XAI의 역사 & Feature Importance & Global model Interpretation
이 게시글은 ‘파이썬을 활용한 머신러닝 해석 가능성’, ‘XAI 설명 가능한 인공지능, 인공지능을 해부하다’ 두 도서의 내용을 혼합하여 정리하였습니다.
XAI의 역사 & Feature Importance & Global model Interpretation
01. XAI의 역사와 등장배경
1. 설명 가능한 의사 결정 체계
XAI는 1975년, ‘설명 가능한 의사 결정 체계’라는 용어로 처음 등장한다.
https://www.sciencedirect.com/science/article/abs/pii/0025556475900474
- 논문의 저자 - 뷰캐넌(Buchanan), 쇼트리프(Shortliffe)
의학도들의 의사 결정에 의심 생김. 당시 의사들은, 매우 적은 수의 환자를 보고 병명을 판단함. 의학 서적 및 질병 데이터의 부족 → 적은 수의 진단 경험과 이론 근거로 환자 치료.
$\therefore$ 의사들이 합리적이지 않을 가능성 다분!
통계를 이용하여, 의사들의 부정확한 추론 과정을 확률적으로 모델링하는 방법 제안.
$\hookrightarrow$ 조건부 확률 근삿값(Rule-based conditional probability approximation) 방식 개발.
2. 전문가 시스템
뷰캐넌&쇼트리프의 논문이 나오고 16년 뒤(1991), 전문가 시스템(Expert System)에서 컴퓨터의 의사 결정 과정을 드러내는 연구로 발전했다.
https://ieeexplore.ieee.org/document/87686
컴퓨터의 연산 모델 : 초기 입력 → 중간 결정 → 최종 판단 과정을 투명화하고자 함. 이를 통해 연산 모델의 합리성을 이해하고 싶었다.
3. XAI의 자리잡기
설명 가능한 인공지능은 2004년이 되어 “XAI (Explainable Artificial Intelligence)’ 라는 전문용어로 자리잡게 되었다. - 반 렌트(Michel van Lent), 피셔(William Fisher), 만쿠소(Michael Mancuso)
https://dl.acm.org/doi/abs/10.5555/1597321.1597342
$\hookrightarrow$ 컴퓨터 시스템이나 인공지능은 복잡해지는 반면, 그것들의 자기 설명 기능에는 발전이 없었다는 것을 지적.
~ 2000년대 : XAI는 매우 제한된 범위에서 사용됐다.
Why? → 계산력(Computing power)를 비롯한 물리적 제약 조건 때문. 우선 문제 해결 자체가 먼저, 해결 과정에 대한 설명은 차후 논의해야 함. 그저 논문속의 이야기였다.
오늘날에는 머신러닝 기술 & 하드웨어 성능이 급속도로 좋아지고 있음. 인공지능의 유용성이 증가. 인공지능이 푸는 문제들의 필요성과 달리, 인공지능 모델의 설명 능력의 진척이 매우 더뎠다.
$\therefore$ 연구자들은 설명 가능한 인공지능을 하나의 체계로 정리할 필요를 느꼈다.
4. 머신러닝에서의 XAI
- XAI란?
인공지능 모델이 특정 결론을 내리기까지 어떤 근거로 의사 결정을 내렸는지를 알 수 있게 설명 가능성을 추가하는 기법이다. 즉, 인공지능에 설명 능력을 부여해 기계와 인간의 상호작용에 합리성을 확보하는 것.
관련 논문 : https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2972855
기계가 학습하는 데이터의 양 → 사람이 해석 불가능할 만큼 많아짐. 머신러닝 모델의 의사 결정 분기점도 기하급수적으로 증가함.
$\hookrightarrow$ 위와 같은 머신러닝 모델의 복잡성을 해소하기 위해, XAI가 등장. XAI를 통해 시스템의 출력 결과를 신뢰할 수 있고, 다음 의사 결정을 위해 인공지능을 적극 사용할 수 있다. 이러한 의미에서 XAI를 해석 가능한 인공지능(Interpretable AI), 투명한 인공지능(Transparent AI)라고도 부른다.
02. Feature importance
2-0. Introduction
1부에서는 머신러닝 해석의 개념, 과제 목적등을 소개함. 4장부터는 모델을 진단하고 모델의 근간이 되는 데이터를 이해하기 위해 사용되는 다양한 방법론을 살펴보는 부분의 시작이다.
해석 방법론이 답해줄 수 있는 큰 하나의 질문 → “모델에 가장 중요한 feature는 무엇이며 어떻게 중요한가?”
전반적인 중요도와 피처가 개별적으로 또는 서로 결합돼 모델의 결과에 미치는 영향력 밝히기!
순열 피처 중요도(Permutation Feature Importance, PFI) → 직관적이고 신뢰성 있게 피처의 순위 추출
부분 의존도 플롯(Partial Dependence Plots, PDP) → 예측에 대한 단일 피처의 한계 효과 이해
2-1. 미션
고정관념
- 첫째 아이는 책임감이 강하고 권위적이다.
- 둘째/중간 아이는 질투심이 있고 내성적이다.
- 막내는 버릇이 없고 근심 걱정이 없다.
심리학자들의 데이터과학 컨설팅 → 출생 순서가 성격에 미치는 영향. 소규모 경험적 연구에서 비롯
더 체계화되고, 데이터에 기반한 평가가 필요함.
‘Psychometrics Project’를 통해 40,000개 이상의 온라인 설문 데이터셋 확보.
알고자 하는 것 :
설문의 답과 출생 순서 사이의 관계 / 경험적 연구에 사용할 질문이 있는지 / 온라인 설문이 처음부터 신뢰할 수 있는 방법인지
→ 머신러닝에 정통한 제3자가 새로운 시각으로 문제에 접근할 필요 존재.
2-1-1. 성격과 출생 순서
한 세기 동안, 출생 순서에 따른 양육방식 → 성격 특성에 영향 어떻게 미치는 지에 대한 연구가 활발히 진행됨.
대부분의 이론이 서구 문화권 국가에서 진행됨. → 첫째 : 높은 지능, 막내 : 질투
좀 더 Advanced한 연구 → 성별, 나이차이, 사회 경제적 상태 등을 성격 차이의 요인으로 고려.
But.
이론 간 널리 합의된 경우가 없다. 문화권의 양육 방식의 차이도 존재하므로, 서구 문화권의 이론은 다른 지역에선 통하지 않는다.
개인을 개별 범주와 척도로 그룹화하기 위한 설문지를 사용해 성격을 평가하는 심리 측정 방법론 - IPIP(International Personality Item Pool)의 “빅 5(Big Five)” 테스트에 대한 답변 포함.
그 안에서 출생 순서와 관련된 특성을 위해, 특별히 설계된 26개의 질문 포함.
이 중에서 세 가지 범수에 집중.
- 첫째 아이 : 참가자는 둘 이상의 자녀 중 첫째다.
- 둘째 아이 : 참가자는 둘 이상의 자녀 중 첫째도 막내도 아니다.
- 막내 아이 : 참가자는 둘 이상의 자녀 중 막내다.
질문이 영어로 되어 있음. → 특히 영어를 주로 사용하는 국가에 집중. 질문의 문화적 편향 가능성 존재.
2-2. 접근법
설문 답변 / 기술적&인구통계학적 정보 중 어떤 feature가 출생 순서에 가장 영향을 미치는지, 그리고 이런 목적을 위해 사용할 수 있는지 여부 찾기.
→ 출생 순서를 예측하는 분류 모델을 생성한 후, 다음과 같은 task 수행.
