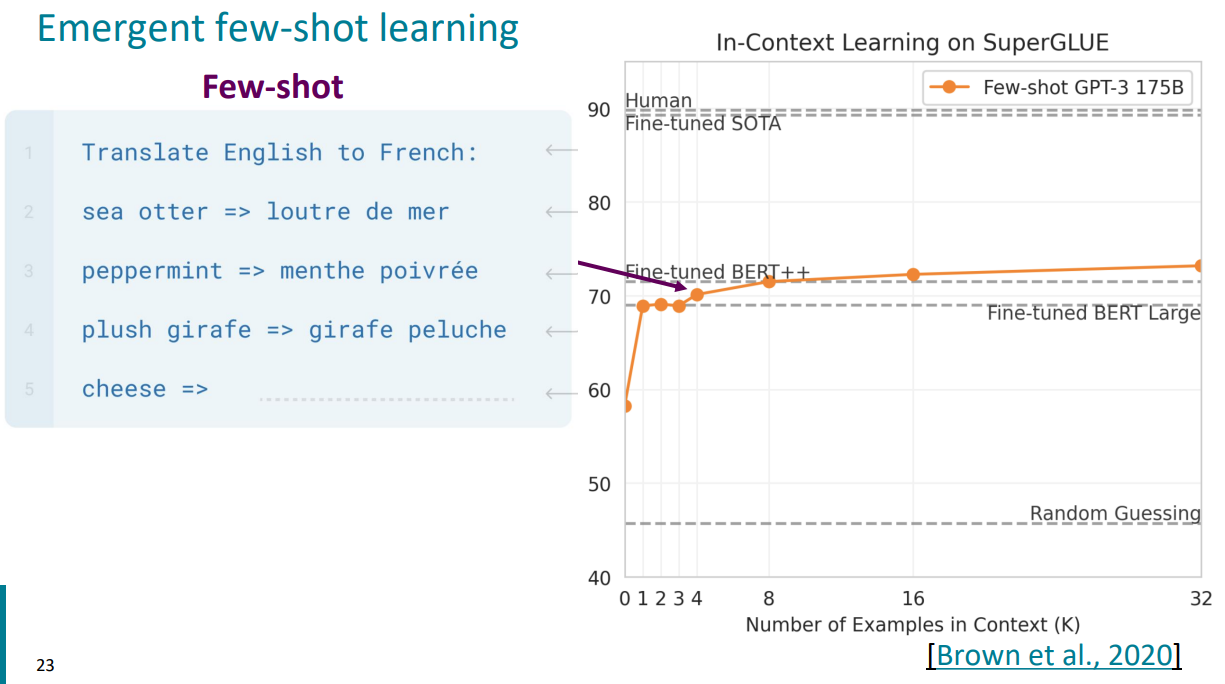
$\uparrow$ Few-shot Learning을 진행한 GPT-3를 통하여 Fine-tuned BERT와 거의 비슷한 성능을 달성한 것을 확인할 수 있다. 여기서 가장 유의할 점은, In-Context Learning은 gradient update를 진행하지 않고 이러한 성능을 달성했다는 것이다!
인터넷을 통해 쉽게 볼 수 있는 여러 Few-shot learning의 예제를 통해, 당신은 Few-shot learning이 그저 prompt를 기억(memorizing)하는 것에 불과하다고 생각할 수 있다. 그리고 그것은 사실이 맞다.
하지만, GPT-3가 Few-shot learning을 통해 즉흥적인 지적 추론을 한다는 증거가 있다. 아래의 word unscrambling에 대한 task 수행 결과가 하나의 증거이다.
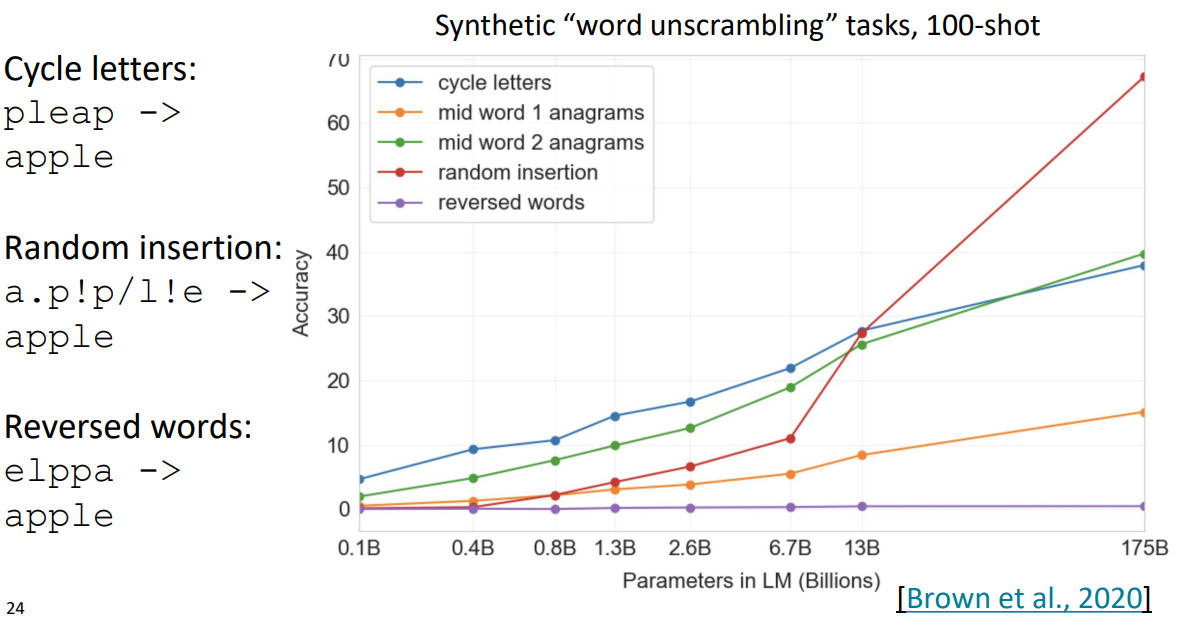
parameter의 scale이 더 큰 모델 사이즈에서 Few-shot learning을 진행하면, 모델이 수행하는 task의 ability도 증가한다는 것이다. 따라서 model의 scale이 매우 커질수록, in-context learning의 효능이 매우 좋아진다.
그래프를 살펴보면, 사실 모든 모델들이 word unscrambling을 진행했을 때의 Accuracy가 그렇게 우수하진 않다. 이런 작업은 언어 모델들이 아직 매우 고전하고 있는 task이고, 앞으로 언어 모델이 더욱 진화할수록 수행하기 쉬워질 것이라 예상된다.
New methods of “prompting” LMs
- Traditional fine-tuning
- Giving bunch of data, doing a gradient step on each example. at the and we get a model that can do well on some output.

