VIT 논문리뷰
Vision Transformer(ViT) 논문리뷰
1. 개요
Transformer 모델의 등장 이전, RNN은 오랜 시간동안 NLP(Natural Language Processing) 분야에서 기본 모델로써 활용되었다.
Attention is all you need : Transformer 모델의 등장으로 인해 NLP 분야에서 RNN의 시대 종결.
→ Transformer 중심으로 NLP 분야의 연구 진행이 시작됨.
Transformer의 성공은 Computer Vision 분야에도 많은 영향을 미치게 되었다.
CV 분야에서 CNN 모델이 지배적이였던 과거에는 Transformer 모델의 핵심 기능인 self attention을 CNN에 적용하는 방법을 중점적으로 연구해왔다.
하지만 최근에는 CNN에 self attention을 적용하는 것 보다, CNN 모델을 활용하지 않고 Transformer 모델 자체를 활용하여 Task를 진행하는 것에 초점을 둔 연구가 진행되고 있다.
2. Attention
Transformer 모델의 골자를 간략히 설명하자면, RNN과 CNN과는 다르게 Attention이라는 기능만을 이용해 모델을 구축하였다.
2-1. Seq2seq by RNN
- 문장(Sequence)을 입력으로 받아 문장(Sequence)을 출력하는 RNN 기반모델. 기계번역에 주로 사용됨.
- ‘Sequence’를 받아들이는 부분(Encoder)과 ‘Sequence’를 출력하는 부분(Decoder)을 분리한 것이 특징.
- Encoder는 입력 시퀀스를 받아들여 축약 후 컨텍스트 벡터(context vector)로 불리는, 고정된 크기의 벡터로 변환
- Decoder는 Encoder가 축약하여 생성한 컨텍스트 벡터를 받아 출력 시퀀스를 출력한다.
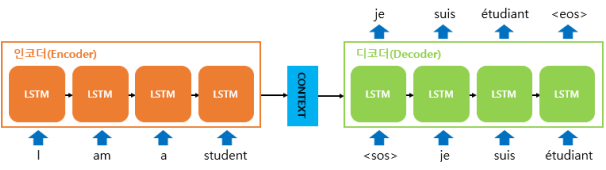
RNN 기반 Seq2seq의 단점 ; Context Vector의 크기가 제한적이기 때문에 입력 문장의 모든 정보를 전하기 어렵다.
2-2. Seq2seq with Attention
Decoder가 각 시점 단어를 출력할 때 Encoder 정보 중 연관성이 있는 정보를 직접 선택
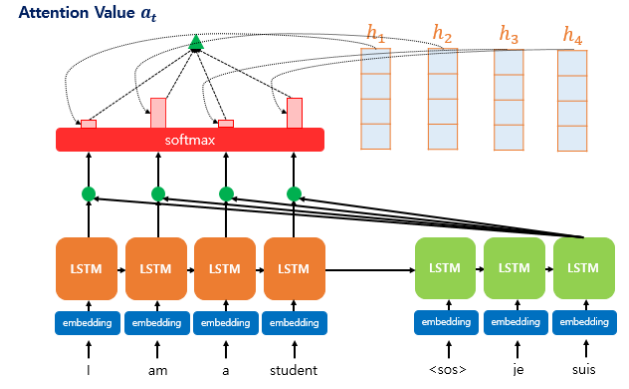
Attention 함수는 주어진 쿼리(Query)에 대해서 모든 키(Key)와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 값(Value)에 반영해준다. 그리고 유사도가 반영된 ‘값(Value)’을 모두 가중합하여 리턴한다.
2-3. Attention vs Self Attention
- Attention(Decoder → Query / Encoder → Key, Value) / Encoder, Decoder 사이의 상관관계를 바탕으로 특징 추출
- Self Attention (입력 데이터 → Query, Key, Value) / 데이터 내의 상관관계를 바탕으로 특징 추출
3. Transformer vs CNN
CNN은 모델 구조 상 여러 개의 Convolutional Layer를 거치며 2차원의 지역적인 특성(Locality)를 유지하기 때문에, 이미지 전체의 정보를 통합하기 위해서는 모든 Layer를 거치어 학습을 진행하여야 한다.
