투빅스 20&21기 컨퍼런스 - 나만의 AI 펫프로필 만들기 후기

투빅스 20&21기 컨퍼런스 : 나만의 AI 펫 프로필 만들기 후기
0. Introduction
24년 4월부터 24년 7월까지, 대학생&대학원생 인공지능 및 데이터 분석 대표 연합 동아리 투빅스에서 나의 기수인 20기와 후배 기수인 21기의 20&21기 18회 컨퍼런스로 생성모델 팀에서 프로젝트를 진행하였다.
저번에 진행한 19&20기 컨퍼런스에서는 주제에 대한 큰 고민 없이 NLP를 선택하였지만, 이번에는 어떤 주제를 선택할 지 고민이 되었다. 원래 XAI로 컨퍼런스를 진행하고 싶었으나, 확실히 사람들에게 생소한 주제이기도 하고, XAI라는 주제로 프로젝트를 진행하기 어려워서 그런지 XAI 신청자 수가 적어 팀이 만들어지지 않았다.
그 다음으로 멀티모달과 생성모델 간에서 고민을 하였다. 고민을 하던 순간 디퓨전 모델을 이용하여 프로젝트를 진행하면서, 디퓨전 모델의 Causality나 Interprete를 하여 XAI의 주제를 섞으면 재밌을 것 같다는 생각이 들어서 생성모델로 주제를 선택하게 되었다.
팀원들끼리 하고싶은 주제를 얘기하고 의견을 나누던 도중 나는 Diffusion 모델을 Counterfactual Estimation을 통해 Causality를 밝히는 논문을 발견하였고, 이런 주제를 이용하여 어떤 눈에 보이는 결과를 도출하기보단 좀 더 Research에 가까운 프로젝트를 진행하자고 주장하였다.
하지만 확실히 어려운 주제이기도 하고, 이제 막 연구가 시작된 분야이기 때문에 어려울 것 같다는 우려가 많았다. 그러하여 LLM과 Diffusion 모델을 이용하는 “나만의 펫 AI 프로필 만들기 프로젝트”를 진행하기로 하였다. 이 주제 또한 내가 하자고 하여 투표를 통해 선정되었다.
1. Motivation
요즘 Snow AI 프로필과 같이 사용자의 얼굴 사진 몇 장을 입력하면 다양한 스타일에 맞춰서 프로필 사진을 제작해주는 서비스가 많이 등장하고 있다.
여러 AI 프로필 서비스를 살펴보면, 사용자의 입맛에 맞춰 원하는 스타일로 생성해주는 것이 아니라 딱 정해진 프레임과 스타일로만 생성해주는 서비스가 대부분이다.

우리 집밥 백선생 백종원 선생님과, 마동석 형님의 AI 프로필사진을 예시로 보여주었다.

