투빅스 19&20기 컨퍼런스 - RAG를 이용한 “투빅이 가이드 챗봇” 후기

투빅스 19&20기 컨퍼런스 : RAG를 이용한 “투빅이 가이드 챗봇” 후기
0. Introduction
23년 7월부터 20기로 활동을 시작한 대학생&대학원생 인공지능 및 빅데이터 대표 연합 동아리 투빅스에서 19&20기 컨퍼런스로 NLP 팀에서 프로젝트를 진행하였다.
이 게시글은 컨퍼런스 프로젝트에 대한 리뷰 및 설명하려는 목적으로 작성하였고, 발표 자료 사진과 함께 내용을 이어갈 것이다.
우리 팀은 컨퍼런스 중간발표까지 ‘연합학습 기반 XAI 프로젝트’를 기획하여 발표하고 연합학습(Federated Learning) 기반 LLM 모델링(KoBERT)까지 시도를 하였으나, 원하는 만큼 모델의 성능이 나오지 않았고 팀원들한테 주어진 모델 학습 리소스 환경에서 모델 학습을 지속적으로 하기 힘들다고 판단하여 RAG(Retrieval Augmented Generation)를 이용한 ‘투빅이 가이드 챗봇 프로젝트’로 주제를 전환하였다.
1. 아이디어 설계
투빅이 가이드 챗봇 프로젝트의 모티베이션을 설명하자면, 우선 투빅스의 데이터마켓과 Github organization에 아카이빙되어있는 투빅스 선배들의 양질의 활동 자료들(우수 과제 코드, 컨퍼런스 pdf 등등)이 많이 있는 것을 알 수 있다.
그래서 이런 자료들의 접근성을 높이고 신입 투빅이들의 투빅스 활동에 도움을 주기 위해 QA 챗봇 프로젝트를 만들기로 기획하였다.
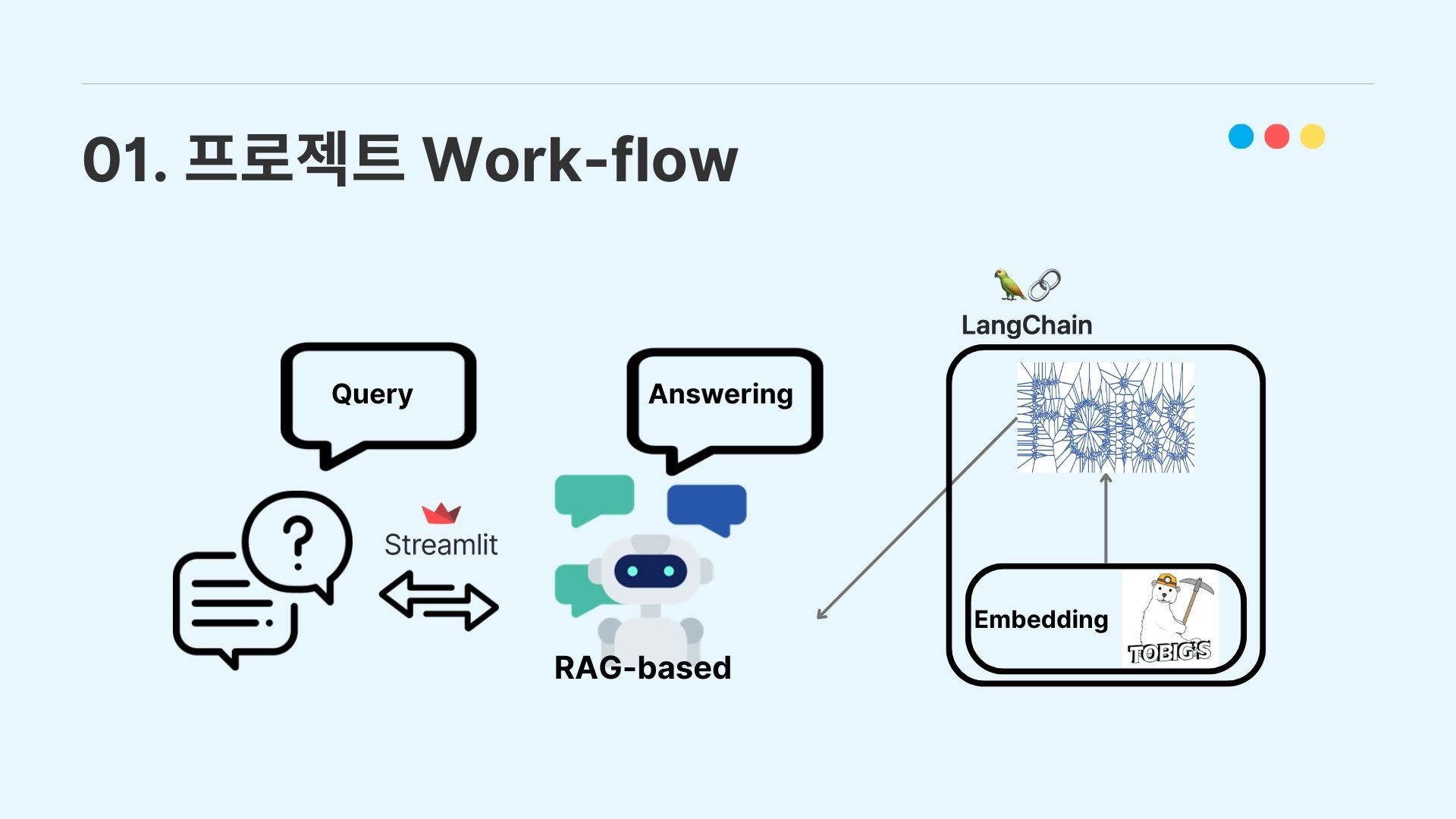
본 프로젝트의 전체적인 워크플로우는 위 사진과 같고, 이어지는 목차에서 더 자세히 설명하도록 하겠다.
2. 프로젝트 전체 구성
2-2. Open-domain QA

투빅스 활동 자료를 이용하기 위해 우리는 Open-domain QA를 구현하기로 하였다.
Open-domain QA는 LLM에 외부 지식을 입력해서 질문 쿼리에 대한 정답을 도출하는 시스템이고, 외부 지식을 직접 사용하기 때문에 사용자가 직접 외부 지식을 가공하고 업데이트할 수 있다는 장점이 있다.