CNN의 이미지 데이터의 정보를 통합하기 위해 Convolutional Layer를 거치는 과정에서 Filter의 수, Filter의 높이와 너비, Stride, Padding 각 하이퍼파라미터 최적화를 진행하기 위해서 많은 시간이 소요된다.
또한 Convolutional Layer를 통과하는 훈련 진행 과정에서 역전파 알고리즘이 역방향 계산을 할 때 정방향에서 계산했던 모든 중간 값을 저장하여 다시 이용하여야 하므로, 많은 RAM 용량을 차지한다는 단점이 있다.
Transformer의 경우 입력된 이미지 데이터를 1d Vector로 변환한 후 self attention을 통해 Query, Key, Value 값을 얻는다. Query와 Key의 유사도를 측정함으로써 가중치를 얻고 그 가중치를 Value에 곱해줌으로써 최종적인 전체 이미지 정보를 통합할 수 있다.
즉 Transformer를 이용하여 self attention layer 하나만 거쳐줌으로써 멀리 떨어져 있는 정보들 사이의 교환이 이루어질 수 있는 것이다.
3-1. Inductive Bias
Inductive Bias란?
- 학습 시에 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용되는, 새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정
Inductive Bias가 강하게 작용하면 오히려 모델의 성능에 방해물이 될 수 있다.