여기서 우리는 생각하였다. 사용자가 원하는 대로 “Text Instruction에 따라 달라지는 AI 프로필을 만들 수 있을까?” 그리고 “사람이 아닌 반려동물의 AI 프로필을 만들 수 있을까?”
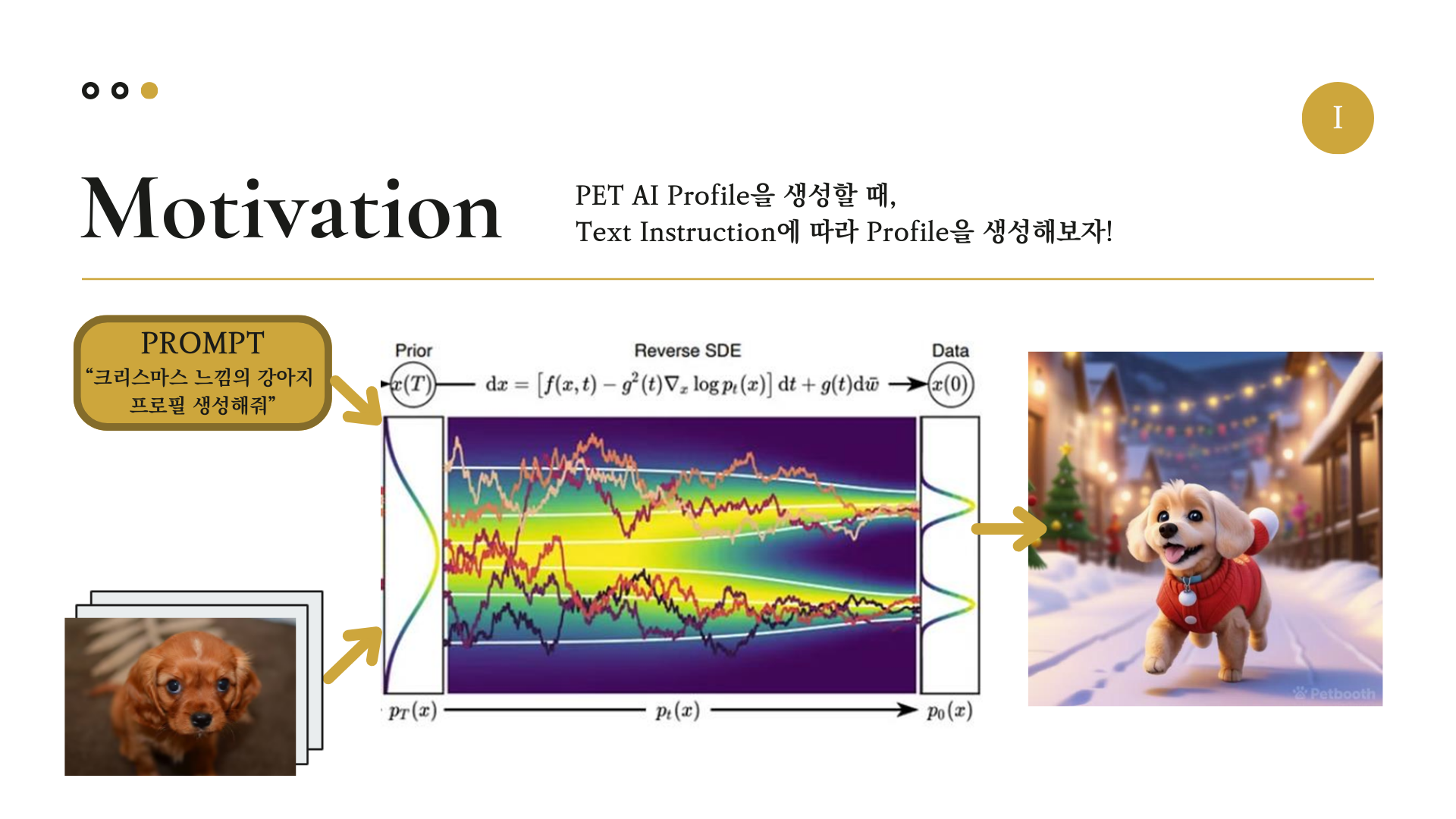
우리는 Stable Diffusion 생성모델을 이용하여, Pet AI 프로필을 생성할 때 Text Instruction에 따라 달라지는 프로필을 생성하는 프로젝트를 하기로 하였다.
여기서 Stable Diffusion 모델에 들어가는 Input으로는 1. 사용자의 반려동물(이번 프로젝트에서는 특히 강아지에 집중하였다.), 2. 프롬프트(사용자가 원하는 프로필 스타일) 이 들어가고, Output으로 그에 맞는 프로필 사진이 출력되도록 구성을 하였다.
2. PipeLine
사용자가 입력한 반려동물 각각에 개인화된 프로필 사진을 만들기 위해, SDXL(Stable Diffusion XLarge) 모델을 Fine Tuning하는 작업을 진행해야 한다.
우리는 SDXL을 Fine Tuning하기 위한 기법으로 Textual Inversion(TI)을 이용하였다. Textual Inversion이 진행되는 방식은 다음과 같다.