- 모델의 고유 매개변수 사용, 모델에 가장 큰 영향을 갖는 feature 찾기 (feature importance → 모듈러 해석 방법론)
- 순열 피처 중요도(PFI)라는 보다 신뢰성있는 순열 기반 방법론 사용 → feature importance 탐색.
- ICE plot 사용 → 개별 feature가 모델의 예측에 미치는 영향을 좀더 세분화하여 시각화.
2-3. 준비
https://www.kaggle.com/datasets/lucasgreenwell/firstborn-personality-scale-responses/data

2-3-1. 데이터 딕셔너리
심리적 질문 76개, 인구통계학적 feature 6개, 기술적 feature 5개
심리적 질문
- Q1, Q2, … , Q26 : 서수형. 출생 순서 연구의 26개 질문에 대한 답변. 1=비동의, ~3=중립, ~5=동의, 0=무응답까지의 5점 리커트 척도(Likert scale) 기반
- EXT1, EXT2, … , EXT10; EST1, EST2, … , EST10; AGR1, AGR2, … , AGR10; CSN1, CSN2, … , CSN10; OPN1, OPN2, … , OPN10 : 서수형. IPIP “BIG 5” 설문지. 50개의 질문으로 구성. 1= 비동의, ~3=동의, ~5=동의, 0=무응답까지의 5점 리커트 척도
인구통계학적 feature
- age : 참가자의 연 나이
- engnat : 이진 값. 영어가 모국어인지 여부. 1=예, 2=아니요
- gender : 범주형, 성별. 남성, 여성, 기타, 정의되지 않음.
- birthn : 서수형. 부모가 낳은 총 자녀 수. 1~10, 11=기타
- country : 범주형. 참가자의 국가. 2자리 코드
- birthorder : 서수형. 목표변수인 출생 순서. 1:첫째, 2:중간, 3:막내
기술적 feature
- source : 범주형. 사용자가 HTTP 기반으로 성격 테스트에 도달한 방법. 1=구글에서 직접, 2=웹사이트 첫 페이지, 3=기타
- screensize : 서수형. 테스트에 사용된 화면 크기. 2=600픽셀 이상, 1=그보다 작음
- introelapse : 연속형. 성격 테스트 랜딩 페이지에서 보낸 시간(초)
- testelapse : 연속형. 성격 테스트 본문에 소요된 시간(초)
- endelapse : 연속형. 성격 테스트 종료 페이지에서 보낸 시간(초)
2-4. 결과에 대한 피처의 영향력 측정
모델 : 의사 결정 트리, 그레디언트 부스트 트리, 랜덤 포레스트, 로지스틱 회귀, 다층 퍼셉트론, 선형 판별 분석(Linear Discriminant Analysis, LDA) 등의 여섯 가지 모델 활용.
$\downarrow$ 모델 성능표

test data에 대한 전체적인 모델들의 정확도가 만족스럽진 않다. 정확도를 올바르게 해석하려면 널 오류율(Null Error Rate)라고도 하는 NIR(No Information Rate)를 살펴봐야 함.
NIR(No Information Rate) = 다수 클래스의 관측치 수 / 총 관측의 수
Ex ) 이미지 분류 문제 - 개 85%, 고양이 15%로 구성일 때, 개는 다수의 클래스이다.
여기서 어떤 게으른 분류기가 모든 이미지를 개라고 예측할 때, 이 분류기는 85%의 정확도 달성.
→ NIR : 모든 관측치가 다수 클래스에 속한다고 예측했을 때 얻을 수 있는 정확도.
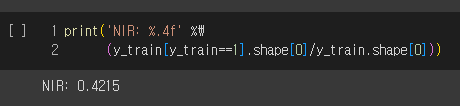
우리의 모델들은 이 게으른 분류기보다 더 높은 성능을 기록해야 한다!
변인 : 데이터의 품질, 가설의 타당성, 모델의 복잡성, 정규화 방법, 피처 선택 등
- 이 챕터에서의 목표
변수들 사이의 잠재적인 관계를 발굴하는 모델의 능력을 활용 → 설문 답변과 출생 순서 사이의 점들을 연결!
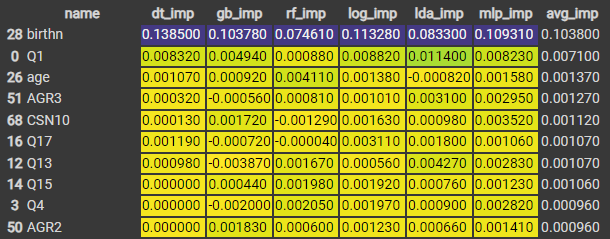
2-4-1. 트리 기반 모델의 feature 중요도
트리 기반 모델의 feature importance 계산 → 각 노드에 대한 불순도 감소의 가중치 합을 사용.
- 노드 불순도(Impurity) : 한 노드 안에 서로 다른 feature가 얼마나 섞여 있는가? 다양한 feature가 있을수록 불순도는 높아짐.
$\downarrow$ 의사결정트리(dt_rank), 그레디언트 부스트 트리(gb_rank), 랜덤포레스트(rf_rank)의 feature importance
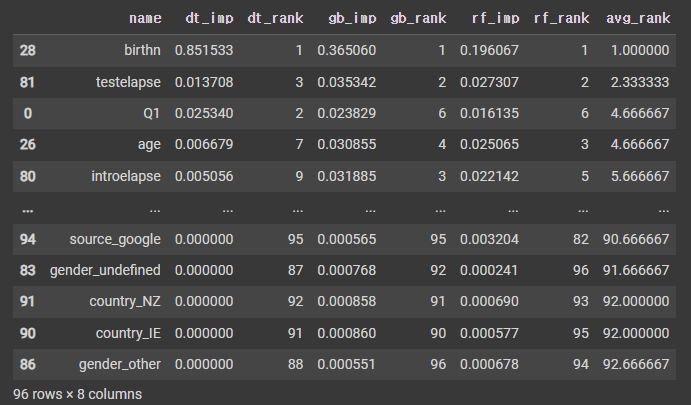
세 모델의 feature importance 순서의 추세가 비슷한 것을 알 수 있음.
트리 기반 모델의 feature importance 측정 방법의 특징 : 모델 종속적, 불순도 기반.
→ 불순도는 더 높은 Cardinality(서로 다른 원소 수가 많은 것)의 feature에 편향되므로, 데이터의 분포에 robust하지 않을 수 있다.
2-4-2. 로지스틱 회귀의 feature 중요도
- 학습을 통해 적합한 회귀 계수의 크기 비교
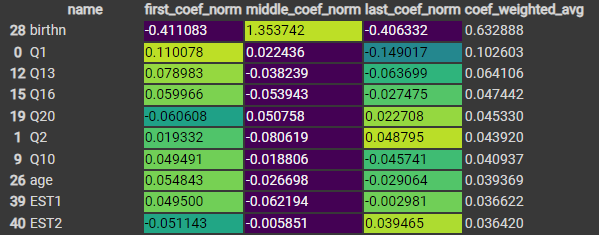
멀티클래스에 대해 One vs Rest (첫째, 둘째, 막내)를 통해 세 번의 계수 계산 진행.