SVM : Margin 최대화 / CNN : 지역적인 정보 / RNN : 순차적인 정보
Inductive Bias of Transformer
- 1d Vector로 만든 후 self attention 진행 → 2차원의 지역적인 정보 유지 X
- Weight이 input에 따라 유동적으로 변함
Inductive Bias of CNN
- 2차원의 지역적인 특성 유지
- 학습 후 Weight 고정.
CNN과 비교하여 Transformer의 Inductive Bias는 하락, 자유도는 상승한다.
→ 방대한 데이터가 주어졌을 때 CNN보다 Transformer가 우수한 성능을 낸다.
4. Vision Transformer(ViT)
4-1. ViT의 개요
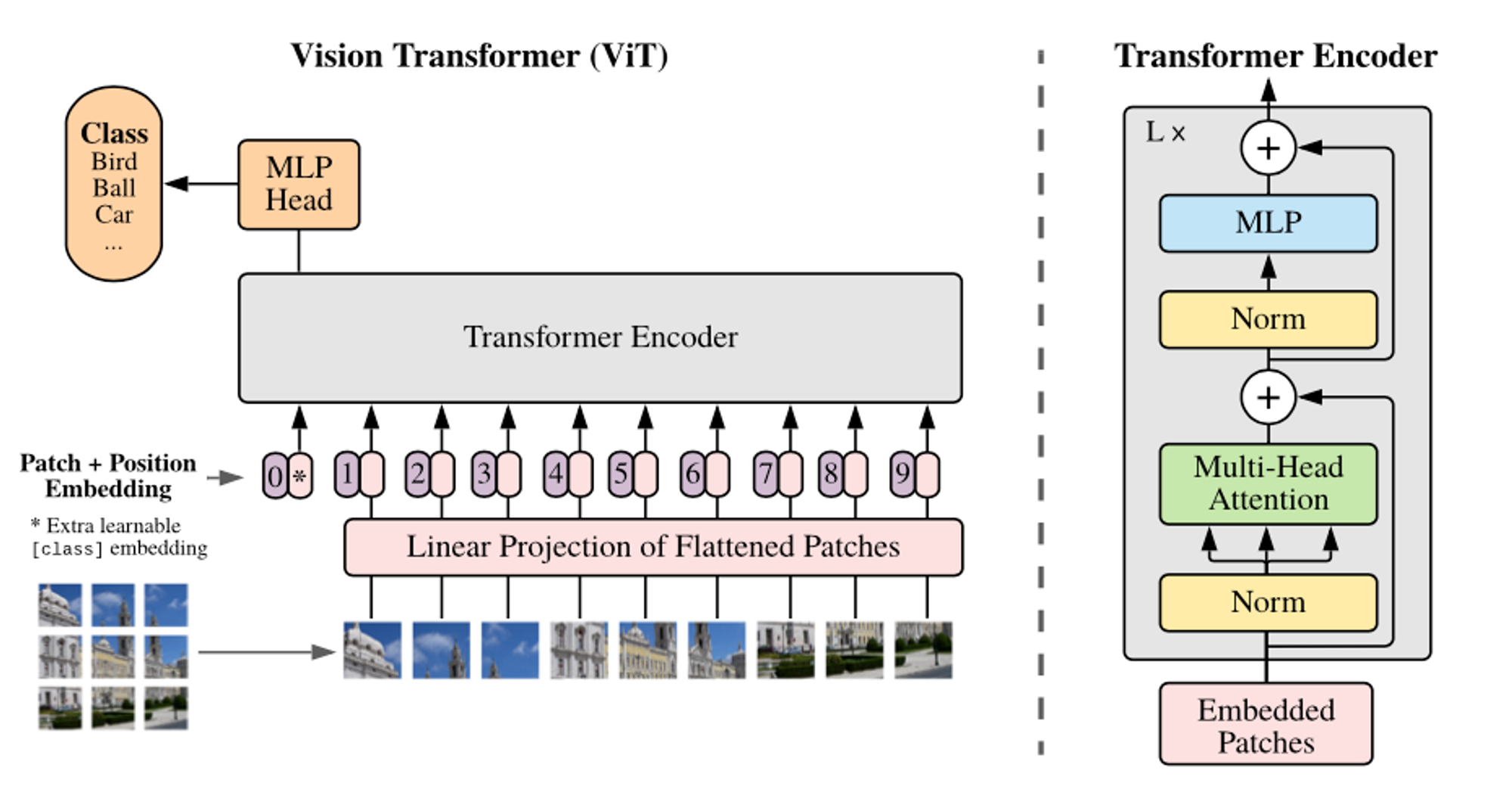
Vision Transformer(ViT) : CNN 없이 Transformer만을 이용한 이미지 처리 모델이다.
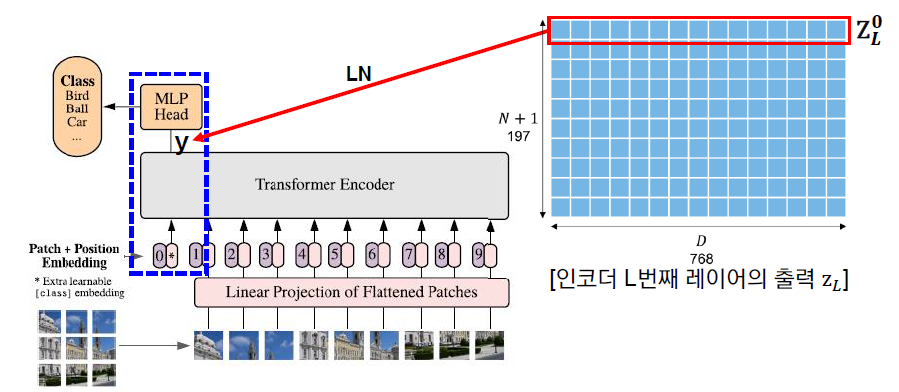
ↆ Vision Transformer(Base)의 구조
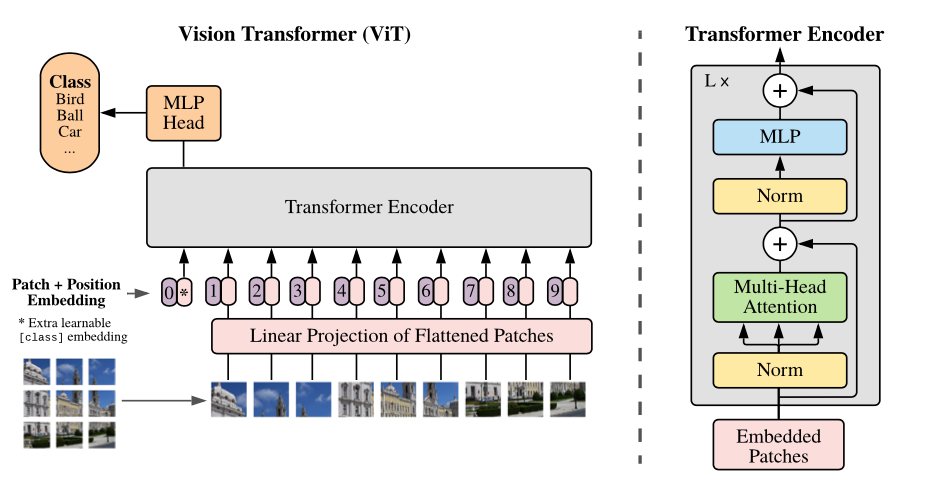
- ViT는 이미지를 16*16 크기의 패치(Patch)로 분할한 후, 이를 NLP의 단어로 취급하여 각 패치에Linear Projection을 적용하여 생성한 embedding vector를 순서대로 Transformer의 input으로 넣어 이미지를 분류한다.