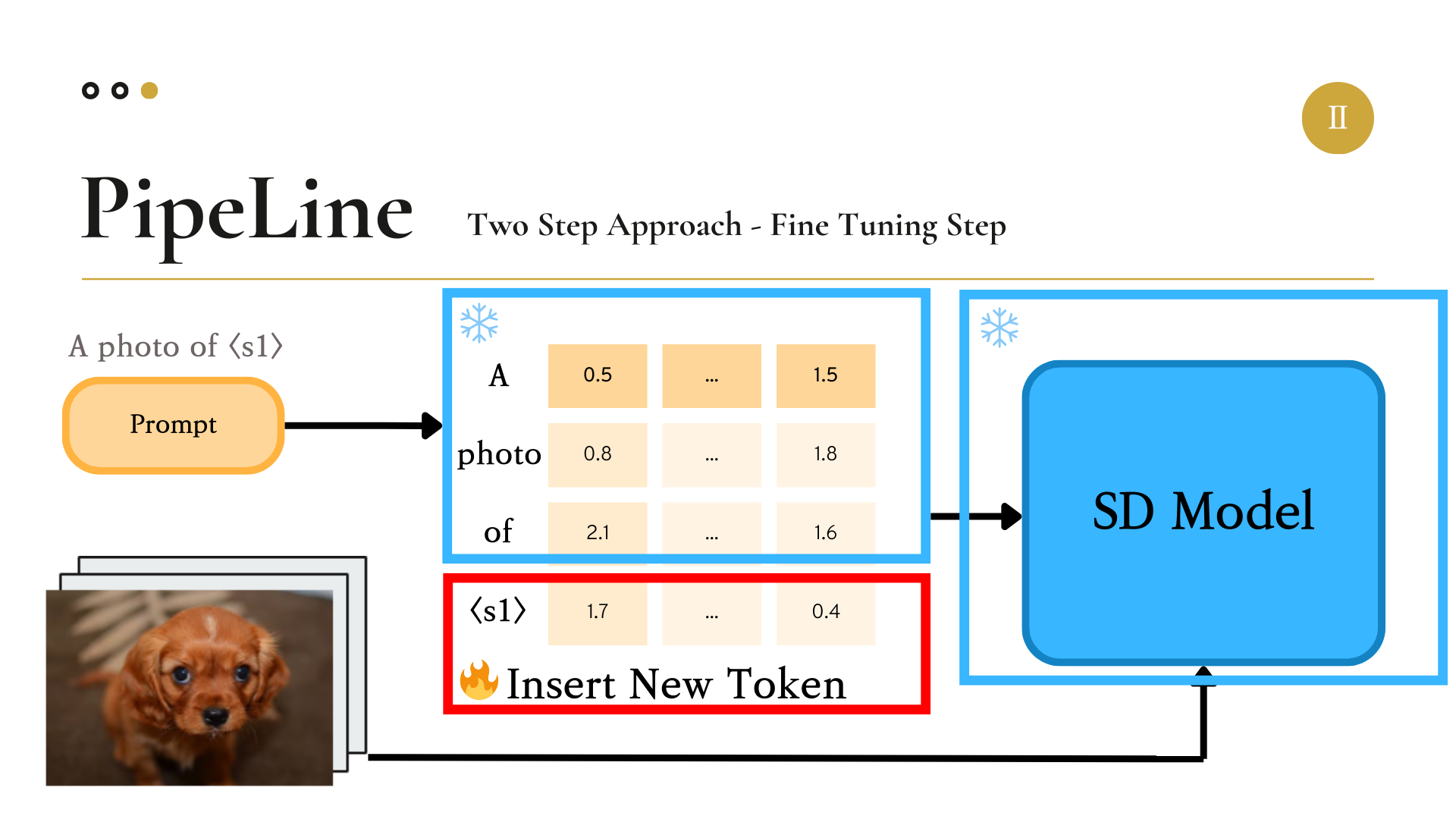
우선 모델에 Input으로 강아지 이미지와, 이미지에 대한 정보로 “A Photo of
그러면
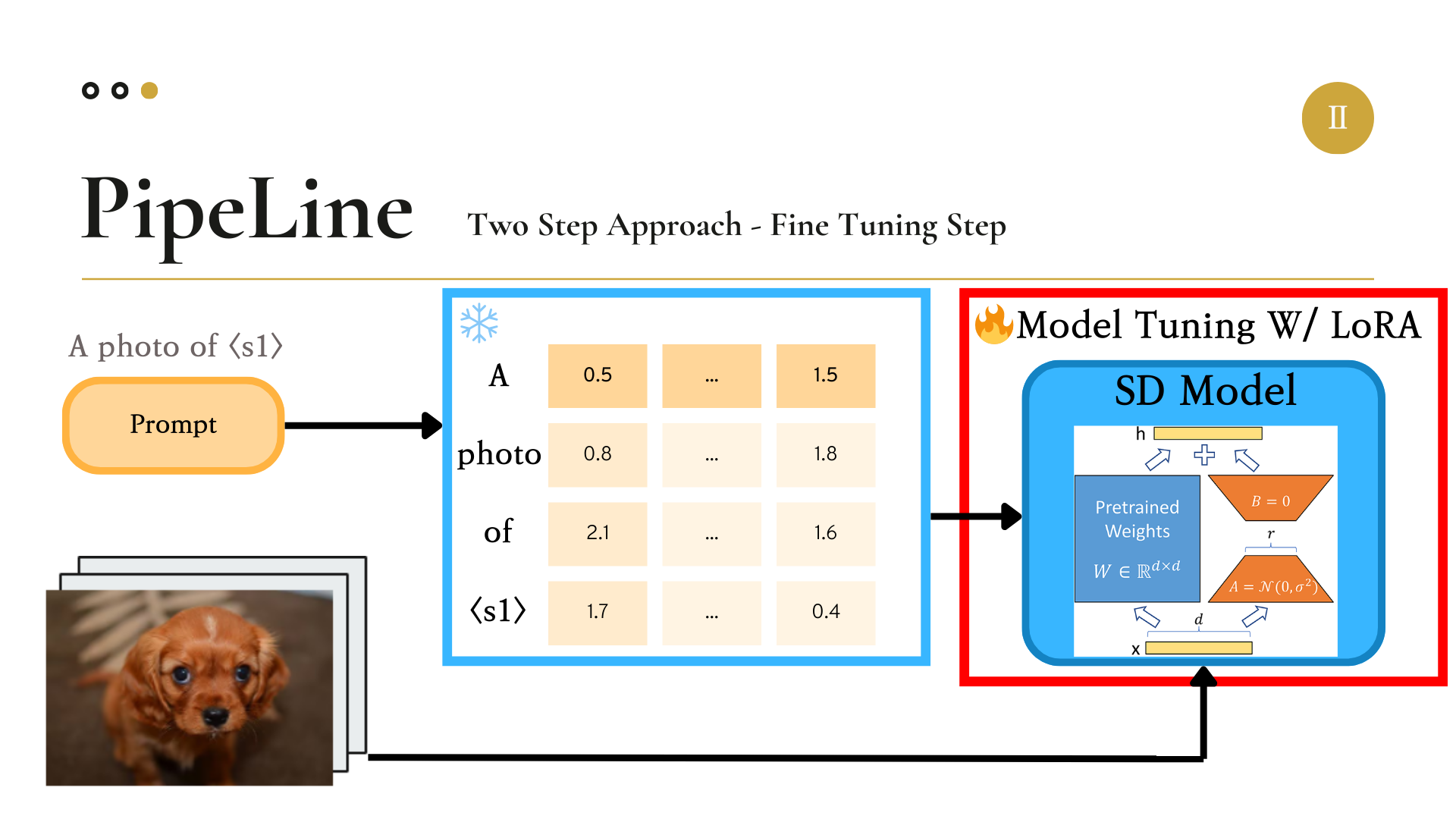
이렇게 학습을 통해 조정된
LoRA는 2021년 6월 마이크로소프트에서 제시한 모델 파라미터 튜닝 기법이다.
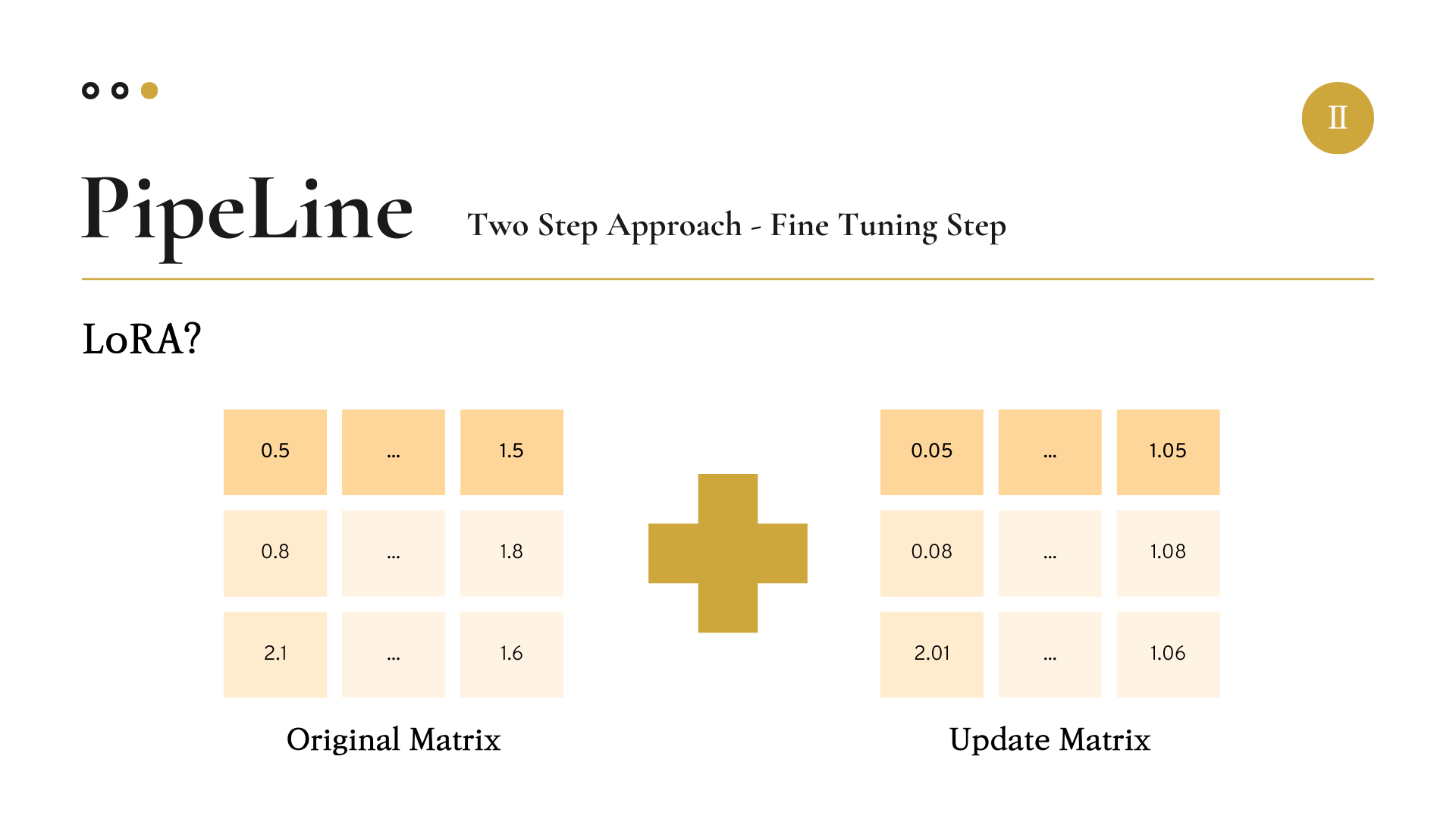
원래 우리가 업데이트해야 할 모델의 파라미터 행렬(Matrix)의 크기가 3 by 3이고 이를 Full-Fine Tuning을 진행할 경우 3 by 3 matrix의 모든 값을 계산해야 한다.
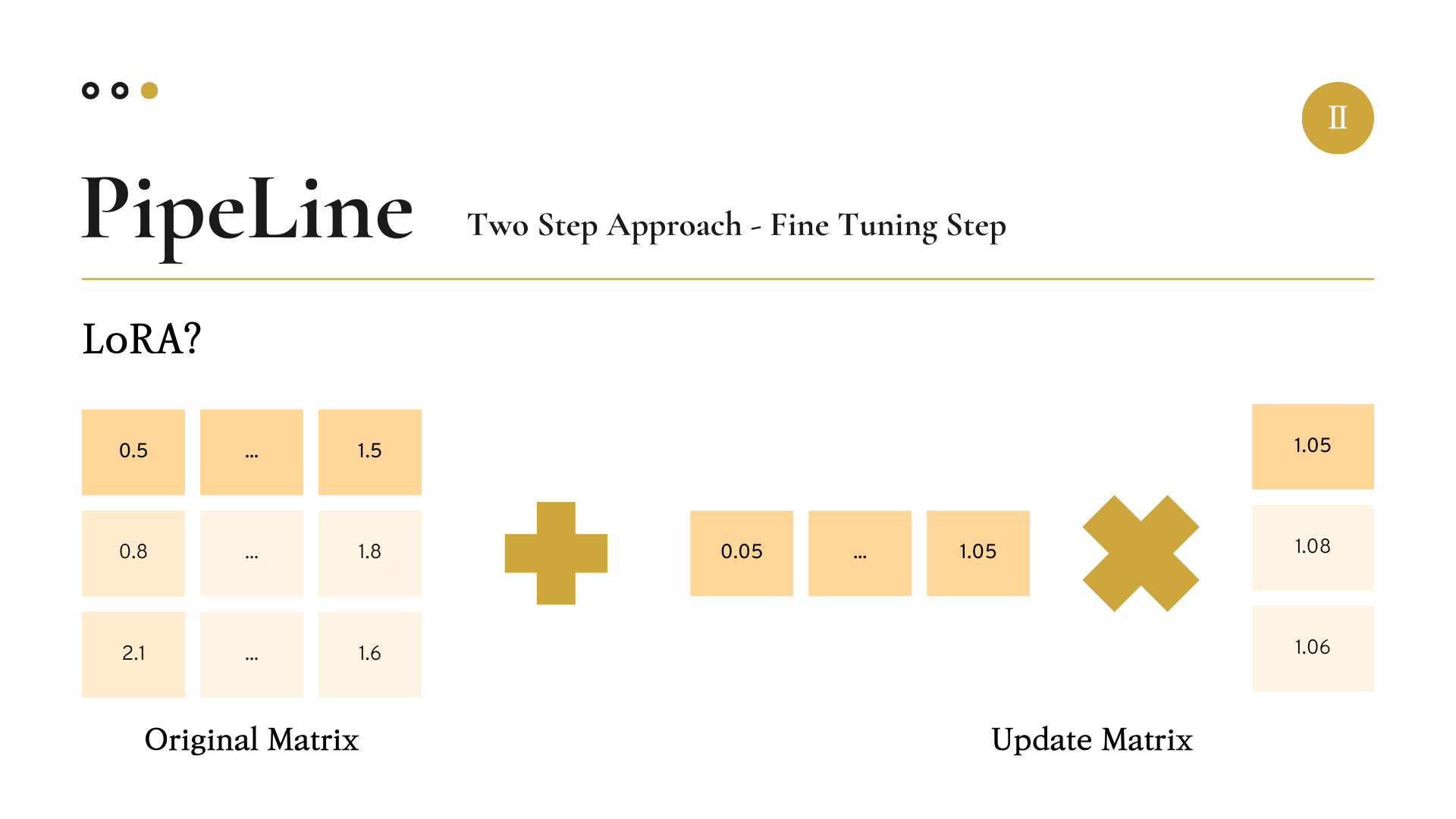
하지만 LoRA 기법에서는, 이 파라미터 행렬을 3 by R(Rank) matrix와 R(Rank) by 3 matrix로 나누어 두 행렬을 각각 업데이트한다.
그런 다음 업데이트가 완료된 두 행렬을 곱해주어 3 by 3 matrix로 크기를 복구해준다.
여기서 R(Rank)의 값을 우리가 임의로 정해주어, 랭크를 얼마나 반영하여 업데이트할 지 정해줄 수 있다.