→ 최종적으로 각 feature마다 세 계수의 평균을 내어 순위 결정
데이터가 정규화되지 않았으므로, 각 계수의 크기 범위가 다르다. 따라서 계수의 정규화 진행
2-4-3. LDA의 feature 중요도
- 학습을 통해 적합한 회귀 계수의 크기 비교
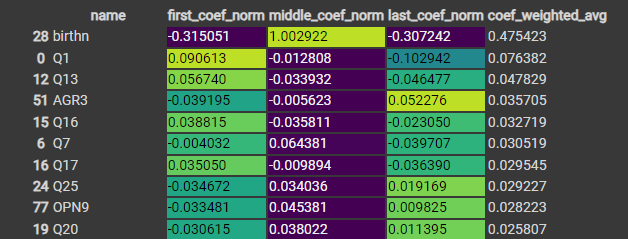
LDA 또한 각 feature마다 세 계수의 평균 계산.
2-4-4. 다층 퍼셉트론의 feature 중요도
- feature 중요도를 쉽게 결정하는 데 도움이 되는 고유한 속성 X.
2-5. PFI
모델 종속적 feature importance 측정보다 훨씬 설명하기 쉬움.
각 feature의 값을 뒤섞었을 때 예측오차의 증가를 측정하는 방법.
feature가 목표변수와 관계가 있는 경우, 셔플링은 이 관계를 방해하고 오차를 증가시킨다는 논리 기반. → 셔플링을 한 후에 오차가 가장 많이 증가하는 것 기반으로 feature 순위 정하면, 어떤 feature가 모델에 중요한 지 알 수 있다!
2-5-1. PFI의 장점
모델 독립적인 방법 + 훈련 시 보지 못한 Test dataset과 함께 사용 가능.
2-5-2. PFI의 단점
서로 상관관계를 갖는 feature의 관계를 파악하지 못 함.
→ 다중공선성이 feature importance를 능가한다.
2-6. PDP(Partial Dependence Plot)
2-6-1. PDP란?
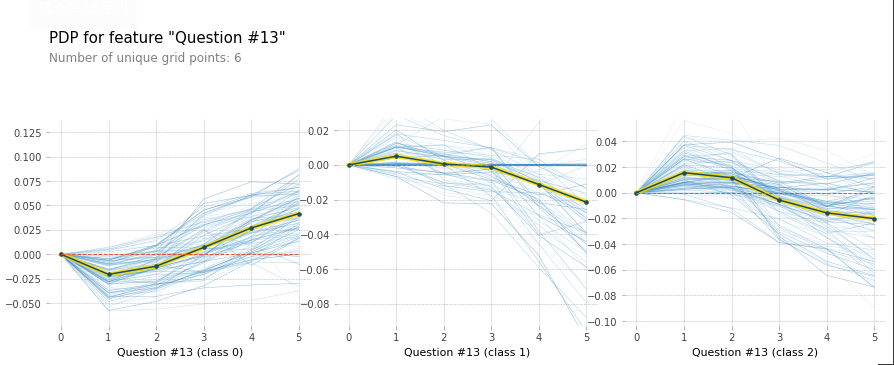
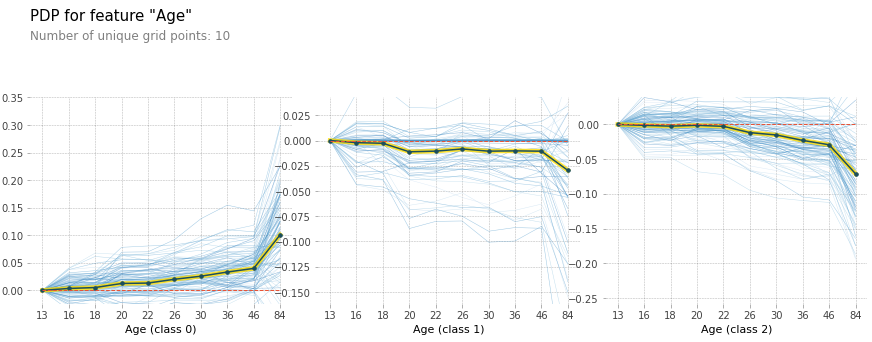
: 모델의 예측 결과에 대해, 한 개 도는 두개의 feature와의 관계를 보여주는 그래프이다. feature의 한계 효과를 보여주며, 이는 feature의 영향과 목표변수와의 관계를 선형, 지수, 단조 등의 특성으로 시각화할 수 있는 글로벌 모델 해석 방법론이다.
$\downarrow$ 논문 링크(2001)
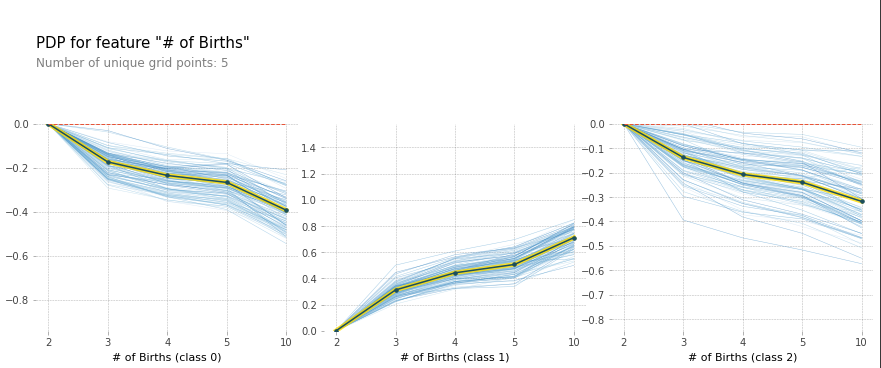
- birthn에 대한 PDP
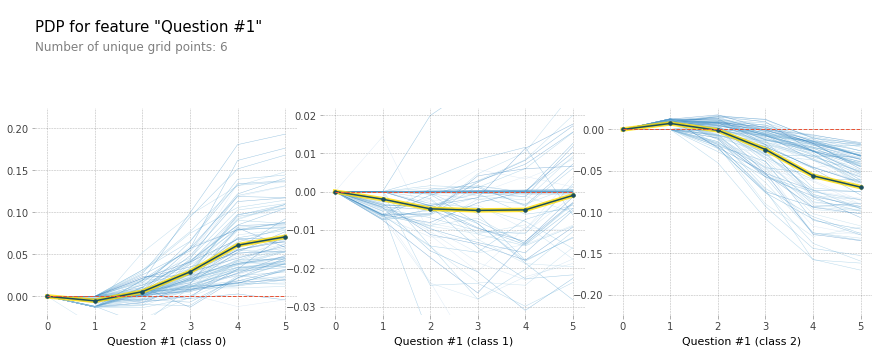
- Q1에 대한 PDP
- Q13에 대한 PDP
- age에 대한 PDP
2-6-2. 상호 작용 PDP
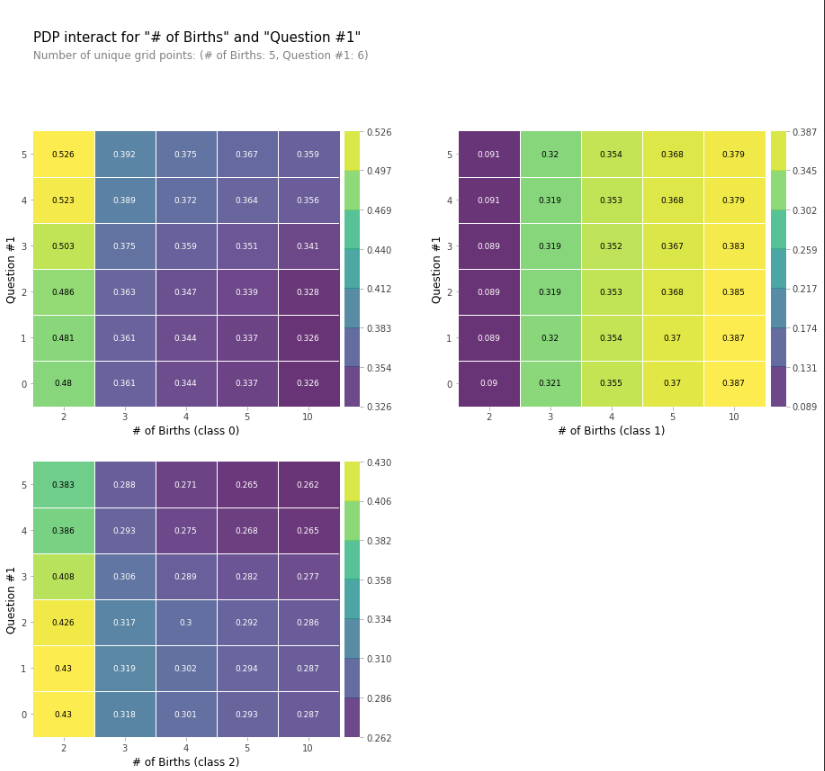
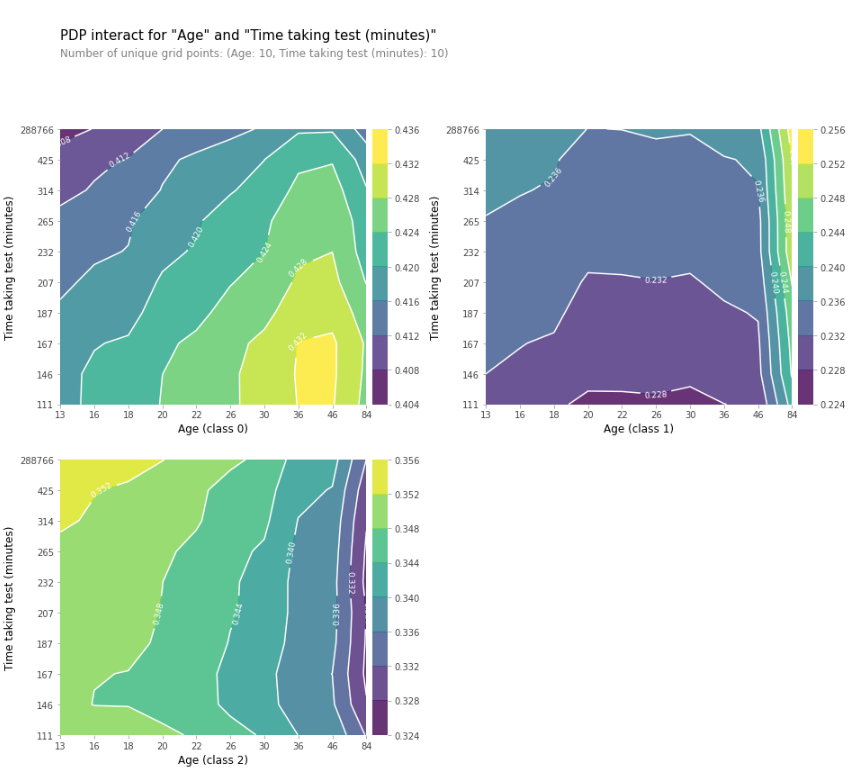