- 각각의 패치들을 1d의 vector로 표현할 때, 이미지의 특성 상 RGB 3개의 채널로 표현하기 위해 1d * 16163(=768) 차원으로 만들어진 패치를 Linear Projection하는 과정을 ‘Input이 768차원에서 Ouput이 768차원인 Fully Connected Layer를 통과한다’ 라고 이해할 수 있다.
- 상기된 일련의 과정을 통해 Flatten하여 임베딩한 각 패치에 Classification(CLS) 토큰, Position embedding이 추가된다.
Classification Token : Classification을 위해 사용되는 고유한 토큰
Position embedding : 학습 가능한 Patch의 위치 정보
4-2. Encoder
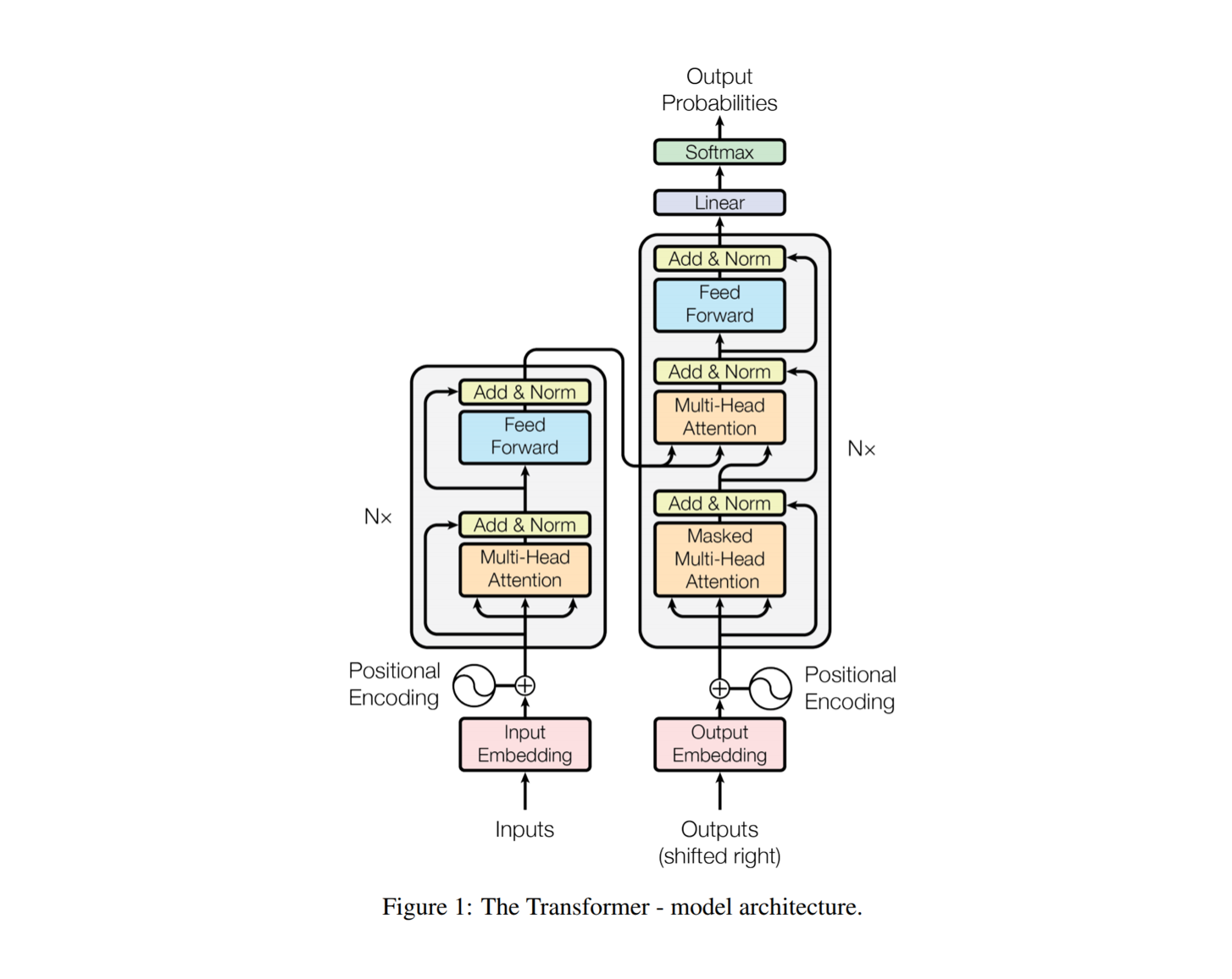