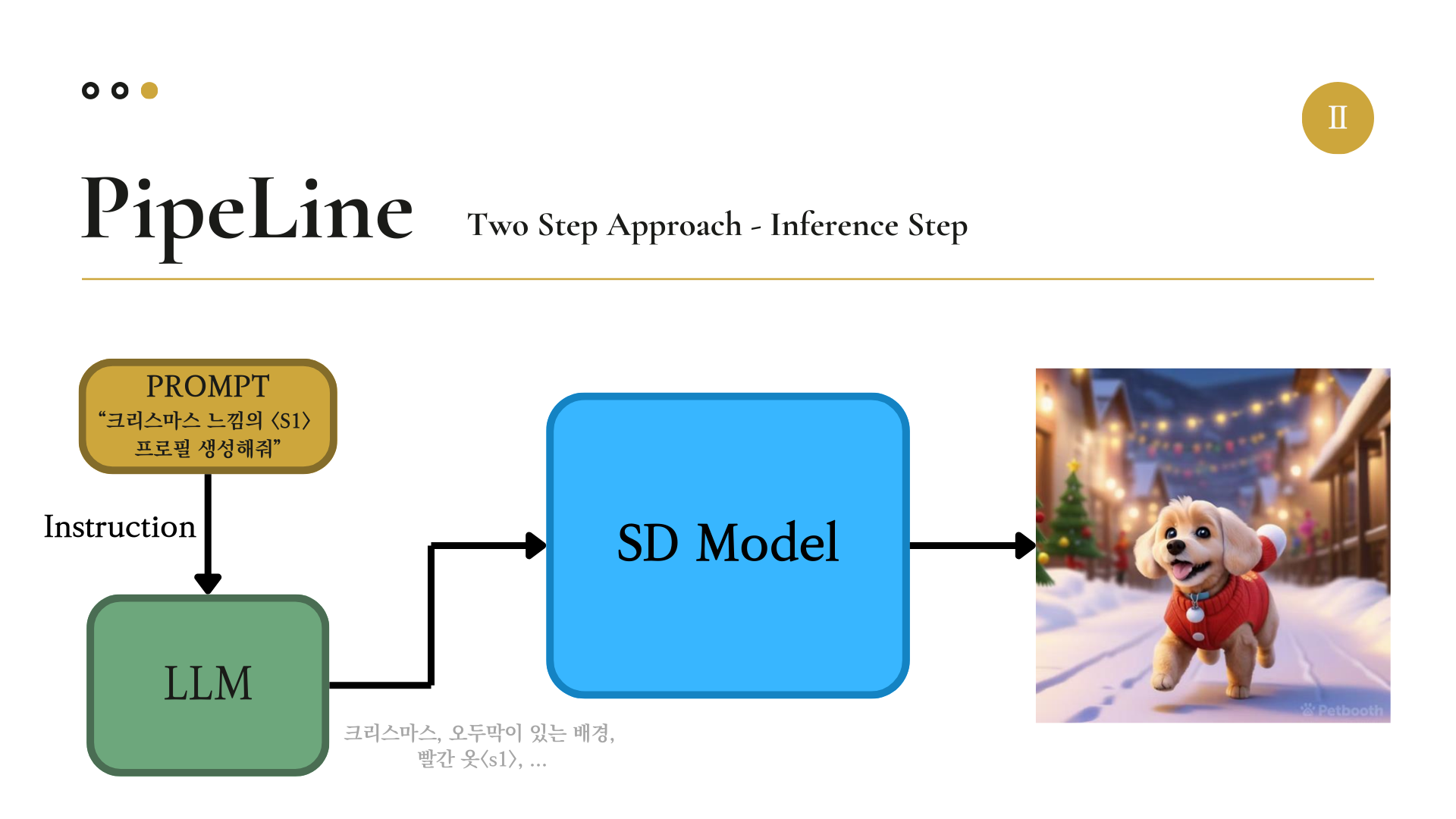
이제 이미지를 출력하는 단계인 Inference의 과정을 설명하겠다.
3. Diffusion Model
이번 프로젝트에서 가장 핵심적으로 사용된 Diffusion Model(SDXL)이 이미지를 생성하는 원리에 대해 간략히 설명하자면 다음과 같다.
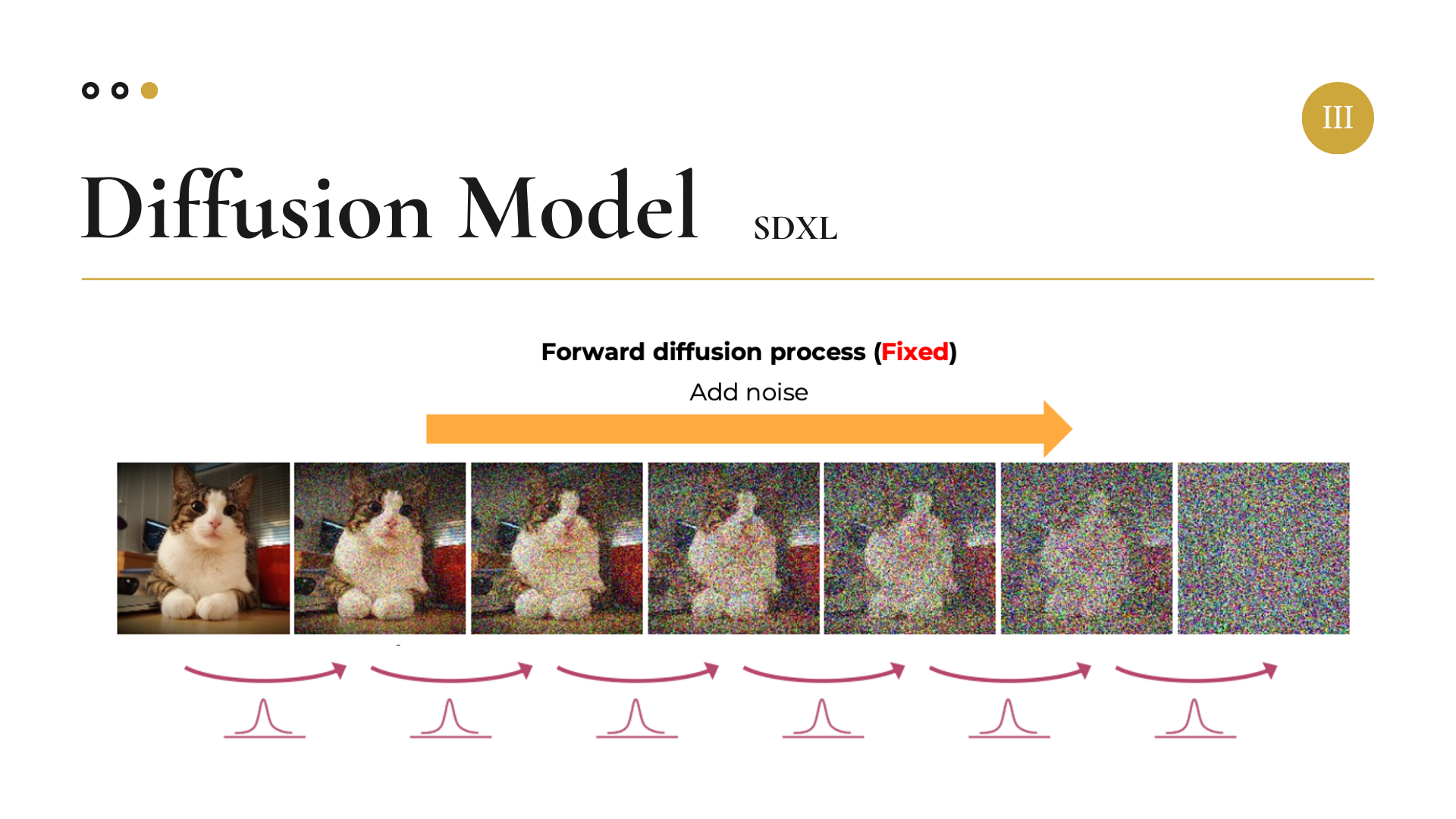
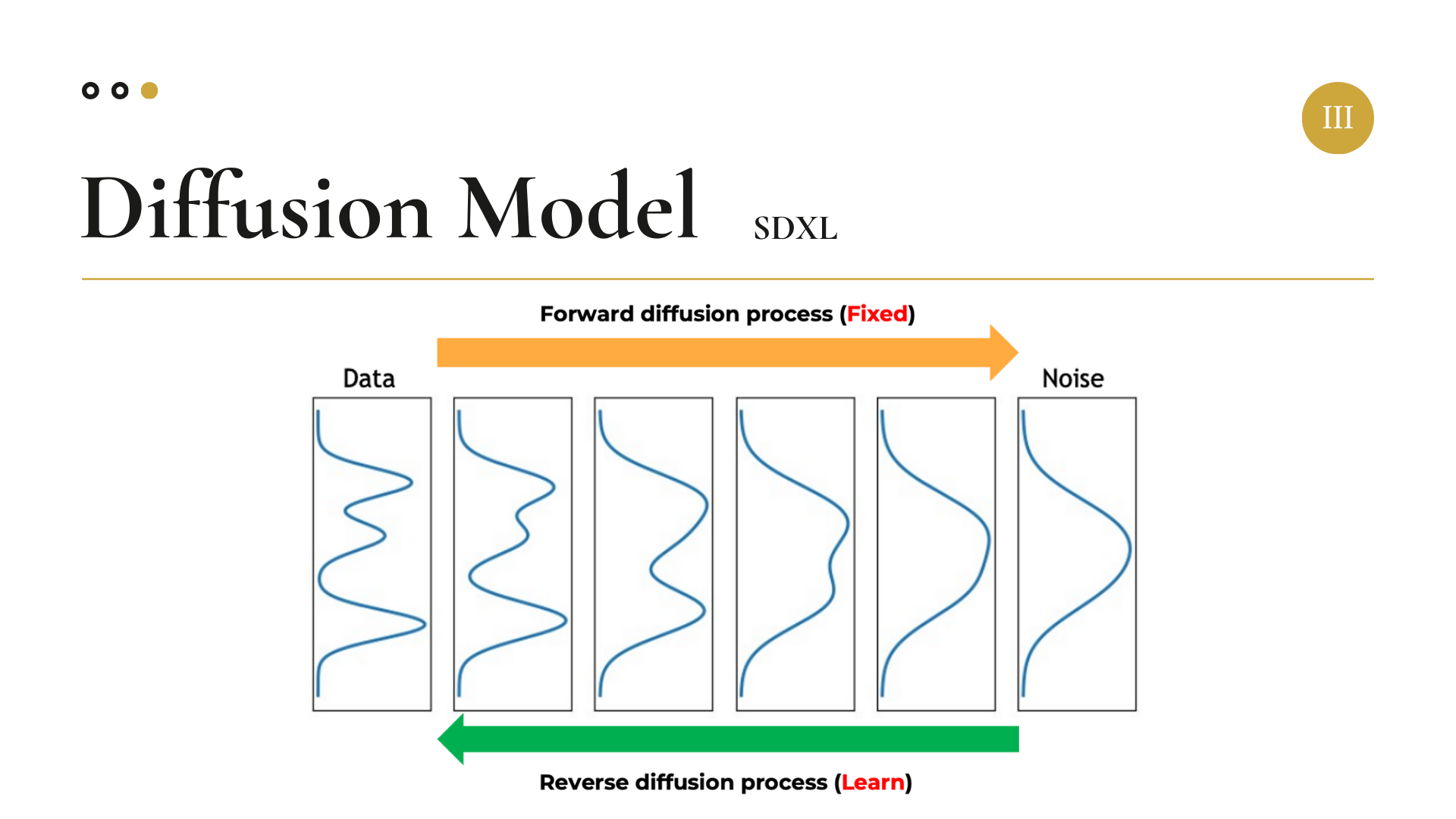
우선 원본 이미지가 주어지고, Forward Process를 통해 이미지 데이터에 점진적으로 Gaussian Noise를 추가한다. 이 과정은 다음과 같은 수식으로 표현된다.
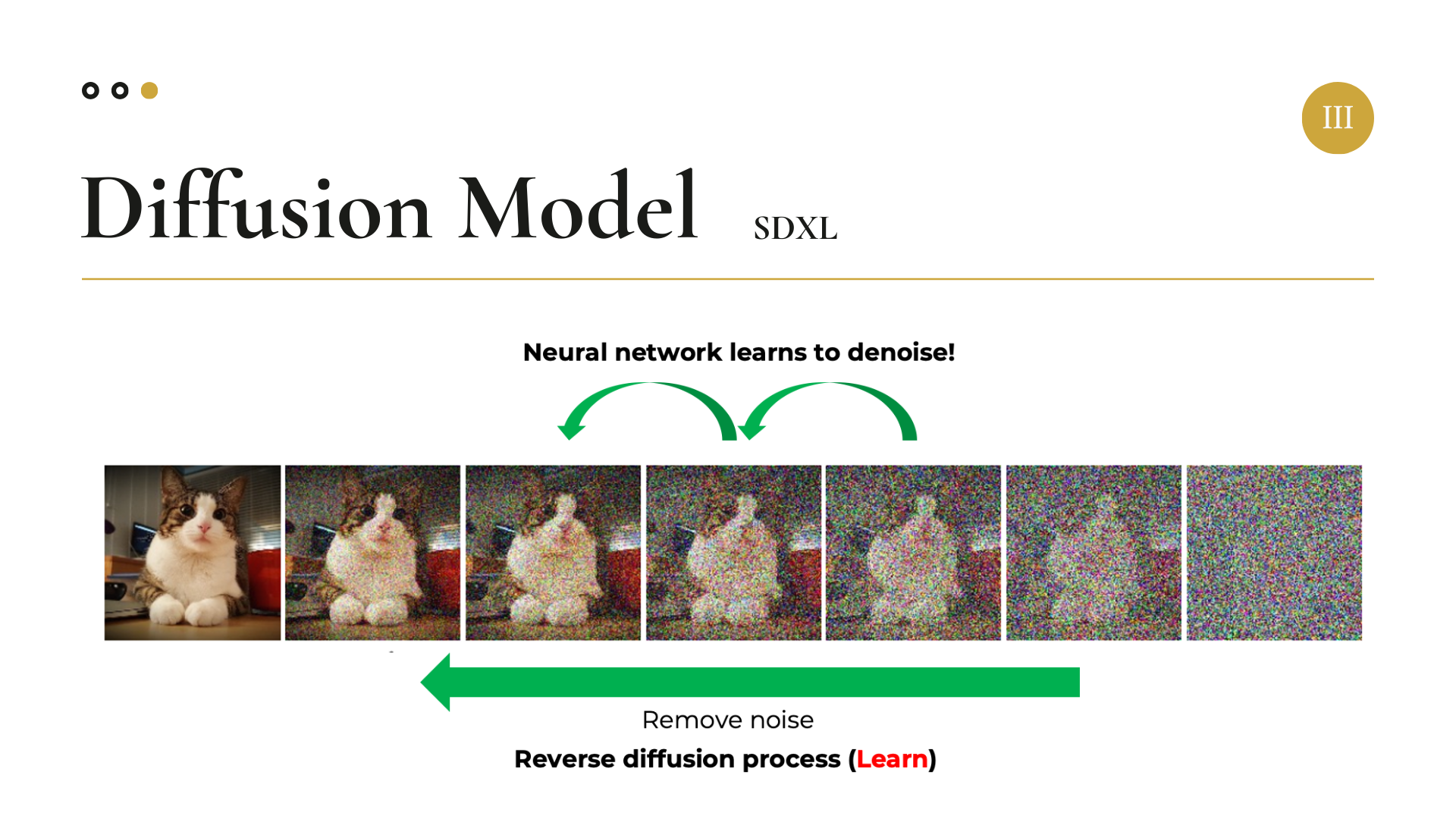
그 다음 Reverse Process를 진행한다. Reverse Process에서는 다시 점진적으로 Noise를 제거하여 원본 데이터를 복원함으로써 모델 학습을 진행한다. 이 과정은 다음과 같은 수식으로 표현된다.
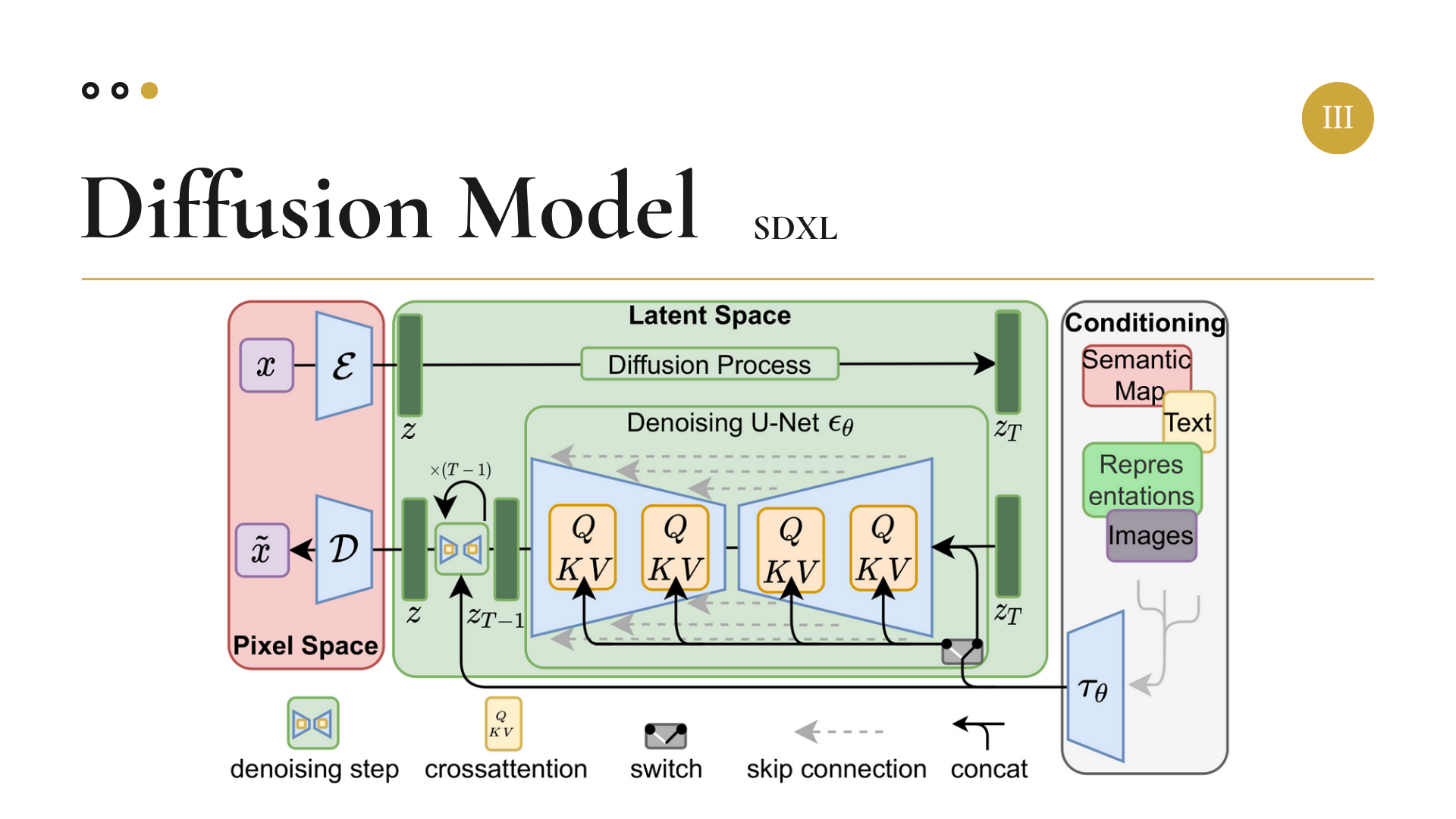