PDP는 한 번에 여러 feature에 적용할 수 있으며, 이는 두 feature의 상호 작용이 목표 변수와 어떤 방식으로 관련되는 지 조사하는 데 유용하다.
- 자녀 수 ↔ Q#1 간의 PDP 상호 작용
- 나이 ↔ 테스트에 걸린 시간(초) PDP 상호 작용 등고선그래프
2-6-3. PDP의 단점
- 한 번에 최대 두 개의 feature만 표시 가능
- feature들의 독립성을 가정하고 진행 → 누적 지역 효과 플롯(Accumulated Local Effect, ALE), 5장
- 평균적으로 feature와 목표변수의 연관성을 설명함. → 평균이 아닌 개별 관측치에 대한 시각화 불가능 → ICE Plot
2-7. ICE(Individual Conditional Expectation) Plot
2-7-1. PDP Plot과의 차이
PDP Plot을 이용할 경우, feature와 목표변수 간의 분산을 무시해버릴 수 있음. (평균을 이용하기 때문)
ICE Plot은 평균보단 각 목표 변수의 인스턴스마다의 관측을 진행하여 설명을 진행하고자 함.
PDP Plot으로 나타낸 feature와 목표변수간의 관계를 목표 변수의 개별 관측치(인스턴스) 별로 보고싶다.
$\hookrightarrow$ ICE의 평균을 낸 Plot이 Partial Dependence Plot !
- ICE Plot의 단점
: ICE Plot에는 모든 데이터셋이 포함될 수 있지만 Plot에 선이 많으면 계산 비용이 많이 들고, 더 중요한 것이 무엇인지 제대로 인식하기 어려울 수 있다.
birthn 증가에 따라 데이터포인트가 첫째일 확률, Q1 답변에 따라 색상 구분
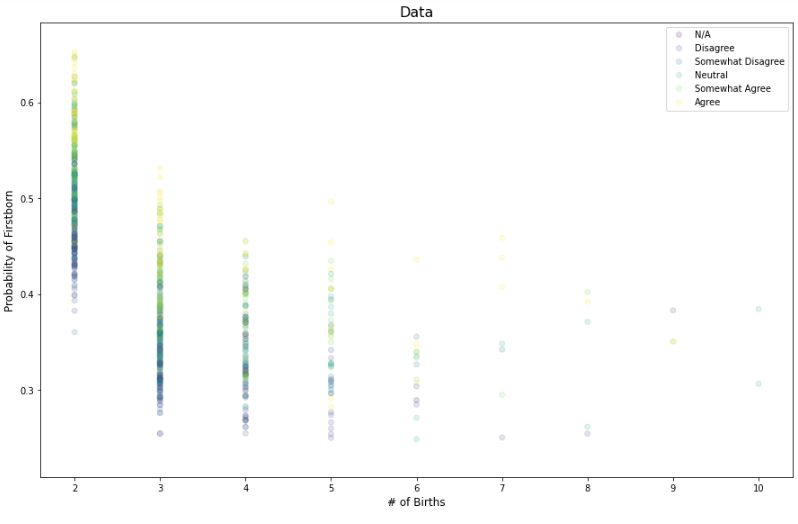
birthn 증가에 따른 첫째 아이 ICE Plot ,Q1 답변에 따라 색상 구분
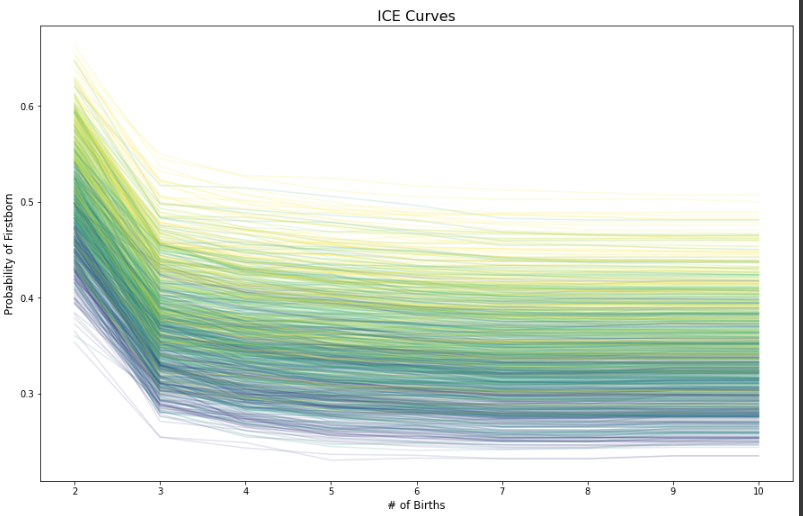
birthn 증가에 따른 중간 아이 ICE Plot, Q1 답변에 따라 색상 구분
2-7-2. ICE의 단점
- PDP와 마찬가지로 feature의 독립성을 가정하고 진행
- 개별로 보기 때문에, 두 개의 연속형 feature 또는 cardinality가 높은 feature의 상호작용 관찰 불가
- feature와 목표변수 사이의 평균 관계 확인이 어려움 → PDP Plot으로 가능
2-8. 미션 완료
- 미션
40,000개의 설문 데이터셋에서 머신러닝이 무엇을 발견할 수 있는지 결정하는 것.