기존의 Transformer 모델의 Layer를 깊게 쌓게 될 경우, 학습이 어려워진다는 단점이 지적이 되기 시작했다. 이러한 단점을 극복하기 위해서 Layer Normalization의 위치가 중요하다는 점이 후속 연구를 통해 대두되었다.
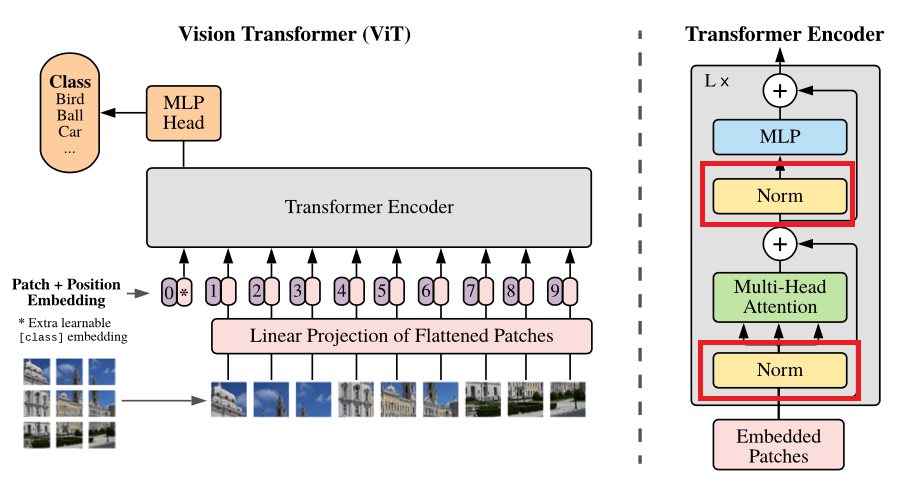
ViT에서 후속 연구의 결과를 받아들였다.
병렬로 Attention을 진행하는 모듈인 Multi-Head Attention을 통과한 후 Normalization을 진행하는 기존 Transformer와 달리, ViT에서는 Normalization을 통과한 후 Multi-Head Attention을 진행하게 된다. 이를 통해 깊은 Layer에서도 학습이 잘 되도록 설계하였다.