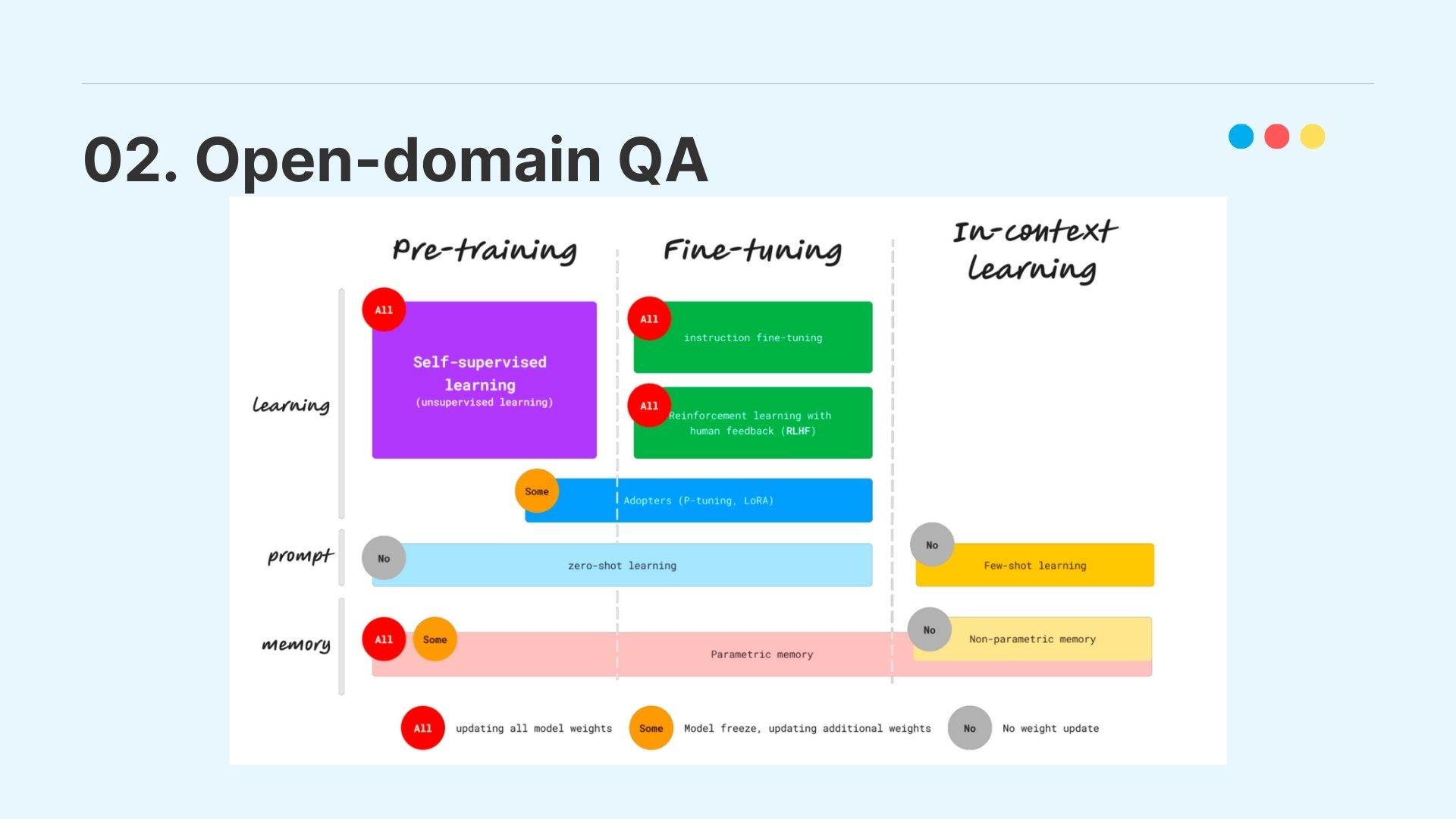
Open-domain QA에서 LLM을 학습할 때의 방식을 pre-training, Fine-tuning, In-context Learning 세 가지의 갈래로 나눌 수 있고, 우리는 이 타이틀 안에서 QA 구현을 위해 RAG, Fine-tuning, model-augment model의 총 세 가지 기법을 고민해 보았다.
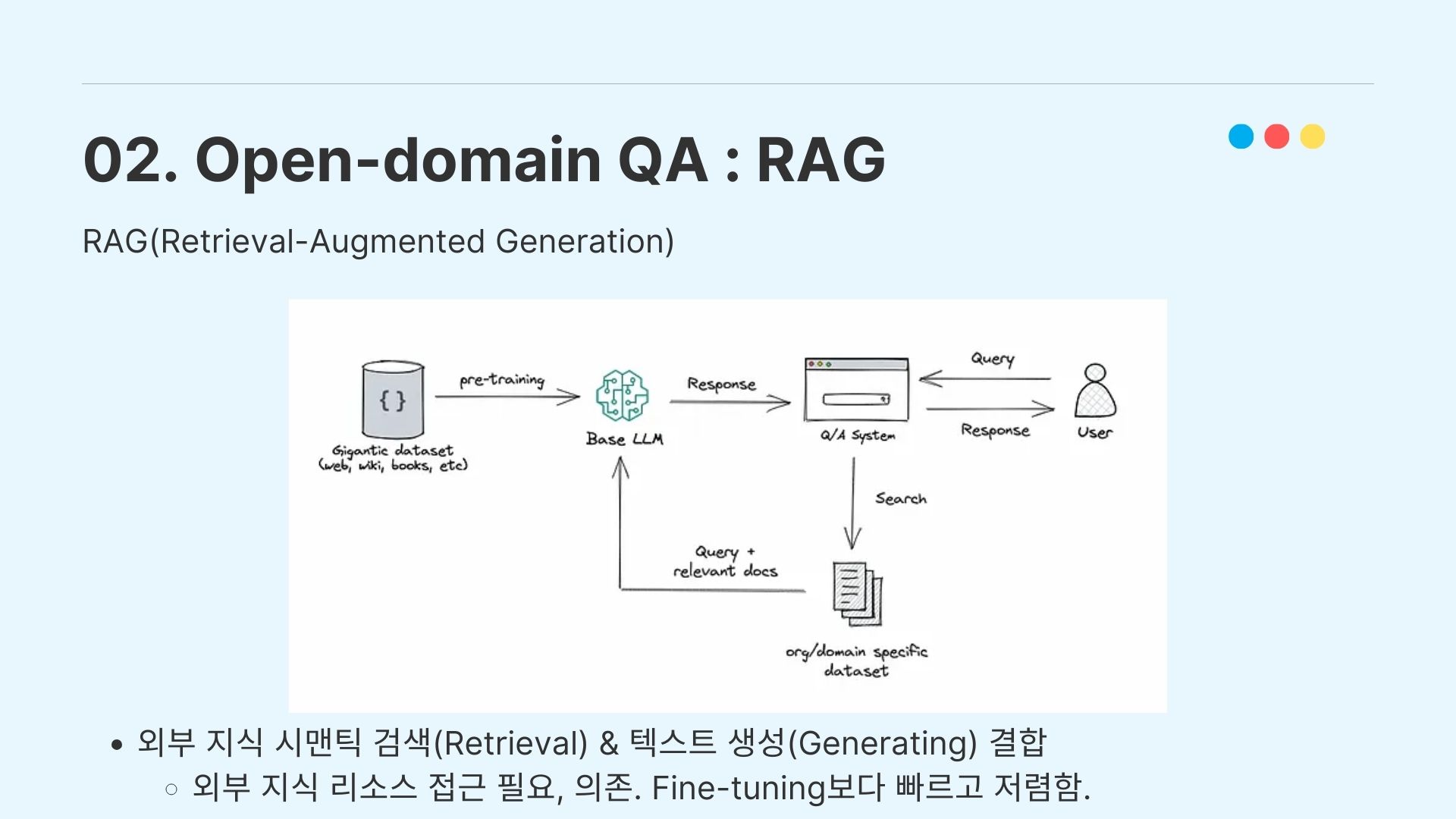
우선 RAG(Retrieval Augmented Generation)에 대해 살펴보았다. RAG는 외부 지식을 모델에 직접 추가해서 통합하는 게 아니라, 외부 지식의 embedding을 통해서 Input query가 던져졌을 때 데이터를 검색해서 llm이 이용하도록 하는 시스템입니다.