- 해당 설문 데이터셋을 사용하는 것이 신뢰할 만 한가?
- 머신러닝 해석이 결과에 가장 큰 영향을 미치는 feature와, feature의 값을 보여줄 수 있는 지
PDP에서, 중간 아이의 비율이 나이와 함께 증가해야 하기 때문에 나이 분포와 출생 순서 사이에 약간의 불일치 발견. 모델링이 실제 시나리오에서 작동하려면, 학습 데이터는 실세계의 분포와 일치해야 한다.
$\hookrightarrow$ 더 큰 데이터 사용 필요.
3. Global model Interpretation
3-0. Introduction
4장에서, 모델 고유의 매개변수보다 순열 피처 중요도가 모델 결과에 미치는 영향력 순의를 정하는 데 좋다는 것을 알았다.
부분 의존도 플롯(PDP), 개별 조건부 기대치(ICE) 플롯
→ 매우 인기가 있음에도, 공선성을 갖는 feature에 민감하다.
견고한 통계를 기반으로, 다중공선성의 영향을 대부분 완화하도록 설계된 글로벌 모델 독립적 방법론
- SHAP(SHapley Additive exPlanations)
- 연합 게임 이론에서 파생된 섀플리 값(Shapley value)의 수학적 원리를 따름
- 누적 지역 효과(Accumulated Local Effects, ALE)
- 조건부 주변 분포를 사용해 PDP보다 나은 대안 제공
- 글로벌 대체 모델(Global Surrogates)
- 화이트박스 모델을 사용해 블랙박스 모델을 근사하는 방법
3-1. 미션
지구 환경 문제로 인한 자동차의 에너지 효율성 관심도 증가.
자동차 모델의 연비(Miles Per Gallon, MPG == 갤런당 마일) ↔ 소비자 구매 상관관계 존재.
$\therefore$ 다양한 변수가 MPG에 어떤 영향을 미치는지 설명. 가장 중요한 연비 예측변수를 찾아 사람이 해석할 수 있는 방식으로 설명하고자 함. (예측 변수 → 연비 ↔ 소비자)
3-2. 접근법
Dataset : 차량 모델 정보, 엔진, 오염 물질, 구동계, 섀시, 기술 관련 정보
- 모든 feature가 null이 없이 모두 숫자를 갖도록 준비한다.
- 블랙박스 모델을 사용해 이 피처로 MPG를 잘 예측할 수 있는지 확인한다. 이 예제에선 신경망과 XGBoost를 사용한다.
- Test dataset을 평가해 과적합되지 않았는지 확인한다.
- SHAP를 사용해 모델이 어떻게 결론에 도달했는지 이해한다.
- 이변량 연관성을 추가로 조사하고 잘못된 상관관계와 시스템적인 평향을 제거하기 우해 몇 가지 통계 검정을 수행한다.
- ALE Plot으로 모델에 대한 피처의 효과를 탐색한다.
- 글로벌 대체 모델을 사용해 모델의 기본 규칙을 더 자세히 이해한다.
3-3. 준비
**라이브러리**
- mldatasets : 데이터셋 로드
- pandas, numpy : 데이터 조작
- sklearn, tensorflow, xgboost, rulefit : 데이터 분할 및 모델 적합
- scipy : 통계 검정 수행
- matplotlib, seaborn, shap, alepython : 해석을 시각화
3-3-1. 데이터 딕셔너리
일반 범주 3개, 엔진 6개, 오염 물질 3개, 구동계 3개, 섀시 7개, 전자계 2개, 목표 feature 1개
일반 범주 feature
- make : 범주형 - 차량의 브랜드 또는 제조업체. 약 140개
- model : 범주형 - 차량의 모델. 약 4,000개 이상
- year : 서수형 - 모델 연식. 1984~2021
엔진 feature
- fuelType : 범주형 - 엔진에서 사용하는 기본 연료 유형
- cylinders : 서수형 - 엔진의 실린더 수. 2~16. 일반적으로 실린더가 많을수록 마력이 높아진다.
- disple : 연속형 - 엔진 배기량. 0.6~8.4 리터
- eng_dcsr : 텍스트 - 하나 이상의 코드가 연결된 엔진에 대한 설명.
- phevBlended : 이진값 - PHEV는 Plug-In-Hybrid Vehicle의 약자이며 Blendid는 차량이 배터리로 구동되고 연료는 보조임을 의미한다. 이 값이 참이면 충전 소진 모드를 사용한다.
- atvType : 범주형 - 엔진에서 사용하는 대체 연료의 유형 또는 기술. 8종류
오염 물질 관련 feature
- co2TailpipeGpm : 연속형 - CO2 배출량. 그램/마일
- co2 : 연속형 - CO2 배출량. 그램/마일. 2013년 이후 모델의 경우 EPA 테스트를 기반으로 한다. 그 이전 연도의 경우 CO2는 EPA 배출 계수를 사용해 추정된다. -1=사용 불가
- ghgScore : 서수형 - EPA GHG 점수. 0~10. -1=사용 불가
구동계 feature
- drive : 범주형 - 차량의 구동축 유형. 7종류
- trany : 범주형 - 대부분 “{type}, {speed}-spd” 형식의 변속기 설명. 여기서 type은 Manual 또는 Automatic만 가능
- trans_dscr : 텍스트 - 하나 이상의 코드가 연결된 변속기에 대한 설명.
섀시 feature
- Vlcass : 범주형 - 차량 유형. 34종류
- pv4 : 연속형 - 4도어 실내 부피. 입방 피트
- lv4 : 연속형 - 4도어 트렁크 부피. 입방 피트
- pv2 : 연속형 - 2도어 실내 부피. 입방 피트
- lv2 : 연속형 - 2도어 트렁크 부피. 입방 피트
- hpv : 연속형 - 해치백 실내 부피. 입방 피트
- hlv : 연속형 - 해치백 트렁크 부피. 입방 피트
전자계 feature
- startStop : 범주형 - 정차시 엔진을 자동으로 끄는 시작/정지 기술 포함 여부. Y=예, N=아니요, 공백=구형 차량
- tCharger : 범주형 - 터보 차저 포함 여부. T=예, 공백=그 외
목표 feature
- comb08 : 연속형 - 결합 MPG. 전기 및 CNG 차량의 경우 이 수치는 MPGe(갤런당 가솔린 등가 마일)이다.