4-2-1. Encoder : Multi-Head Attention
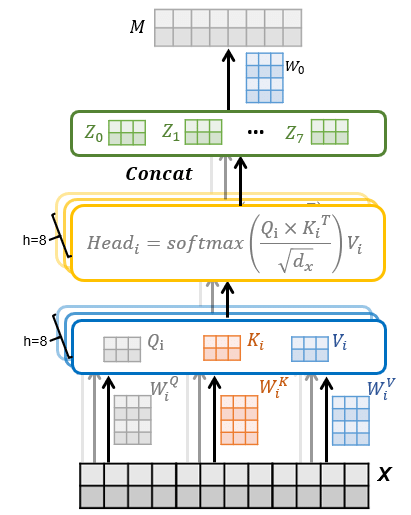
위 사진은 Multi-Head attention의 세부 아키텍처이다.
Vit에서 진행되는 Multi-Head attention의 과정은 다음과 같다.
- 768d로 embedding한 patch를 8개의 num_heads로 나누는 rearrange를 통해 matrix로 저장한다.
- 저장된 각 patch matrix를 linear projection을 통하여 Query, Key, Value 세 개의 텐서로 저장한다.
- 병렬적으로 softmax를 이용한 Scaled Dot-Product Attention 과정(주황색 박스)을 진행하여 attention output을 얻는다.
- Scaled Dot-Product Attention이란?
Attention 메커니즘의 마지막 출력층의 스코어 함수 값을 특정 값으로 나누어 줌으로써 어텐션 값을 스케일링하는 메커니즘이다.
Scaled Dot-Product Attention에서 진행하는 Scaling을 통해, Attention 값이 커지게 되면 발생하는 Gradient Vanishing을 방지할 수 있다.
이렇게 학습된 결과물인 attention output은 Layer Normalization을 거친 후 Multi Layer Perceptron를 통과하여 최종적인 Transformer Encoder의 output을 도출하게 된다.
4-2-2. Multi Layer Perceptron(MLP) in Encoder of ViT
ViT에서 사용된 MLP는 768d의 input layer와 output layer, 그리고 3072d의 hidden layer 한 개로 2 layer를 구성하는 fully-connected layer이다.
ViT에서 MLP는 Linear input layer를 거쳐 은닉층에 도달한다.
은닉층의 활성화 함수는 GELU를 이용하고, dropout을 적용하여 학습한 후 출력층의 Linear layer를 거쳐 다시 embedding size로 축소하게 된다.
이렇게 입력된 데이터가 Encoder와 MLP를 거쳐 CLS Token 개의 label로 분류되어 최종 output을 산출한다.
4-3. Inductive Bias (again)
- CNN의 경우 input image에서 기인한 locality가 모든 Convolutional layer에 내재되어 있으므로 image-specific inductive bias가 높다.
- ViT의 Encoder에서의 Multi-Layer Perceptron은 input이 patch의 단위로 들어오기 때문에, input에 대한 locality와 translation equivariance가 존재한다. 하지만 MSA는 input image를 1d patch로 변환하여 global한 구조를 갖고 있기 때문에 CNN보다 image-specific inductive bias가 낮음.
- ViT에서는 아래 두 가지 방법을 사용하여 Inductive Bias의 주입을 시도함.
- Patch extraction : 이미지를 여러 개의 패치로 분할하여 순서가 존재하는 형태로 넣는 것
- Resolution adjustment : Fine-tuning을 진행할 때 image의 resolution에 따라서 패치의 크기는 동일하지만, 생성되는 패치의 개수가 달라지게 된다. 패치의 갯수에 따라 조정하게 되는 Positional Embedding을 통해 inductive bias가 주입된다.
4-4. Hybrid Architecture
- ViT의 input image로 아무 가공을 진행하지 않은 기존의 raw image보다, CNN으로 추출한 raw image의 feature map을 활용하여 hybrid architecture로 활용할 수 있다.
- CNN 모델 특성 상 feature map은 이미 raw image의 공간적 정보를 포함하고 있으므로 feature map의 패치 크기를 1 by 1으로 설정해도 무방하다.
- 1 by 1 패치를 사용할 경우 feature map의 공간 차원을 flatten하여 각 벡터에 linear projection을 적용한다.