Stable Diffusion (High-Resolution Image Synthesis with Latent Diffusion Models)에 대해 더 자세히 알고 싶으면, 아래의 링크에 예전의 내가 잘 정리해 두었으니 참고하길 바란다.
https://gyeongminsu.github.io/posts/stable-diffusion/
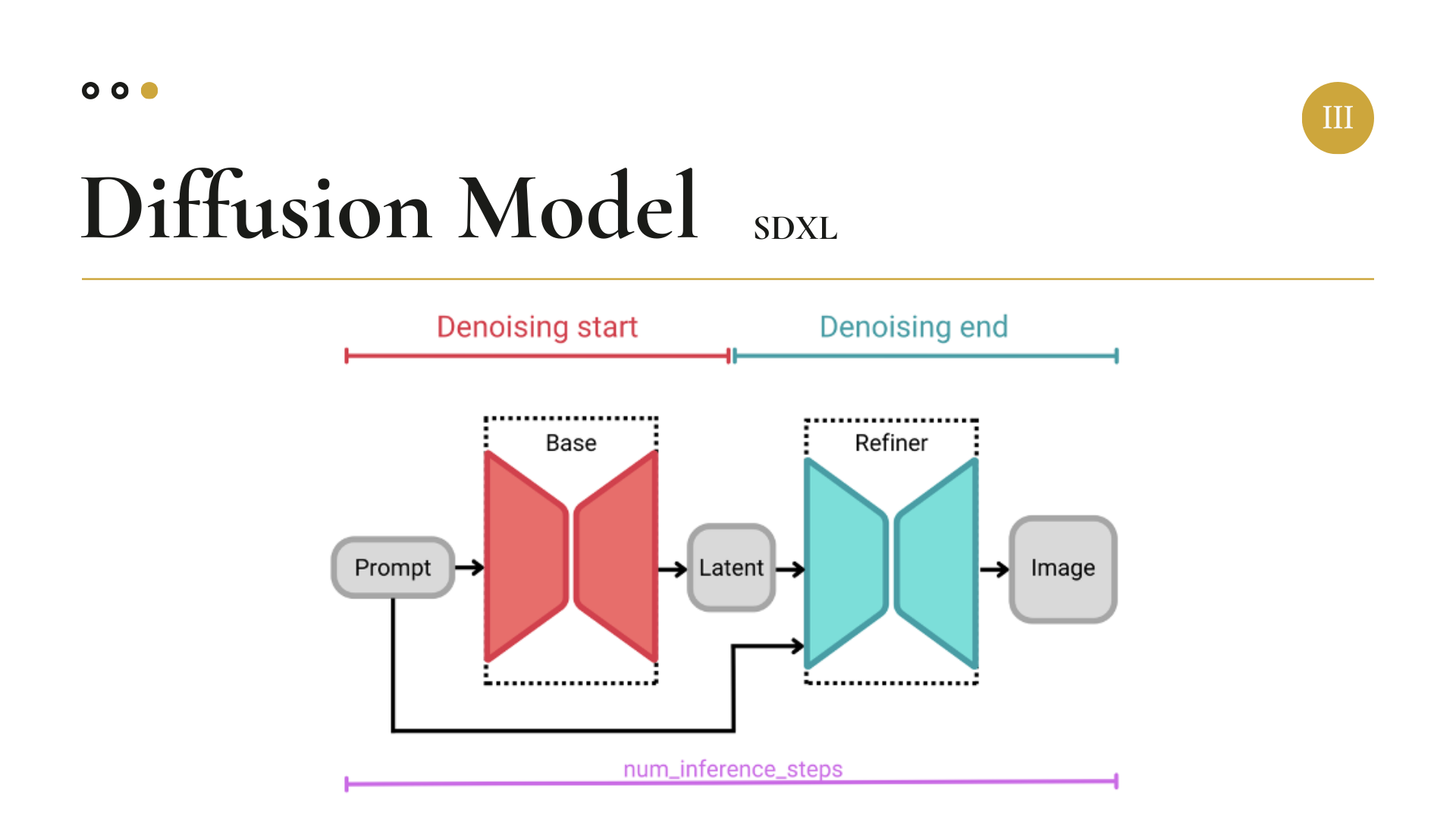
마지막으로 SDXL에 대한 설명이 있다.
SDXL은 2023년 7월에 발표된 Stable Diffusion의 업그레이드 된 버전이다.
전체적인 구조는 Stable Diffusion과 같지만, 차이점으로는 대폭 향상된 U-Net Backbone의 규모가 있다.
그리고 SDXL에는 Refiner라는 구조가 들어있는 데, Refiner를 이용하여 이미지의 디테일한 부분과 해상도를 더욱 업그레이드 하도록 고안된 구조라는 것만 알아가시면 되겠다.
4. LLM Prompt Engineering
사용자가 입력한 프롬프트를 생성모델이 더 좋은 이미지를 생성하게 가다듬어 주기 위해서, LLM을 이용해 Prompt Engineering을 진행하였다.