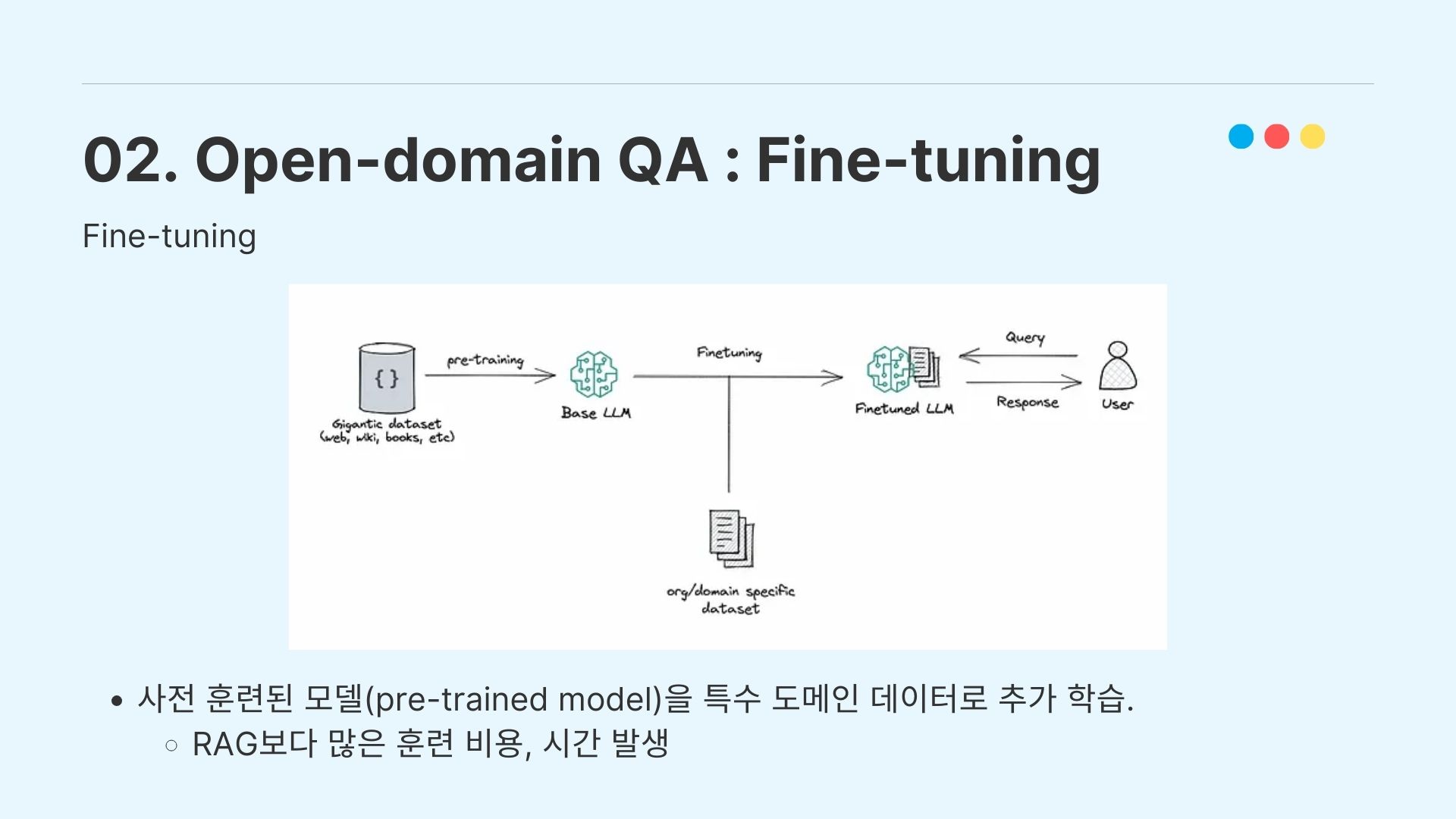
그에 반해서 LLM을 Fine-tuning하는 과정은 사전 훈련된(pre-trained) LLM에 외부 지식을 입력하여 parameter의 추가 학습을 진행시키는 시스템이고, fine-tuning을 이용할 경우 RAG보다 훨씬 많은 훈련 리소스와 시간이 발생한다.
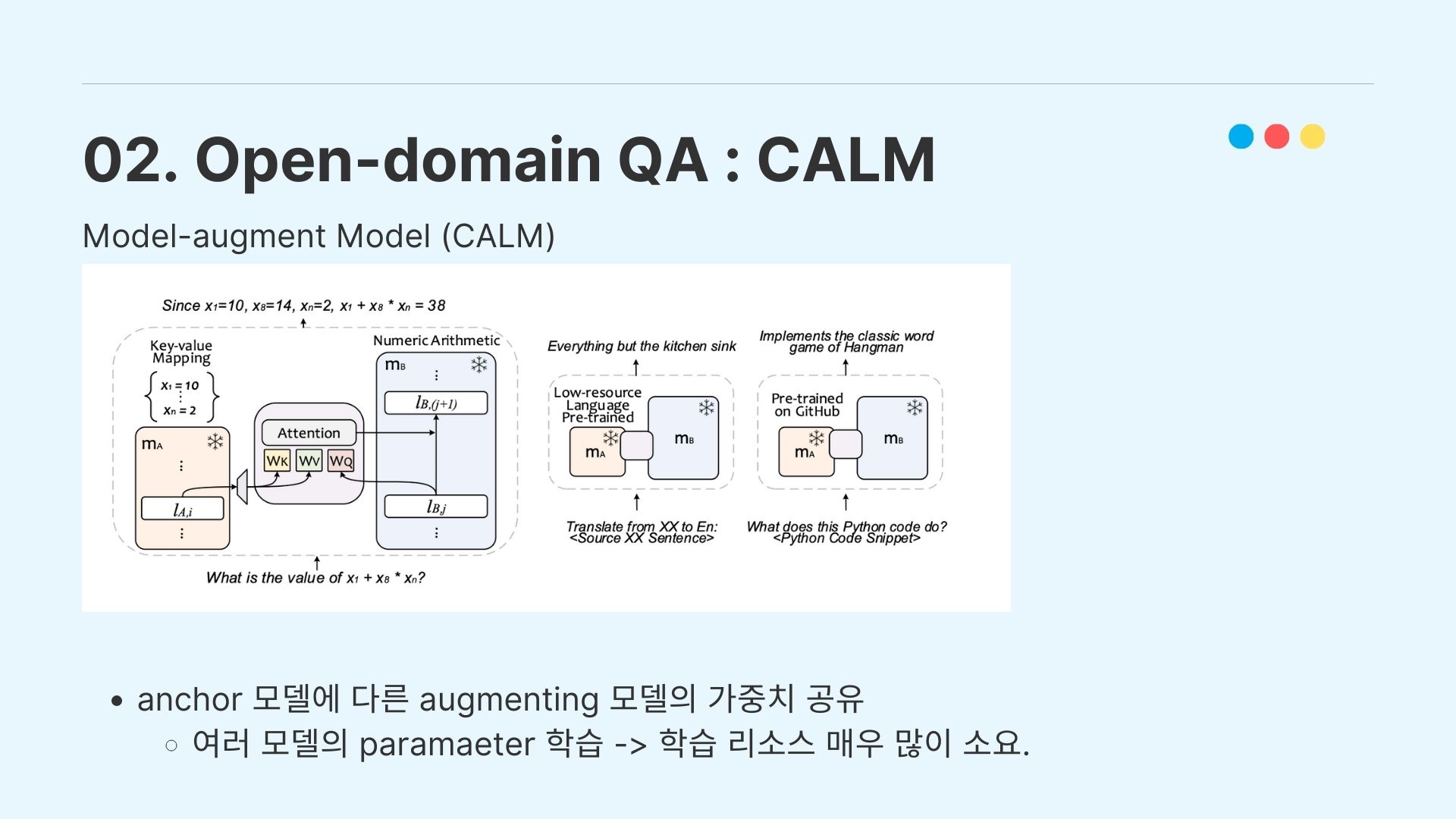
마지막으로 model augmented model의 CALM 학습 기법도 고민을 해봤으나, 논문에서 공개된 코드가 github 발표시간(24.01.13 14:00) 기준 4시간 전에 오픈됐고(https://github.com/lucidrains/CALM-pytorch) augmenting이 필요한 여러 모델의 사이즈가 너무 크기 때문에 모델 서빙에서 학습 리소스를 굉장히 많이 잡아먹는 작업이여서, 팀원들의 환경에서는 힘들다고 판단하였다.
2-2. RAG vs Fine-tuning
RAG와 Fine-tuning을 전부 진행하는 것이 바람직한 것은 모두가 알고 있다. 하지만 시간과 학습 리소스 상 우리는 RAG와 파인튜닝 중 어떤 방법을 선택해야 할 지 결정해야 했는데, 다음 6개의 기준을 만들어서 모델링 방식을 결정하였다.