4-5. Fine-Tuning and Higher Resolution
ViT의 Fine-Tuning 과정
- 먼저 Large Scale의 데이터로 ViT를 Pre-training한다.
- Pre-train한 해당 모델을 구체적인 최종 목표인 downstream task에 fine-tuning하여 사용한다.
Pre-trained 모델을 downstream task에 fine-tuning하는 과정에서 ViT의 pre-trained prediction head를 제거하고 0 값으로 초기화된 feedforward layer로 대체하여 준다.
즉, input image의 패치에서 정보를 추출하는 Transformer Encoder는 그대로 사용하지만 특정 Task의 output을 도출하기 위한 MLP의 Head는 downstream task의 목적에 맞도록 다시 학습을 하기 위해 0으로 초기화하여 사용한다.
이 과정을 통해 더 우수한 성능을 얻을 수 있다.
higher resolution, 즉 고해상도의 이미지를 fine-tuning할 경우 input image의 패치의 크기는 pre-training을 할 때와 동일하므로 sequence의 길이가 더욱 길어진다.
ViT의 self-attention의 특성 상 가변적 길이의 패치들을 처리할 수 있지만, 패치의 개수가 많아지면 pre-trained position embedding의 의미가 사라지므로 pre-trained embedding을 원본 이미지의 위치에 따라 2D interpolation하여 사용한다.
5. Experiment
5-1. Setup
- Datasets
ViT는 아래와 같이 class와 이미지의 개수가 각각 다른 3개의 데이터셋을 기반으로 pre-trained되었다.
| Dataset | Classes | Images |
|---|---|---|
| ImageNet-1k | 1k | 1.3M |
| ImageNet-21k | 21k | 14M |
| JFT | 18k | 303M(High resolution) |
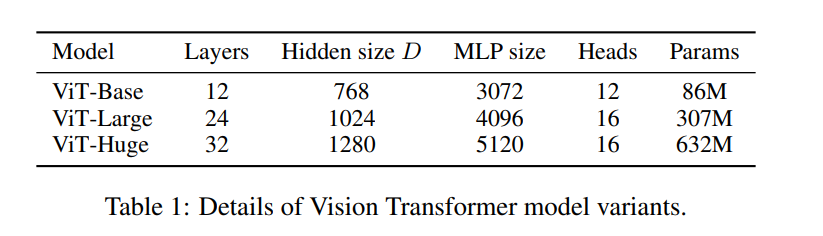
- Model Variants
ViT는 아래와 같이 총 3개의 volume에 대해 실험을 진행, 다양한 패치 크기에 대해 실험을 진행했다.
Baseline CNN은 batch-norm layer를 group normalization으로 변경한 후 standardized convolutional layer를 사용하여 transfer learning(전이학습)에 적합한 Big Transformer(BiT) 구조의 ResNet을 사용하였다.
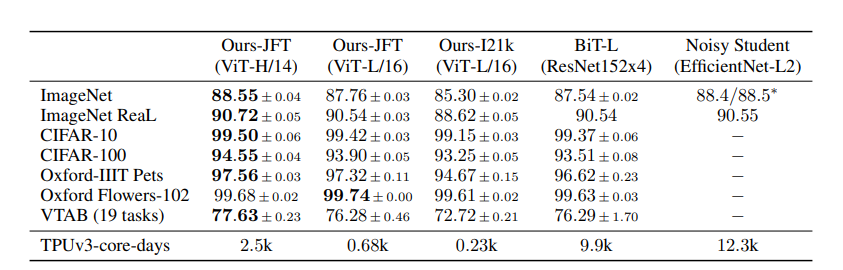
- 실험 결과
본 실험에서는 1414 패치 크기를 적용한 ViT-Huge와 1616 패치 크기를 사용한 ViT-Large의 성능을 baseline과 비교함
JFT dataset에서 pre-training한 ViT-L/16 모델이 모든 downstream task에 대하여 BiT-L보다 높은 성능을 도출함
ViT-L/14 모델은 ViT-L/16 모델보다 향상된 성능을 도출하였으며, BiT-L 모델보다 학습 시간이 훨씬 짧음