3-4. 모델링 및 성능평가
3-4-1. 심층 신경망(Deep Neural Network)
Neural Network 구성
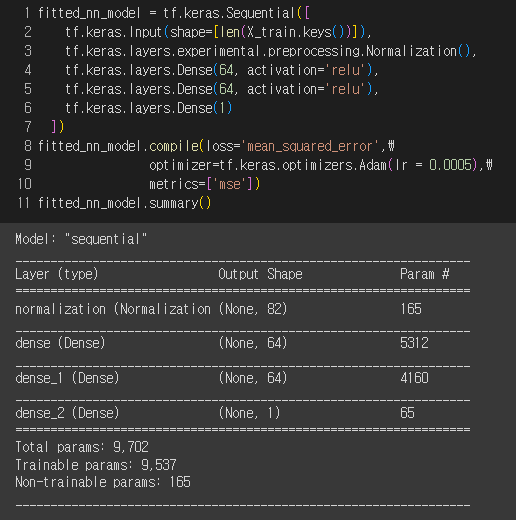
모델 성능
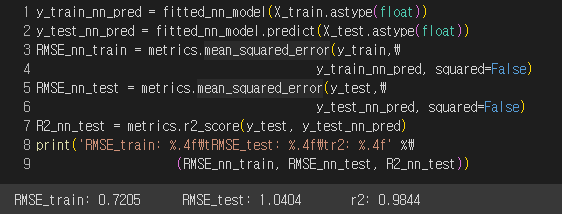
성능 매우 우수 !
- 모델 적합도 시각화
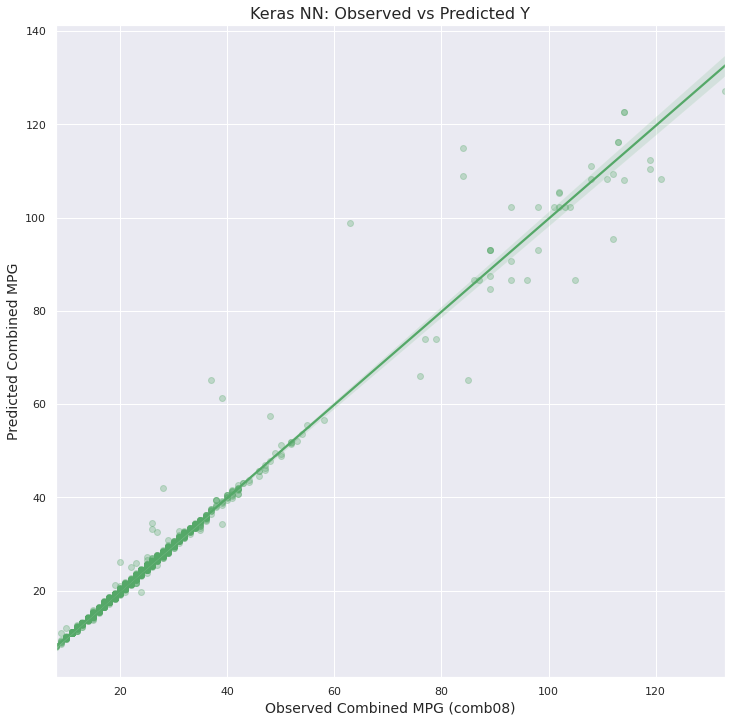
적합도 매우 Good
3-4-2. XGBoost
- 모델 성능
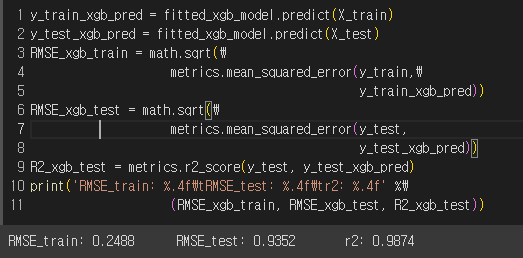
Feature importance for XGBoost
XGBoost는 feature importance를 계산하기 위해 feature가 트리에 나타내는 빈도(weight), feature로 인한 평균 오차 감소량(gain), feature로 인한 분할에 의해 영향을 받는 관측치의 수(cover)라는 세 가지 알고리즘을 사용한다.
아래는 weight를 이용한 feature importance
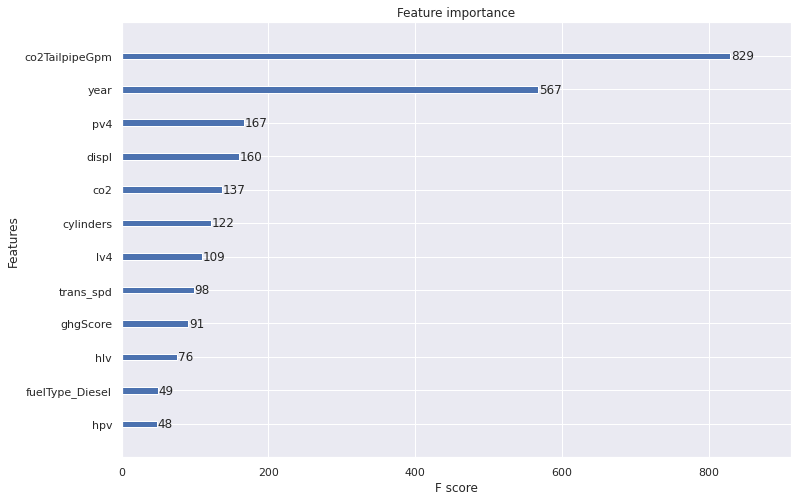
- weight, gain, cover 중 어떤 방법을 택해야 할까?
→ 이 모든 방법에 대한 상위 feature를 고려하면 공통된 feature를 찾을 수 있으며, 이런 feature가 모델에서 진정으로 가장 큰 차이를 만드는 feature를 나타낼 가능성이 높다.
3-5. Shapley Value
3-5-1. Shapley Value 소개
Ex ) 농구 경기 관람
- 조건 : 눈을 가리고, 팀 선수가 입/퇴장, 득점할 경우 확성기가 알려줌.
확성기가 없으면 누가 득점했는지, 누가 도움을 줬는지 알 수 없다.
선수들은 번호로만 지칭되고 관람자는 누가 누군지 모름. 최선의 추측 : 마지막으로 합류한 사람이 좋든 나쁘든 최근 결과와 관련이 있지 않을까?
시간이 지남에 따라, 어떤 선수가 더 나은 결과와 가장 상관관계가 있고 어떤 선수가 반대 효과가 있거나 전혀 없는지 파악해야 한다.