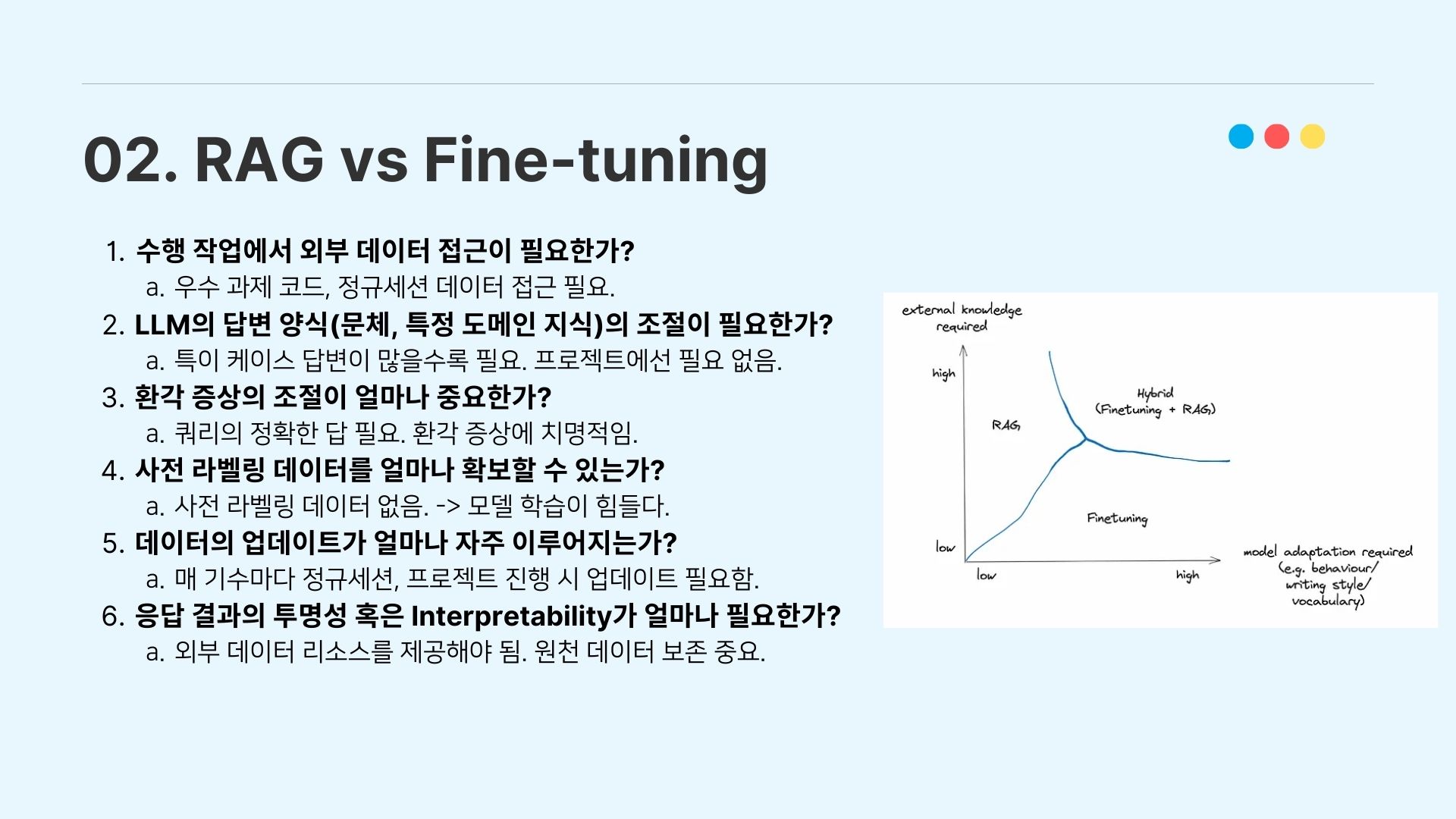
수행 작업에서 외부 데이터 접근이 필요한가?
→ 우수 과제 코드, 정규 세션에 대한 데이터 접근 필요.
LLM의 답변 양식(문체, 특정 도메인 지식)의 조절이 필요한가?
→ 특이 케이스 답변이 많을수록 필요. 본 프로젝트에선 필요 없음
환각(Hallucination) 증상의 조절이 얼마나 필요한가?
→ Input query에 대한 정확한 답 필요. 환각 증상에 치명적임.
사전 라벨링 데이터를 얼마나 확보할 수 있는가?
→ 사전 라벨링 데이터 없음 → 모델 학습(training)이 힘들다
- 데이터의 업데이트가 얼마나 자주 이루어지는가? → 매 기수마다 정규세션, 프로젝트 진행 시 업데이트 필요함.(3개월 주기)
응답 결과의 투명성 혹은 Interpretability가 얼마나 중요한가?
→ 외부 데이터 리소스를 제공해야 한다. 원천 데이터 보존 중요.
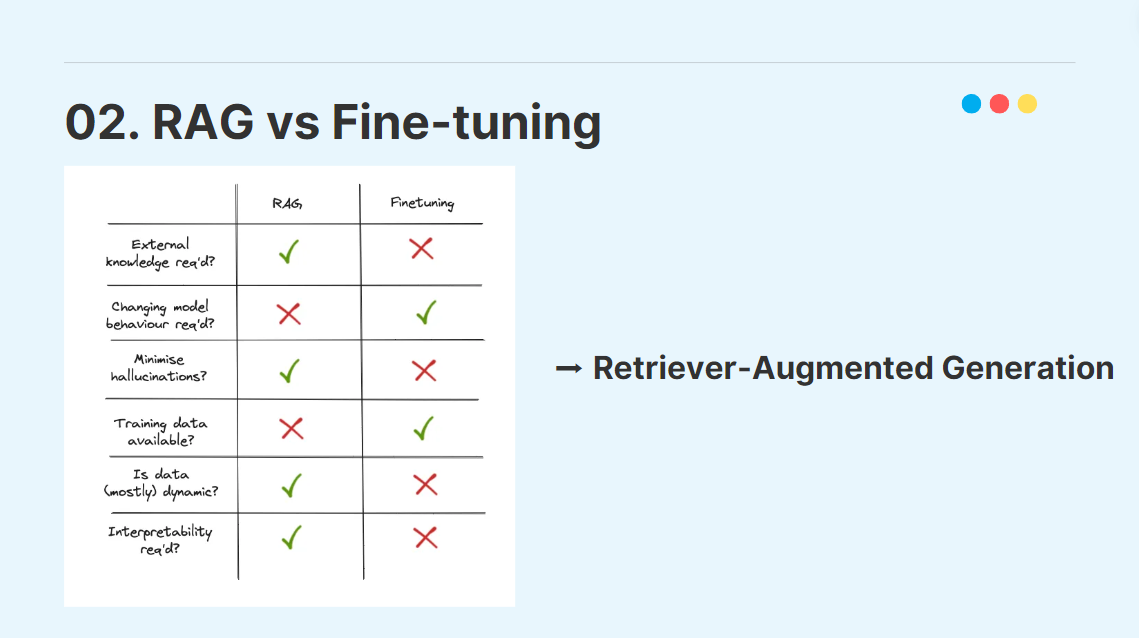
이러한 사고과정 끝에, 우리는 RAG를 이용하여 Open-domain QA chatbot을 만들기로 결정하였다.
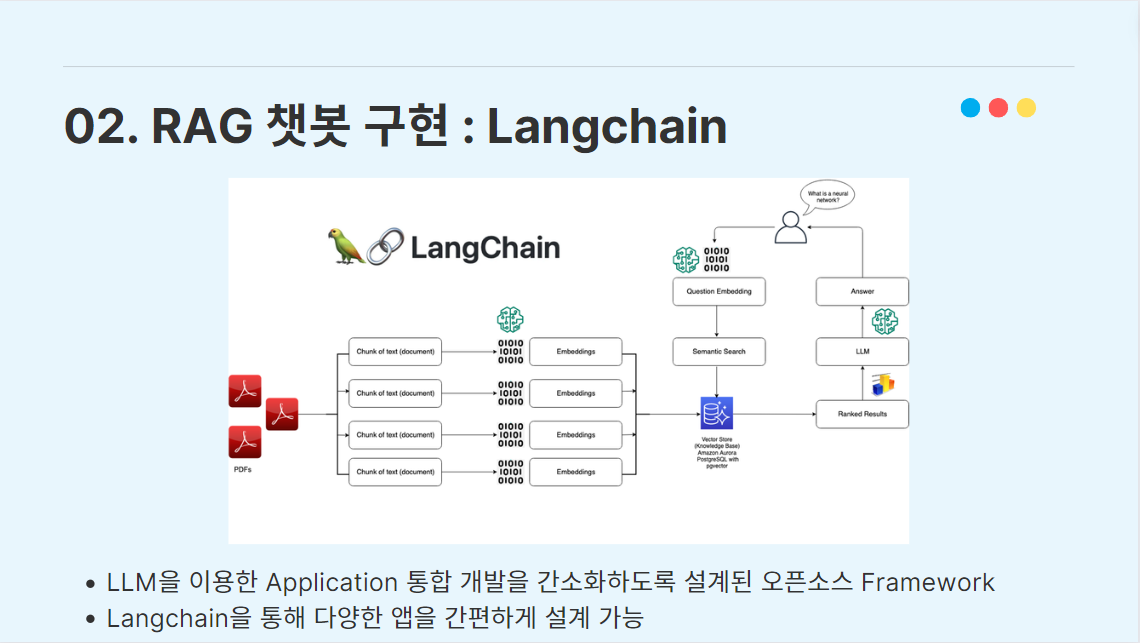
3. 챗봇 구현 과정
3-1. Externel data (외부 데이터)


모델 구현에 있어서 우리가 사용한 외부 데이터는 정규세션 우수 과제로 선정된 코드와 역대 컨퍼런스 발표 pdf 파일이고, 투빅스 데이터마켓과 Github organzation에서 데이터를 수집하여 79개의 과제 코드 파일과 71개의 컨퍼런스 pdf를 구하였다.