여기서 사용한 언어모델로는 Meta의 Llama3-Instruct-8b를 이용하였다.
OpenAI API를 이용하여 GPT-4o를 이용하는 방법이 있긴 했지만, 과금을 하기가 싫었다.
그리고 우리에게 주어진 GPU 환경은 A6000 (VRAM 48GB)였고, 이 환경에서 가장 적합한 언어모델이 Llama3-8b였다.

이 프로젝트를 처음 구상할 때는, DiffusionDB의 데이터베이스를 이용하여 RAG를 통한 프롬프트 엔지니어링을 하려 했었다. DiffusionDB에는 약 2백만 개의 이미지가 있으며, 데이터베이스 구성이 체계적으로 되어 있어서 사용하기 적합하다고 판단했다.

하지만 직접 DiffusionDB 안의 내용을 확인해 본 결과, 이미지의 퀄리티 자체가 높지 않았고 우리의 타겟인 강아지에 대한 사진이 많지 않았기에 적절한 데이터셋을 만들 수 없다고 판단하였다.
그래서 대안을 찾아보던 도중 LLM-grounded Diffusion이란 논문을 찾게 되었다.
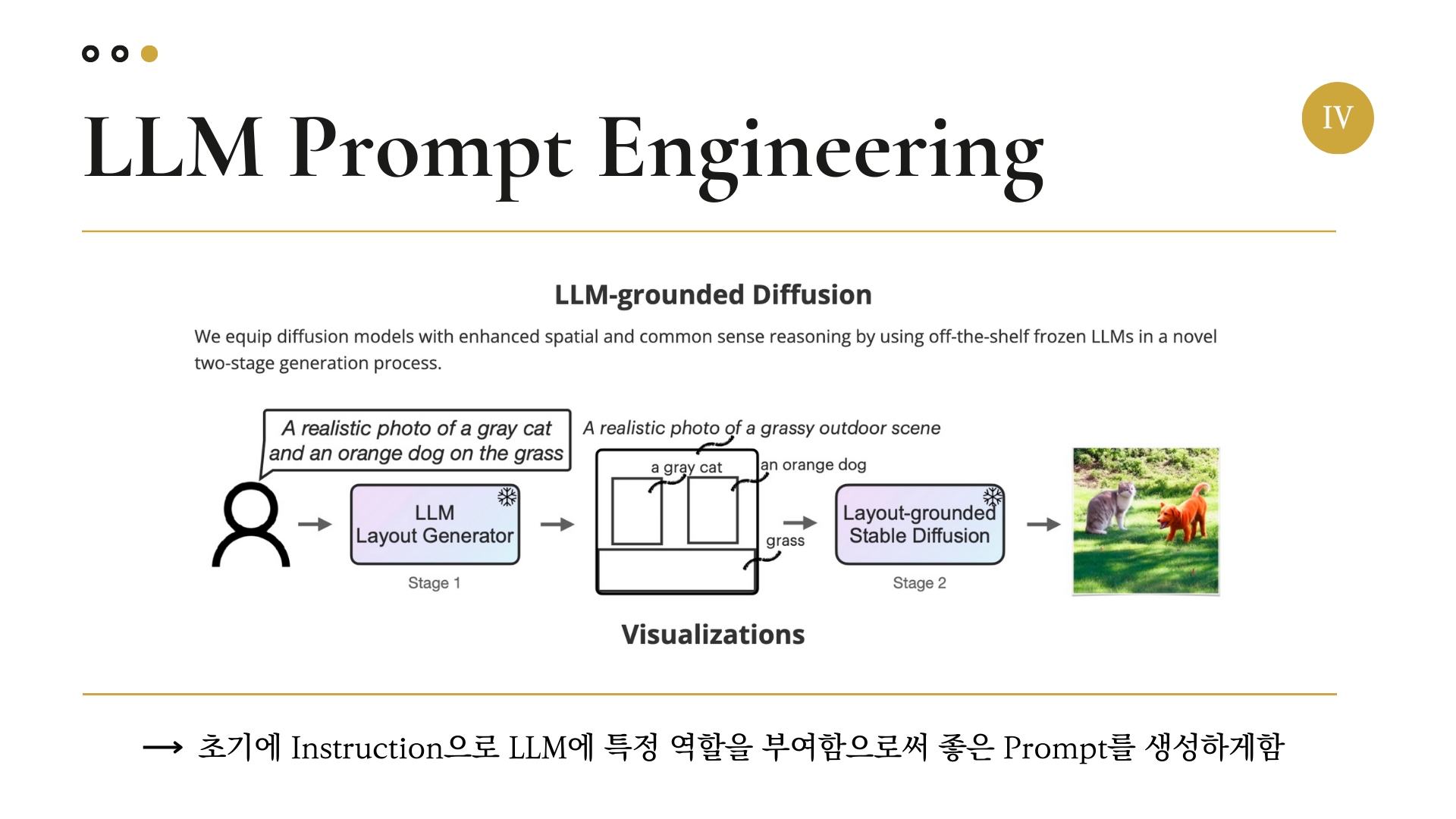
논문의 아이디어는 다음과 같다.
- 사용자가 Raw Prompt 입력
- 언어 모델이 Stable Diffusion Model에 입력할 프롬프트(레이아웃) 생성
- 이미지 생성
우리는 이 논문의 아이디어에 추가적으로 In-Context Learning의 기법인 Chain-of-Thought를 응용하여 Prompt Engineering을 수행하였다.