여러 번의 경기에서 다른 순서로 입장하는 선수들의 가능한 모든 조합 & 각 선수가 참가할 때 모든 점수 차이를 평균할 수 있다면 어떨까? → 가장 가치 있는 선수 판별
연합 게임 이론
$\hookrightarrow$ 선수의 다양한 조합 : 연합(coalition), 점수 차이 : 한계 기여도(marginal contribution)
Shapley Value(섀플리 값) : 많은 시뮬레이션에서 기여도의 평균
모델의 경우 - feature : 선수, feature들의 조합 : 선수들의 연합(coalition), 예측 오차의 차이 : 한계 기여도, black-box model : 눈을 감고있는 것
3-5-2. SHAP 요약 및 의존도 플롯 해석
- 학습 데이터에 대한 XGBoost 모델의 SHAP 요약 플롯
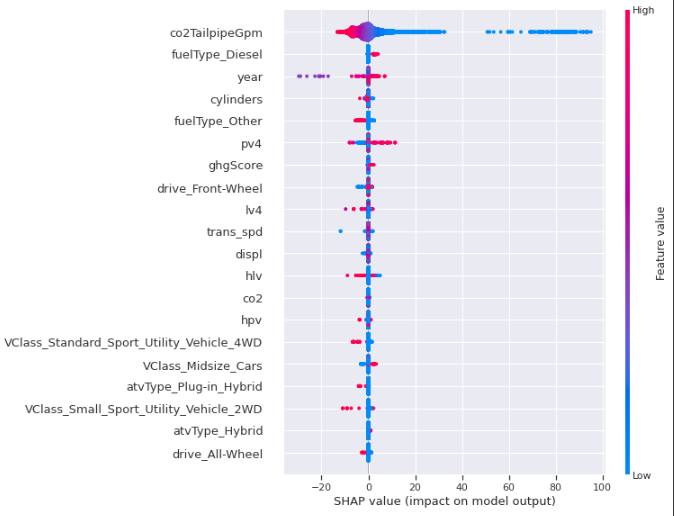
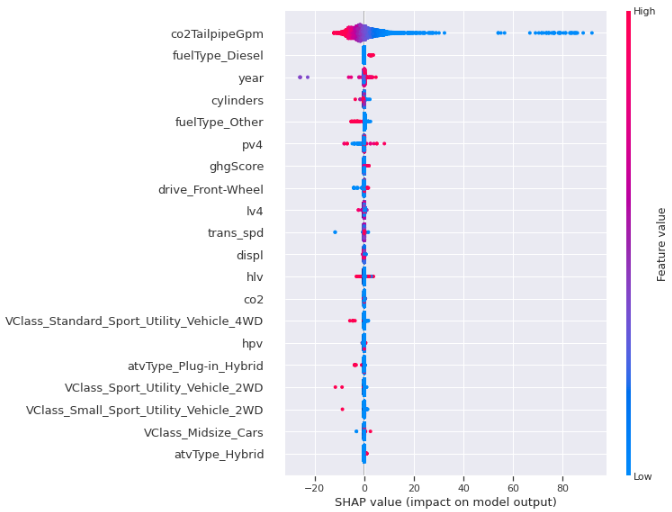
- 테스트 데이터에 대한 XGBoost 모델의 SHAP 요약 플롯
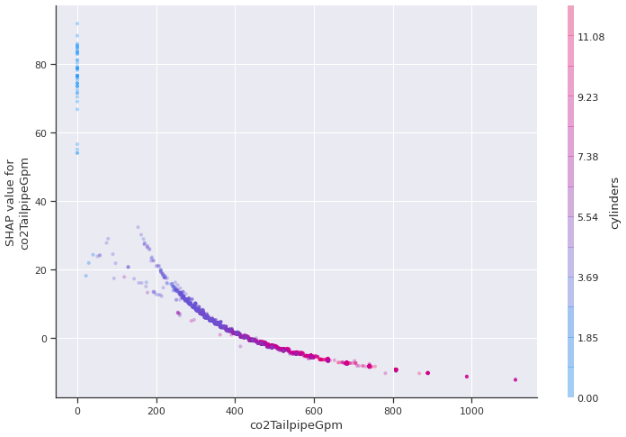
- cylinders와 co2TailpipeGpm의 상호 작용을 나타내는 XGBoost 모델 및 통계치에 대한 SHAP 의존도 플롯
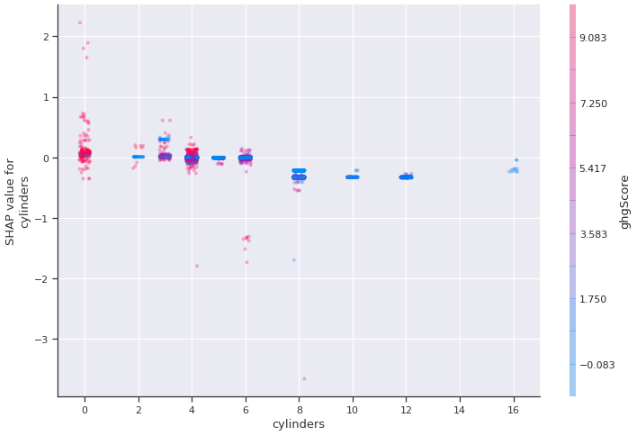
- ghgScore와 cylinder의 상호 작용을 나타내는 XGBoost 모델 및 통계치에 대한 SHAP 플롯
3-5-3. SHAP 영향력 플롯
모델이 .단일 예측을 설명할 때, 영향력 플롯(force plot)을 사용한다.
→ 연속체로 표현되며, 파란색 feature는 예측을 음의 방향으로 미는 힘, 빨간색 feature는 예측을 양의 방향으로 미는 힘을 나타냄.
- co2TailpipeGpm에 대한 효과를 표현하는 SHAP 영향력 플롯(유사도에 따라 feature 클러스터링)
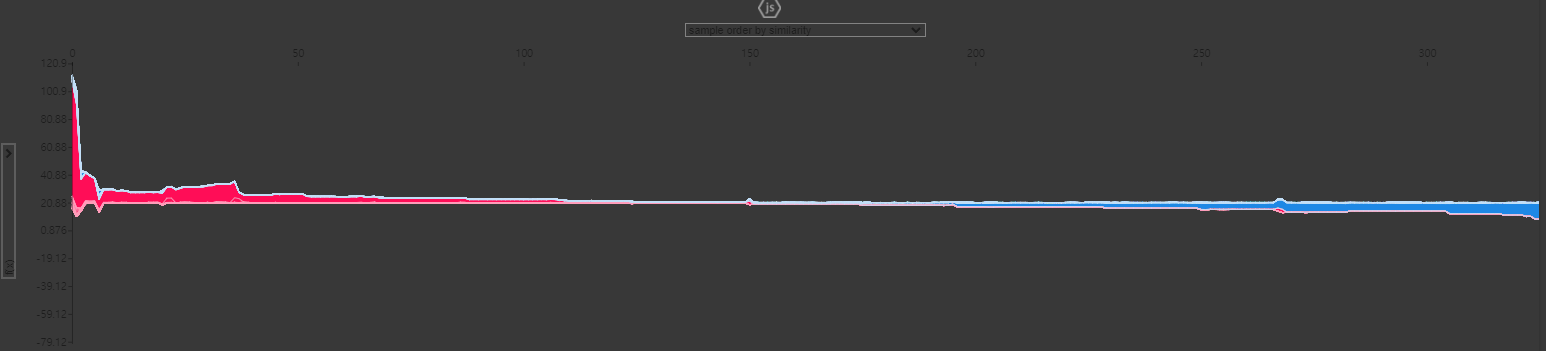
3-6. 누적 지역 효과 플롯(Accumulated Local Effects Plot)
feature의 값이 머신러닝 모델의 예측에 평균적으로 얼마나 영향을 미쳤는지 설명함. → PDP와 유사.
- ALE Plot 순서
- feature의 효과를 계산할 때 feature를 동일한 크기의 간격(분위수)로 분할해 계산 수행.
- 그 다음 각 구간에서 예측이 평균적으로 얼마나 변화되는지 계산한다.
- 모든 구간에 대한 효과를 합산하여 누적한다.
- PDP와의 차이점
: 각 feature들의 독립성 전제 X. 강한 상관관계를 가지더라도 편향되지 않는다.