3-2. 데이터 전처리 과정
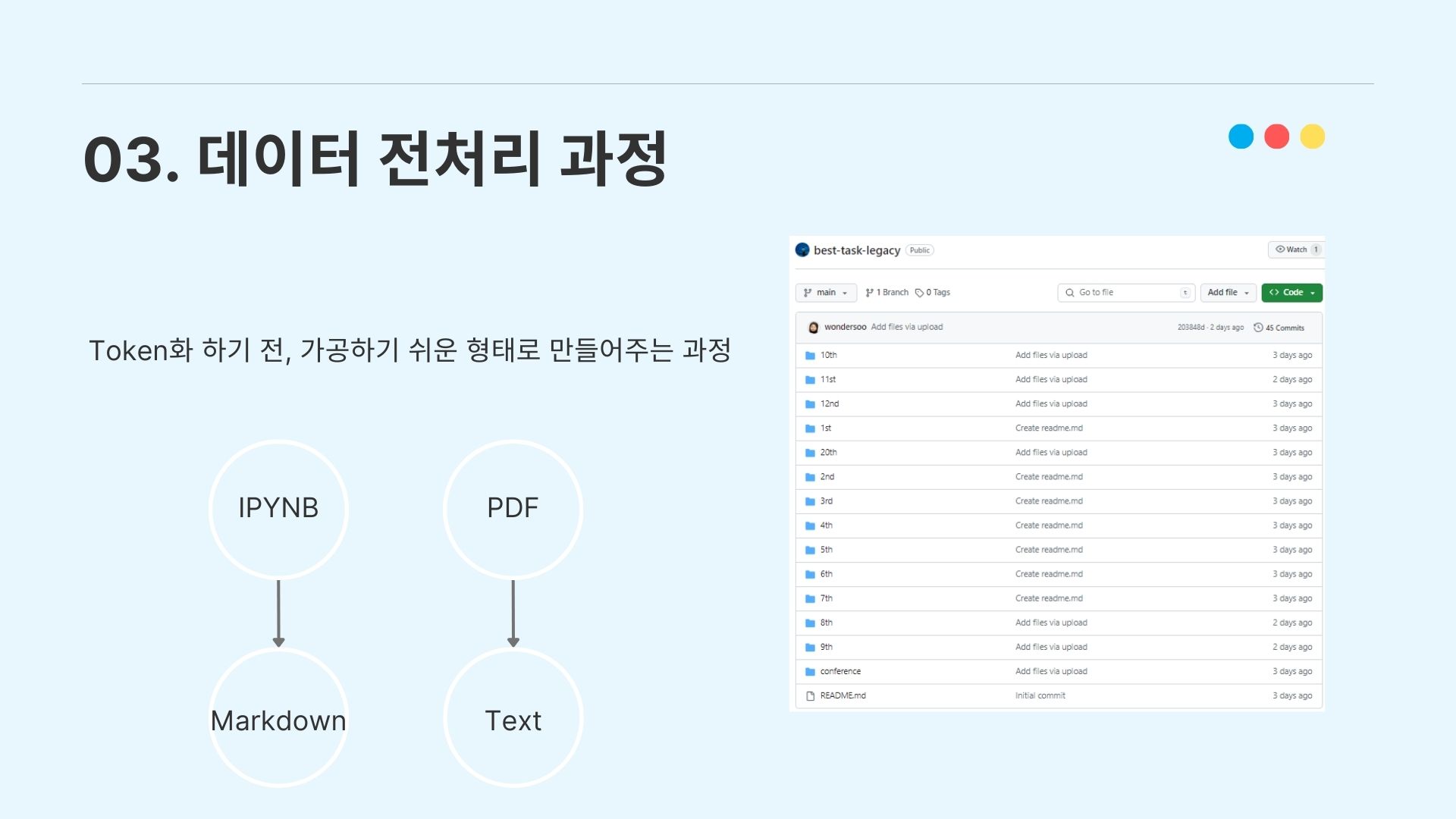
수집한 데이터를 전처리하는 과정을 설명하겠다. 우선 정규세션 코드의 ipynb 파일을 전부 텍스트화하기 위해 markdown으로 변환하는 작업을 거쳤고, 컨퍼런스의 pdf자료는 pdf 로더를 이용해서 텍스트화하는 작업을 진행하였다.
3-3. Tokenization & Embedding
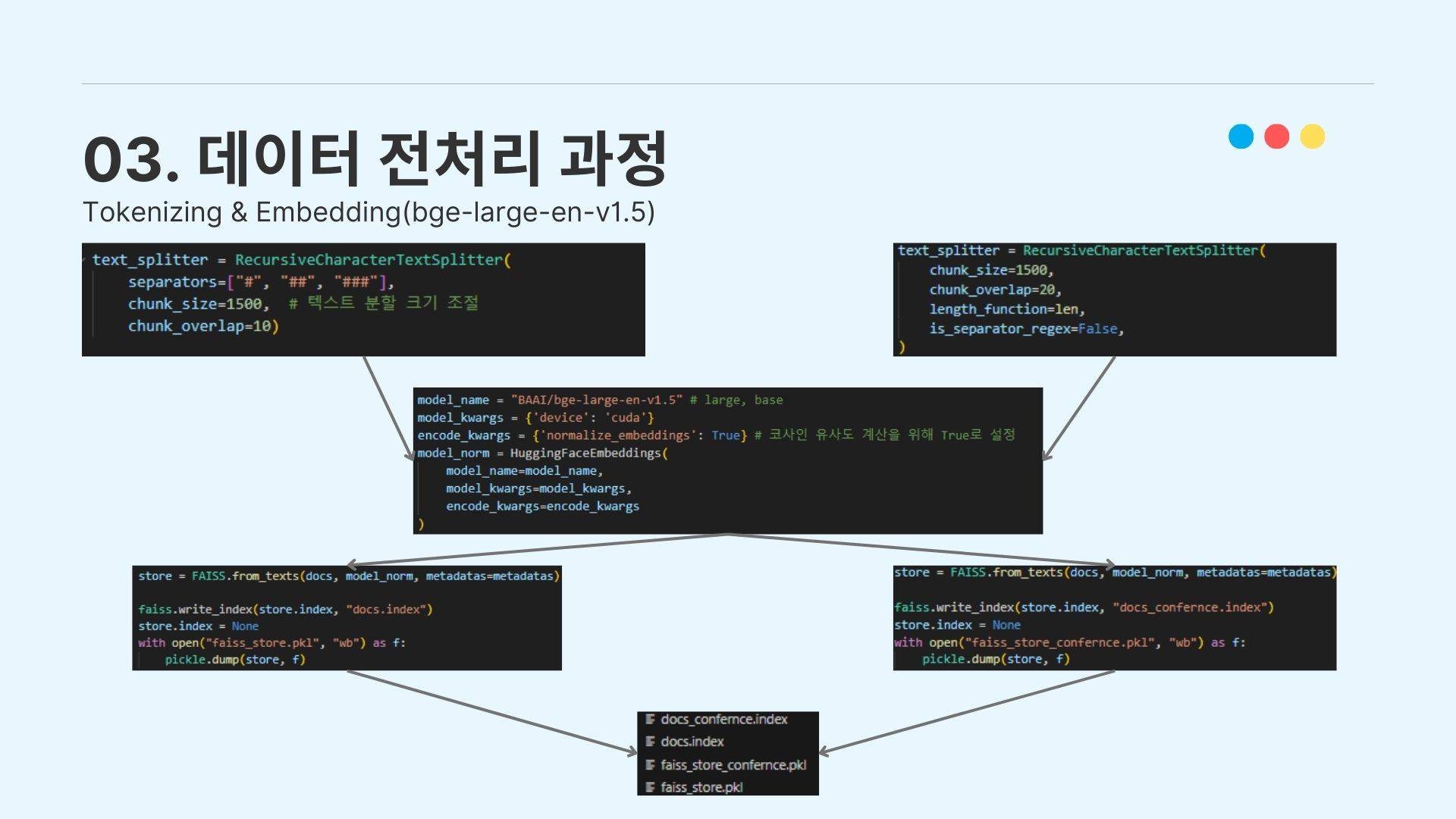
정규세션 우수 과제 코드에 대해서는 직접 지정한 구분 단위에 따라서 스플릿 진행을 위해 OpenAI API에서 제공하는 RecursiveCharacterTextSplitter를 이용하였다.