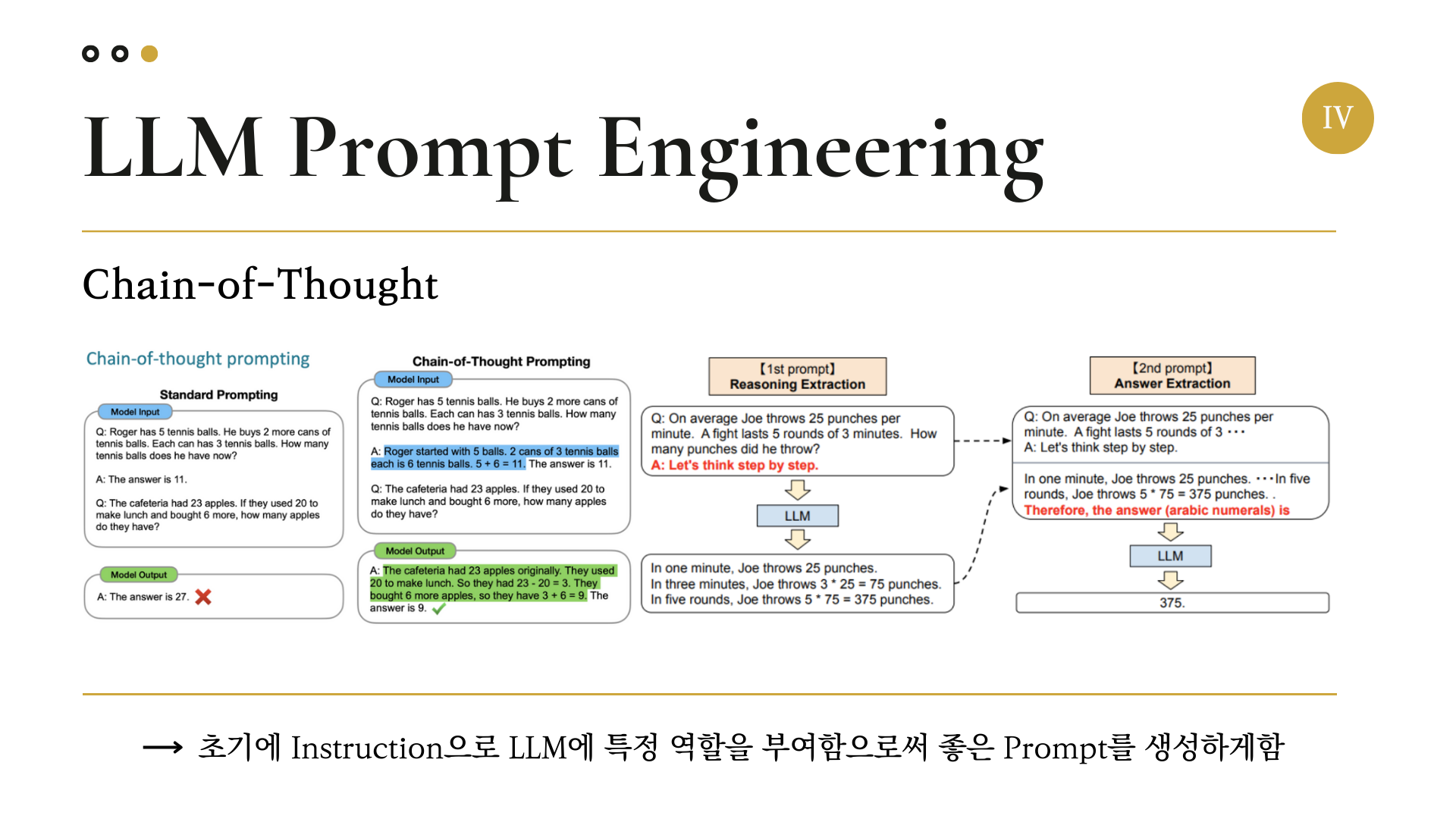
(Chain-Of-Thought에 대한 자세한 설명은 https://gyeongminsu.github.io/posts/Zeroshotlearning&Fewshotlearning/ 에 나와 있다.)
5. Segementation
모델 학습을 위해 입력받는 이미지에서, 배경 사진을 제외하고 강아지만 남기기 위해 Image Segmentation도 진행하였다.
우선 원본 이미지의 배경을 그대로 살린 채 앞서 설명한 Fine Tuning과 Inference를 진행하여 생성한 이미지는 아래와 같다.