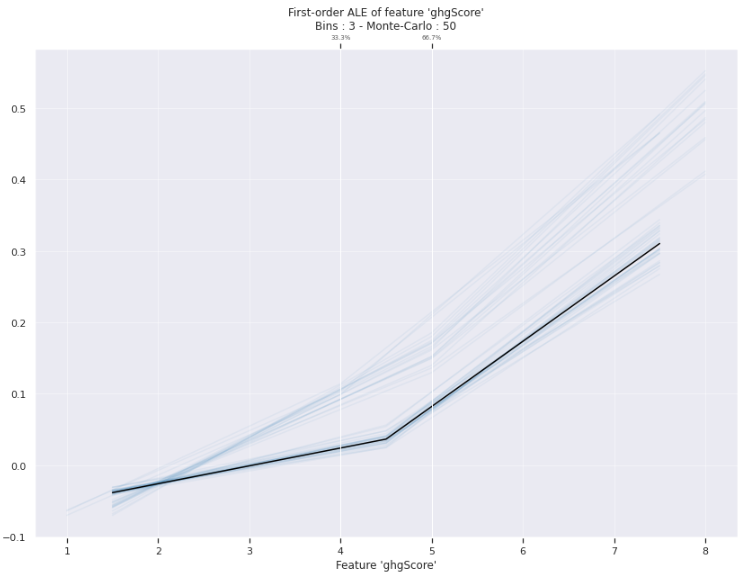
- ghgScore feature의 1차 ALE
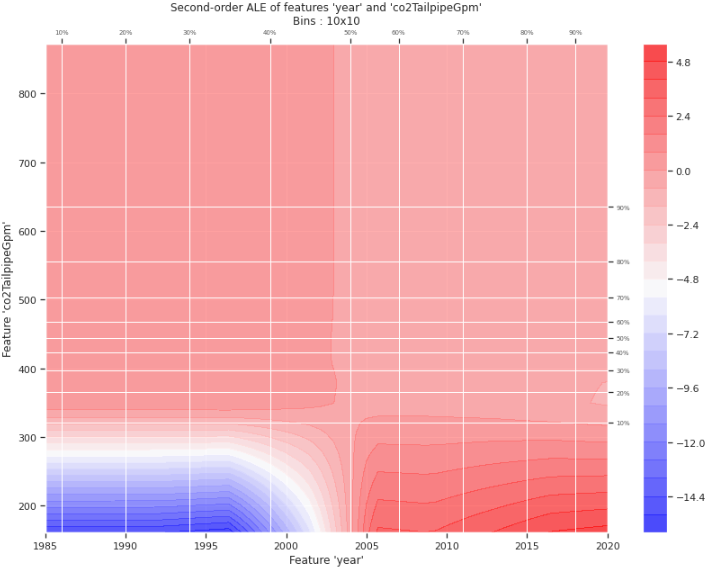
- year와 co2TailpipeGpm 간의 ALE 삭호 작용 플롯
3-7. 글로벌 대체 모델 (global surrogate model)
머신러닝에서의 대체 모델이란?
→ 블랙박스 모델의 예측값을 통해 학습하는 화이트박스 모델.
화이트박스 모델의 고유 매개변수에서 통찰력을 추출하기 위해 이 작업을 수행한다.
또 다른 방법 : 블랙박스 모델을 사용해, 액세스할 수는 없지만 예측치를 갖고 있는 다른 모델을 근사하고 평가하는 것 (Proxy model)
3-7-1. 대체 모델 적합
학습 데이터의 Y로 신경망 모델의 예측치 사용.
의사 결정 트리를 이용해 신경망 모델의 예측치를 학습한다.
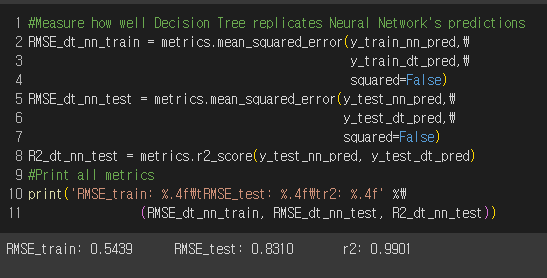
3-7-2. 대체 모델 평가
- 대체 모델의 예측 ↔ 신경망 모델의 예측이 너무 멀리 떨어져 있으면, 어떤 해석도 유용하지 않다.
- 너무 많이 과적합되면 신경망 모델이 학습 데이터에만 잘 근사되고 테스트 데이터에는 근사되지 않으며, 이런 경우 대체 모델을 사용하면 안 된다.
3-7-3. 대체 모델 해석
- 의사 결정 트리 시각화 (~ depth=2)
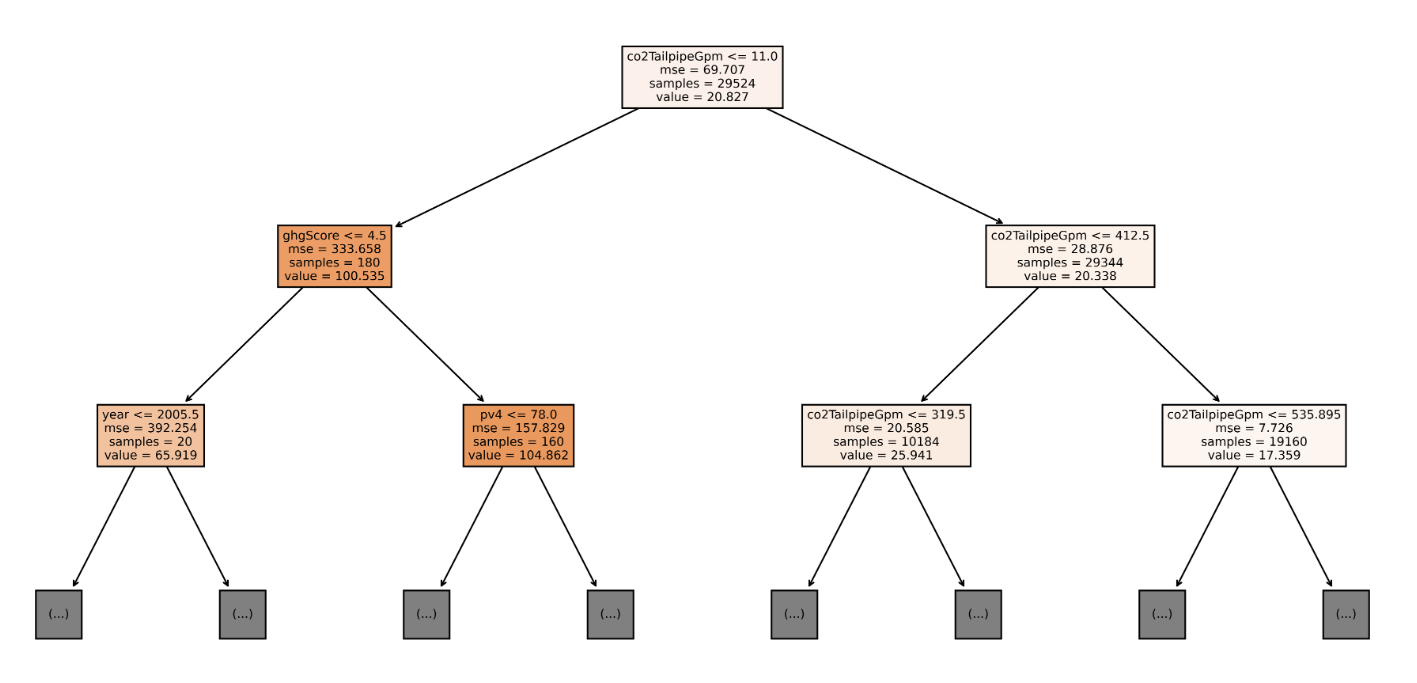
대체 모델에서 발견한 것은 원래의 모델에서만 결정적일 수 있으며, 모델을 학습하는 데 사용된 데이터에 대해서는 그렇지 않다.
3-8. 미션 완료
- 미션
데이터셋의 잠재적인 예측변수가 수년 동안 연비에 어떤 영향을 미쳤는지 이해하는 것.
- SHAP 의존도 플롯을 통해 CO2 및 ghgScore feature의 중복 이유 이해에 도움
- ALE 플롯에 표현된 것과 같이 2004년 이전에는 co2TailpipeGpm에 약간의 데이터 품질 문제 존재.