이렇게 만들어진 split 토큰을 임베딩하였다. 임베딩 모델로는 HuggingFace에서 Semantic-Search Retrieving 시스템을 구현할 때 높은 성과를 내고 있는 bge-large모델을 이용하였다.
3-4. Vector Store
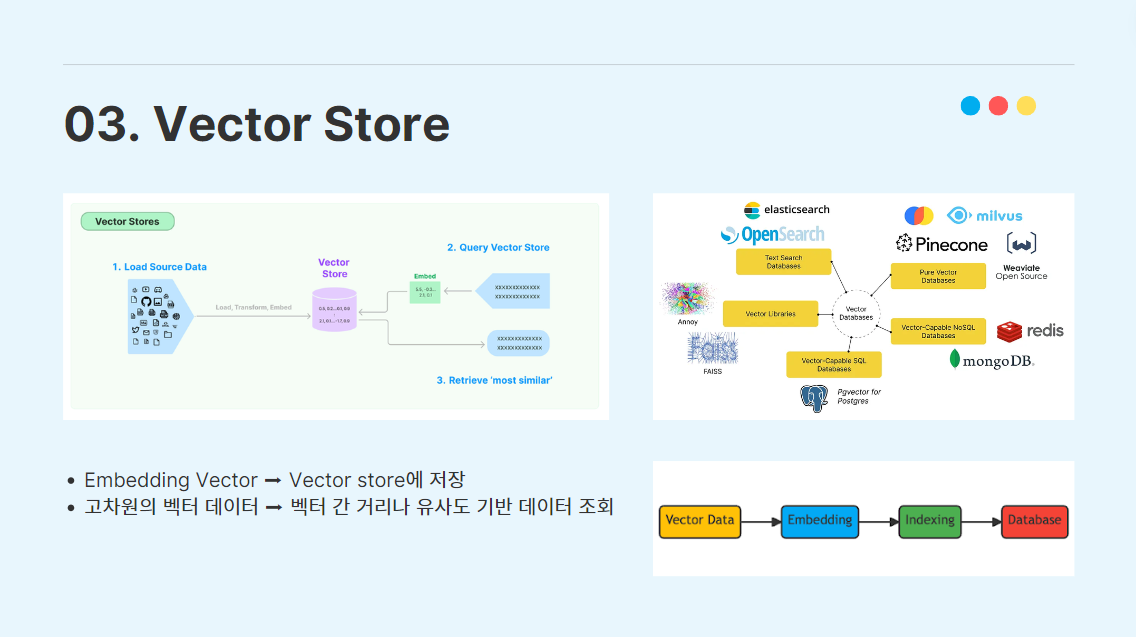
생성(Generation)을 위한 검색(Retrieving)을 진행하기 위해, 외부 데이터를 임베딩한 임베딩 벡터를 Vector Store에 저장하는 작업을 거쳐야 한다.
Vector Store는 고차원의 임베딩 벡터를 효율적으로 저장하고 조회할 수 있도록 설계된 데이터베이스이다. vector store는 전통적인 관계형 데이터베이스(RDBMS)와는 다르게, 벡터 간의 거리나 유사도를 기반으로 데이터를 조회하는 형식이다.

이미 시중에 여러 종류의 Vector database 라이브러리가 존재하고, 여러 사람들이 많이 사용하고 있는 추세다. 그 중에서 우리는 Facebook AI Research 팀에서 개발한 FAISS(Facebook AI Similarity Search)를 이용하였다.
FAISS는 벡터 양자화(Vector quantization)와 ANN(A-Nearest Neighbor) 알고리즘으로 인덱싱을 진행하고, ANN 알고리즘에서 HNSW와 Skip list를 이용해서 효율성을 높이는 장점이 있는 Vector Store이다.
자세한 설명 : https://pangyoalto.com/faiss-1-hnsw/
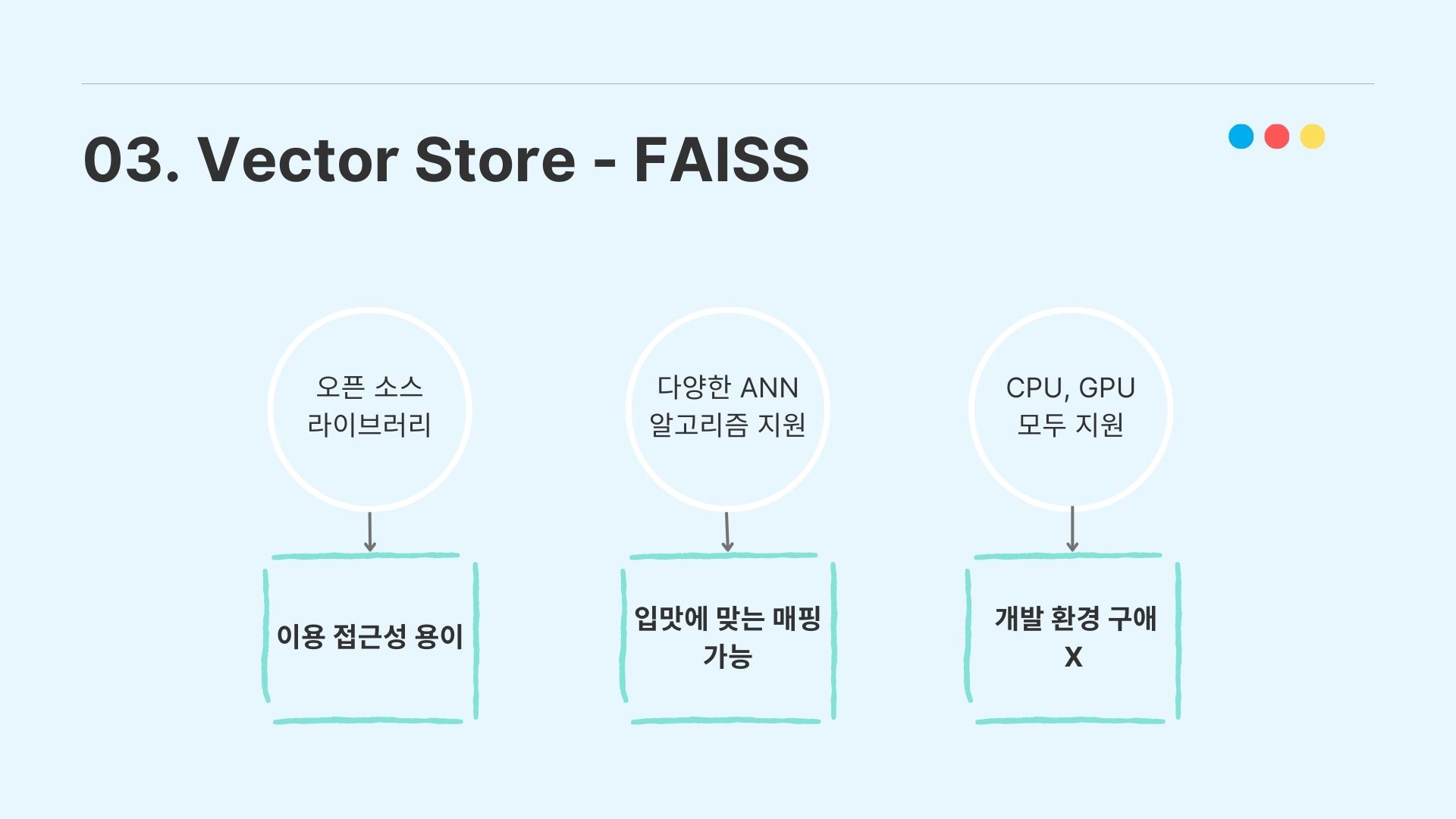
우리가 FAISS를 선택한 근거는 첫번째로 오픈소스 라이브러리이므로 이용 접근성이 용이하고, 다양한 ANN 알고리즘을 지원하므로 입맛에 맞는 매핑이 가능하다. 그리고 CPU와 GPU 계산을 모두 지원해서 개발 환경에 구애받지 않는다는 점 때문에 FAISS를 채택하였다.