- Zero/few-shot prompting
- Giving some examples and ask the model to predict right answer

Limits of prompting for harder tasks
- 몇 가지의 task는 아직 한 번의 prompting으로는 완벽히 수행하기 어려운 것들이 많다. 큰 수의 덧셈과 같이 많은 추론과 단계적 추론이 필요한 경우가 그 예이다. (이러한 경우는 사람도 헷갈려한다.)
- Solution : change the prompt! (프롬프트를 개선하자!)
2. Chain-of-thought prompting
Chain-of-thought prompting
Prompting을 개선하기 위하여 나온 방법 중 하나가 바로 Chain-of-thought prompting이다.

수학 문제 풀이를 예시로 들자면, 기존의 in-context prompting을 하기 위한 prompting에서는 그저 질문과 답변에 대한 예시를 알려주고 그 다음 새로운 질문을 통해 모델의 Output을 기대하는 방식이 전부였다.
이 과정에서 모델은 올바른 답을 예측하려 하지만 그 답은 많이 틀린다.

Chain-of-thought prompting에서는 질문에 대한 대답을 추론하는 과정을 모델이 완수하게끔 먼저 알려준다.
우리가 입력하는 prompt에서는 단순히 질문과 정답만을 입력하는 것이 아니라 답을 도출할 때의 단계적인 추론 과정을 추가한다. 이 과정에서 언어 모델은 우리가 추가적으로 입력한 prompt의 패턴을 따라서 output을 만들게 설계되었기 때문에, 답변으로 추론 과정과 정답을 동시에 출력하게 된다.
즉 언어 모델이 질문에 대한 답을 도출하기 위한 가이드라인을 제시하여, 가이드라인에 기반한 새로운 문제 풀이를 하도록 prompt를 설계하는 것이다.
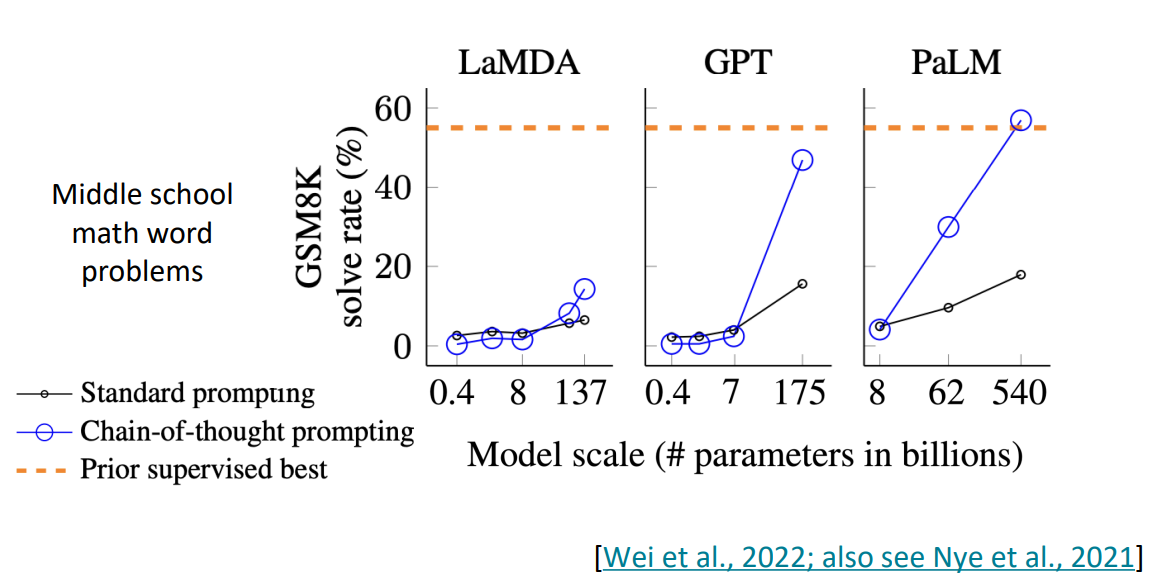
GPT를 이용해 실험을 진행한 중학교 수준의 수학 문제 풀이에서 Chain-of-thought prompting을 이용해, 기존의 standard prompting보다 매우 높은 성과를 달성한 것을 볼 수 있다.
Zero-shot Chain-of-thought prompting

기초적인 chain-of-thought에 이어 언어 모델을 학습시키기 위해 따라오는 고민거리는 다음과 같다.
- “추론의 과정을 모델에게 전달하기 위해 사람들을 모아 추론 과정의 예시를 더 만들어야 하는가?”
- “모델이 추론 과정을 알아서 잘 설명하게끔 질문 프롬프트를 잘 설계할 수 있을까?”
이러한 질문에서 나온 개념이 바로 Zero-shot chain-of-thought prompting이다.

Zero-shot chain-of-thought prompting에선 chain-of-thought처럼 추론 과정을 모델에게 설명하여 전달하는 것이 아니라, 질문을 전달한 후 답변의 첫 번째 토큰에 “Let’s think step by step”이라는 문구를 넣어 주는 것이다.
모델은 첫 번째 토큰을 decode하여 추론을 진행하고, 결국 올바른 답변을 만들어낼 수 있다.

Zero-shot, Few-shot, Zero-shot COT, Few-shot COT를 비교하여 수학 계산 벤치마킹을 계산했을 때 standard prompting보다 Chain-of-thought prompting의 성능이 훨씬 우수한 것을 알 수 있고, Zero-Shot COT도 우수한 성능을 보이며 Few-shot COT(Manual COT)가 매우 우수한 성능을 보이는 것을 알 수 있다.