이미지를 보면, 원본 사진에 있는 사람의 손이 생성된 이미지에서도 남아있는 것을 볼 수 있다.

즉, 이미지의 배경까지도 모델이 학습해버리는 현상이 발생하는 것이다.
따라서 우리는 이미지 안의 강아지와 배경을 분할하여 이미지에서 강아지의 정보만을 남기는 Segmentation을 진행하였다.
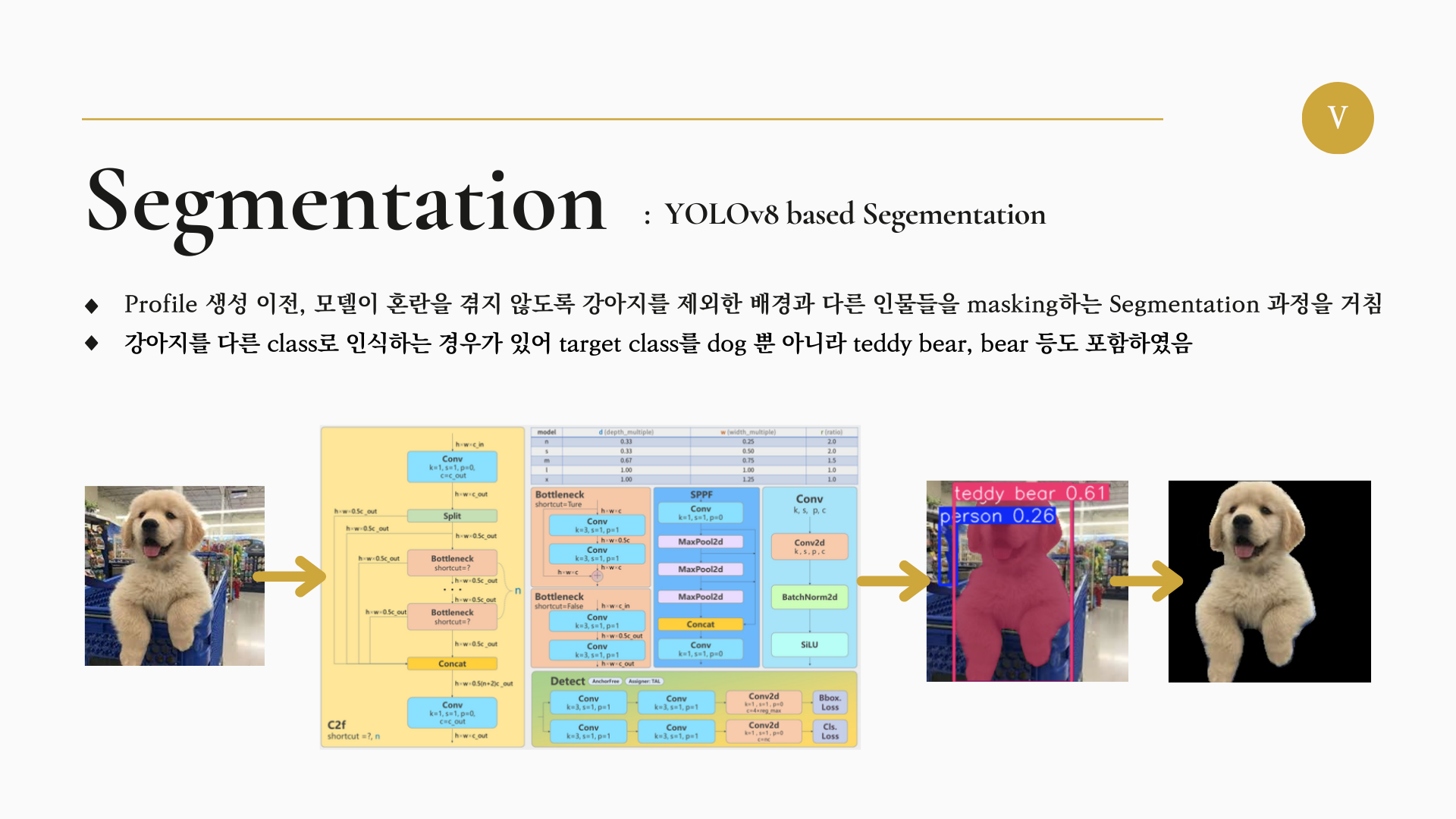
Segmentation을 위해선 Yolov8 모델을 이용하였다.
Yolov8 모델을 이용한 이유는 다음과 같다.
- 여러 복잡한 배경 사진에서 강아지의 index만을 추출하기 위해선 Yolo 계열 모델의 성능이 가장 좋음.
- Yolo 계열 모델 중에서 Segment를 위해 가장 활성화된 버전인 Yolov8을 이용.

결과적으로 강아지가 있는 부분만 Segment되어 모델에 입력되는 이미지는 다음과 같다.
6. Result


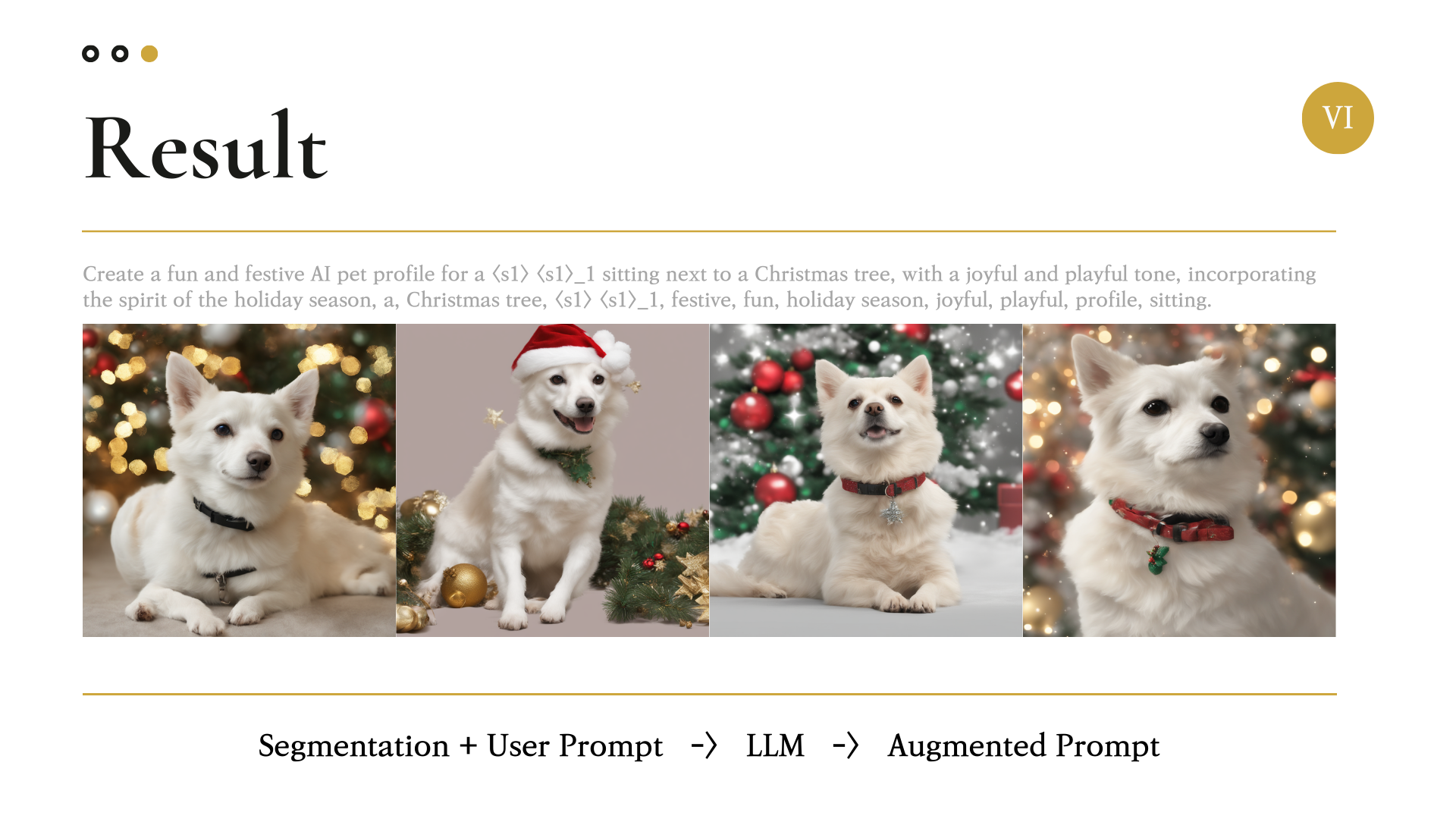
(너무 잘 만들어졌다!!!!!!!!!!)
7. Conclusion
7.1. Weakness

7.2. Future Work
향후 이 프로젝트에 더 적용해보면 좋을 것들이다.
7.2.1. Fine-tuning method of SDXL

https://arxiv.org/abs/2208.12242
https://arxiv.org/abs/2305.13301
https://arxiv.org/abs/2310.04378
강아지(’Dog’)의 정보를 반영하기 위해 우리는 Textual Inversion 기법을 이용하여 모델을 Fine Tuning하였다.
추가적으로 현재 계속 만들어지고 있는 여러 생성 모델 Fine Tuning 기법들을 적용하고 비교 및 분석해 볼 수 있을 것 같다.
7.2.2. Aligning Diffusion Model

https://arxiv.org/abs/2311.12908
https://arxiv.org/abs/2404.04465
언어 모델의 트렌드에 따라 Diffusion을 비롯한 생성 모델도 인간 선호도에 따라 Alinging하는 방법론이 많이 개발되고 있다. 이에 따라 우리의 생성 모델에 이런 기법을 추가해 볼 수 있을 것 같다.

다 같이 으쌰으쌰하며 고생해 준 멤버들에게 감사의 말씀을 전한다.
8. 소감 및 회고
저번 컨퍼런스에서 부족했다고 생각했던 점을 이번에 많이 보완하기 위해 나름 애를 썼지만, GPU를 사용할 수 있는 상황에서 한계가 존재했고 여러 안 좋은 상황이 맞물려서 컨퍼런스 전날까지 모델링을 위해 애를 썼던 것 같다.
생성모델, 특히 디퓨전 모델을 이용하는 프로젝트는 이번이 처음이여서 코딩하는 과정이 꽤 낯설었지만, 생성모델 관련하여 경험이 있는 팀원 덕분에 도움을 많이 받으면서 진행할 수 있었다.
막바지에 많은 시간과 노력을 들여 프로젝트의 완성도를 높이기 위한 경험은 매우 값진 것 같고, 이로 인해 또 한번 코딩 체급이 늘지 않았나 싶다.
어디가서 디퓨전 관련 생성 프로젝트는 찐하게 한 번 해봤다고 한마디 할 수 있을 것 같다.
Appendix
마지막으로 우리가 생성한 여러 가지 펫 AI 프로필 사진을 첨부하여 글을 마치겠다.
즐겁게 감상하시면 좋겠다.