3-5. LLM : Llama 2 vs GPT-4
그렇게 Vector Store에 저장된 임베딩 벡터를 pre-trained LLM에 입력해주어야 하는데, 우리는 이용할 LLM으로 현재 SOTA 퍼포먼스를 보이는 Llama 2와 GPT-4를 놓고 고민하였다.
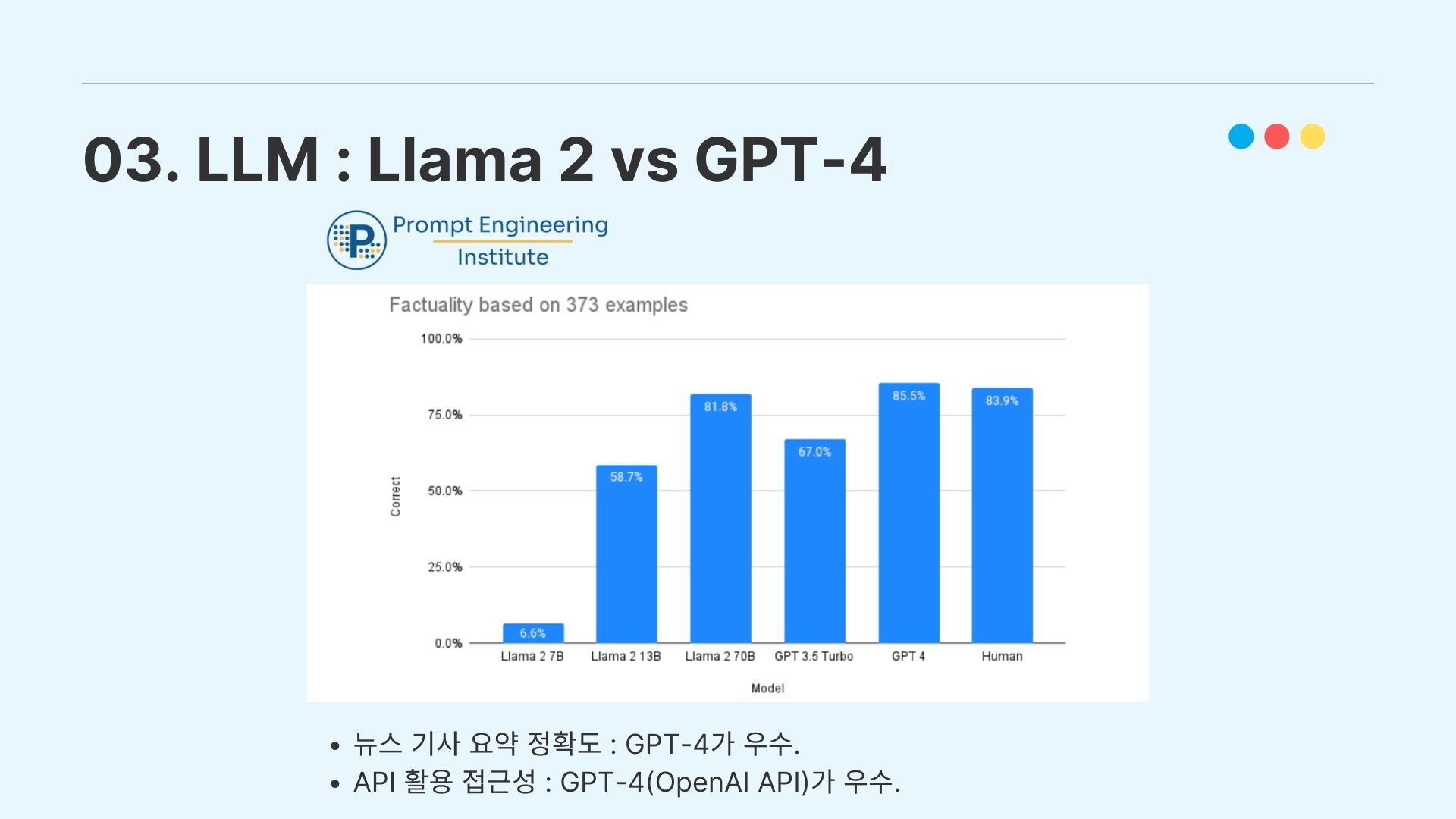
그런데 Prompt Engineering이라는 단체에서 LLM을 이용하여 뉴스 기사 요약 정확도 측정 실험을 했을 때 GPT-4가 더 우수한 성능을 보였고, API 활용 접근성에서 GPT의 OpenAI API가 더 더 높은 활용성을 보여준다고 판단하여 우리는 GPT-4를 선택하였다.
LLM을 prompting하는 데 있어서 temperature 변수는 모델이 선택하는 토큰의 무작위성을 증가하는 변수이다.
temperature의 값이 낮을수록 사실적이고 간결한 응답을 얻을 수 있고(가장 확률이 높은 토큰만 선택, 더욱 결정론적인 결과), temperature의 값이 높을수록 LLM은 더욱 다양하고 창조적인 Output을 생성한다(다른 토큰의 가중치를 증가시킨다).
4. 결과 시연, 한계점 & 발전 가능성
4-1. Streamlit 결과 시연
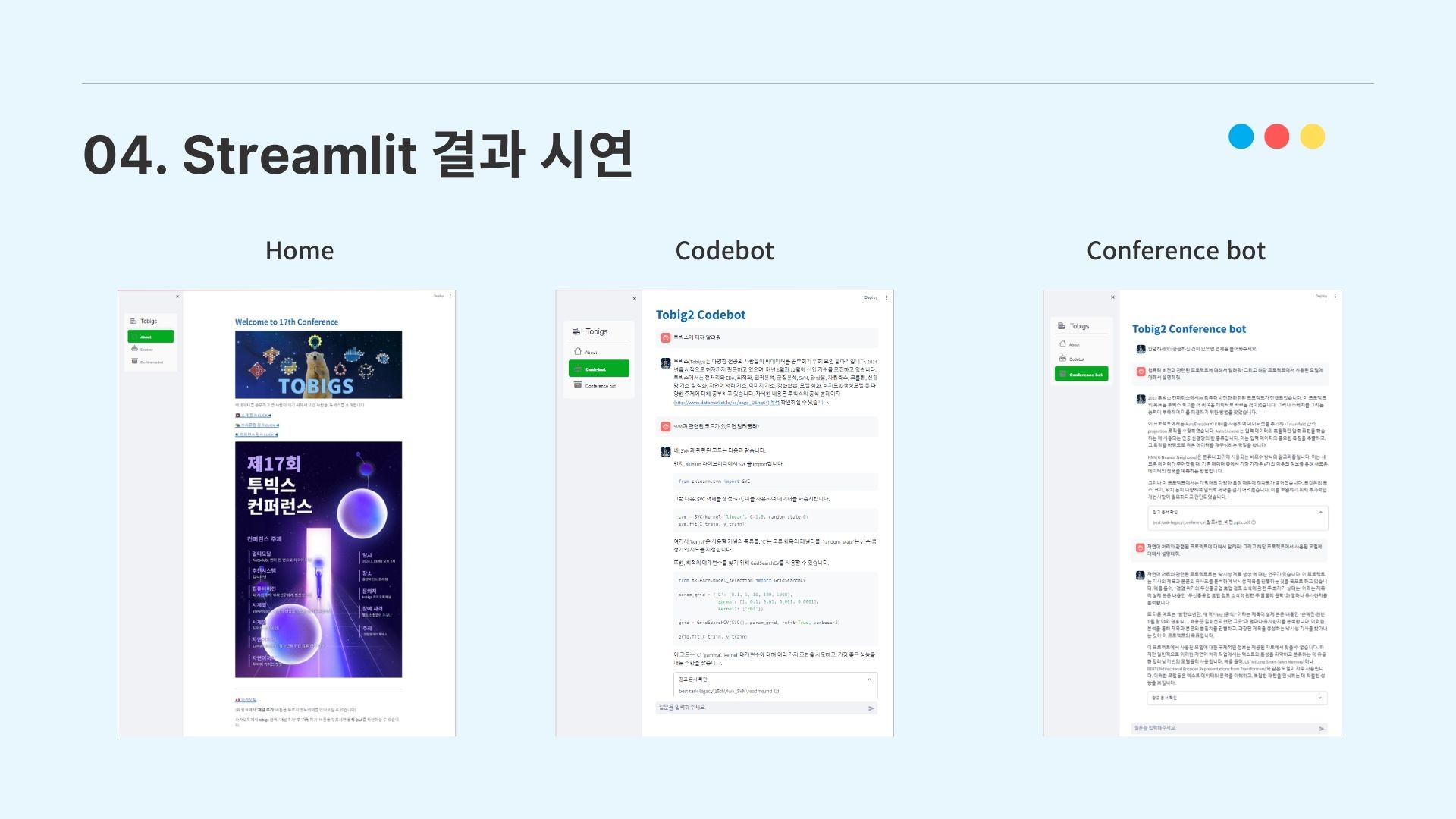
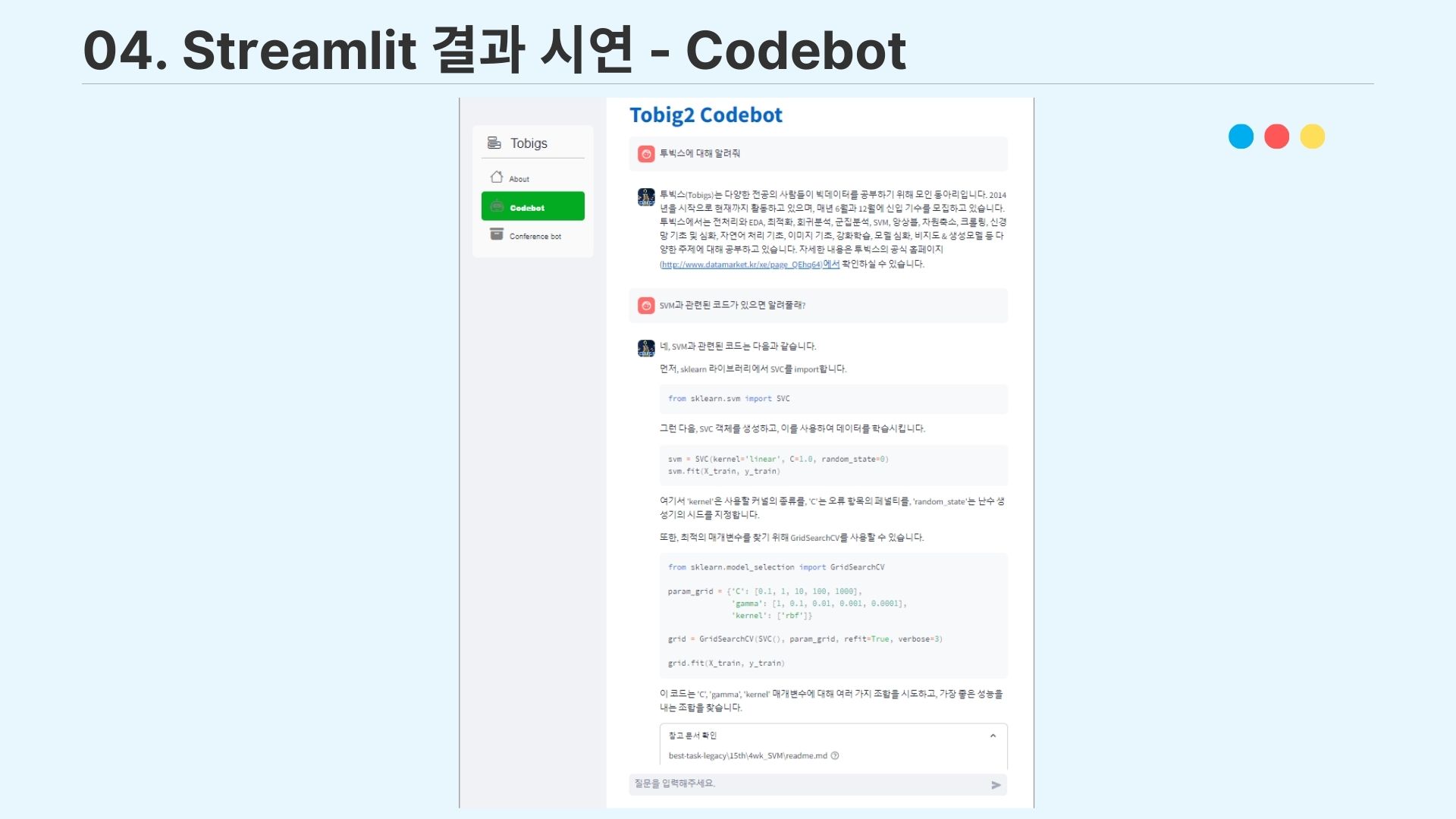

이렇게 완성한 QA 챗봇을 streamlit을 이용하여 간단하게 UI로 구현하였고, 시연을 완료하였다.
4-2. 한계점 & 발전 가능성

우리가 생각한 한계점과 발전 가능성의 내용은 위의 사진과 같다.
5. 소감 및 회고
이렇게 투빅스에서 진행한 첫 컨퍼런스 프로젝트를 마무리하였다.
급하게 주제를 바꾸어 진행해서 시간이 촉박하여 아쉬운 점도 많았지만, 그럼에도 팀원들 모두 다 같이 노력해서 프로젝트를 잘 마무리할 수 있었던 것 같다.
넓은 장소에서 수준 높은 동아리 멤버들을 청중으로 두고 발표하는 것도 생각보다 떨리는 경험이었다. 급하게 현장에서 대본을 만들면서 발표 직전까지 매우 긴장하였지만, 막상 단상에서 발표를 진행할 땐 대본도 보지 않고 발표 프레젠테이션만 보면서 라이브로 발표를 진행했던 것 같다.
말을 하면서 발표할 땐 막상 하나도 떨리는 느낌이 없었고, 지금까지의 경험으로 미루어보아 무대 체질이 어느 정도 있는 것 같다는 생각을 하였다.
프로젝트에 참여한 팀원들 모두 투빅스 멤버인만큼 훌륭한 분들이셨지만, 소통 부재로 인한 계획 차질이 생기기도 했었기에 다음 컨퍼런스를 진행할 땐 좀 더 체계적으로 일정을 계획하고 소통을 진행할 필요성을 느끼기도 했다.
다음 프로젝트 주제로는 아마 멀티모달을 선택할 것 같다. 개인적으로 요즘 SSM(State-Space Model)에 관심이 높아져서, SSM을 이용한 멀티모달 프로젝트를 진행해보고 싶다는 생각이 든다.