Sound-Guided Semantic Image Manipulation (CVPR 2022) 논문 리뷰
Sound-Guided Semantic Image Manipulation (CVPR 2022) 논문 리뷰
https://arxiv.org/abs/2112.00007
0. Abstract
연구 배경
최근 생성 모델의 성공은 Multi-modal embedding space를 활용하여 텍스트 정보를 사용해 이미지를 조작할 수 있다는 가능성을 보여주고 있다.
그러나 텍스트 외의 다른 소스(예: 소리)를 사용하여 이미지를 조작하는 것은 해당 소스의 동적(dynamic)인 특성 때문에 쉬운 task가 아니다. 특히 소리는 현실 세계의 생생한 감정과 동적 표현을 전달할 수 있다.
본 논문에서는 소리를 멀티모달(image-text) embedding space로 직접 encoding하고, 해당 space에서 이미지를 조작(manipulate)하는 framework를 제안한다.
제안된 방법 및 구현
본 논문의 Audio encoder는 오디오 입력(Audio input)에서 잠재적 표현(Latent representation)을 생성하도록 훈련되었으며, 이는 이미지와 텍스트 표현과 정렬(align)된 Multi-modal embedding space에 맞도록 구성된다.
본 논문은 소리 기반 이미지 조작(sound-guided image manipulation)을 위해 정렬된 embedding에 기반한 직접적인 잠재 공간 최적화 방법(Direct Latent Optimization Method based on aligned embeddings)을 사용한다.
본 논문의 모델이 text와 audio 등 다양한 modality를 혼합할 수 있음을 보여주며, 이는 image manipulation의 다양성을 풍부하게 한다.
실험 결과
- Zero-shot audio classification과 Semantic-level image classification에 대한 실험 결과, 본 논문의 모델이 다른 text 및 audio-guided SOTA method들보다 우수한 성능을 보임을 보여주었다.
1. Introduction
Text-based image manipulation
생성 모델의 최근 성공은 Multi-modal embedding space를 활용하여 text information을 사용해 image를 manipulation할 수 있음을 보여준다.
사용자의 의도는 그림을 그리거나 텍스트를 작성함으로써 표현될 수 있다.
Problem of Text-based image manipulation
Text-based image manipulation은 소리의 의미를 이미지에 적용하는 데 한계가 있다. 소리는 무한한 변화를 가지는 연속적이고 동적인 특성을 지니기 때문이다.
Text(the discreteness)는 소리의 미세한 차이를 명확히 표현하는 데 제한이 존재한다. 예를 들어, “thunder”는 다른 크기와 특성을 가지며, “sound of thunder”는 소리의 세부적인 차이를 나타낸다.
우리의 일상 환경은 다양한 소리와 복잡한 신호의 조합으로 가득 차 있다. 따라서 소리는 이미지의 조작을 위해 매우 중요한 요소로 작용한다.
Limitations of Previous Work
이전의 여러 연구는 소리의 의미를 시각화하려고 시도했지만, 이는 여전히 어려운 과제로 남아있다.
- 고해상도 이미지에서 소리의 사건(sound events)를 반영하는 것은 두 가지의 이유로 어려움이 있다.
- 적절한 고해상도 audio-visual dataset의 부족
- Audio-image modality 간의 잠재적 상관관계(potential correlation)를 추출하는 것의 어려움
- 소리와 이미지 간의 관계를 학습하는 데 있어 어려움을 극복하기 위해 소리의 의미를 이용한 새로운 image manipulation method를 제안한다.
Purpose of Paper
본 논문에서는 sound를 Multi-modal(image-text) embedding space에 직접 encoding하고 그 space에서 이미지를 조작하는 Framework를 제안한다.
본 논문의 Audio Encoder는 audio input으로부터 latent representation을 생성하도록 훈련도며, 이는 image 및 text representation과 align되도록 강제된다.
본 논문의 Framework는 text와 sound와 같은 다양한 modality를 혼합할 수 있어 image manipulation의 다양성(including temporal context, ton, volume)을 풍부하게 한다.
Main Attribution
- CLIP-based embedding space를 확장하기 위해 Multi-modal contrastive loss를 제안한다.
- Text와 sound의 조합을 통해 더 다양한 image manipulation이 가능함을 보여준다.
- Zero-shot audio classification 작업에서 SOTA(State-of-the-Art)의 성능을 보여준다.
- Adaptive layer masking을 통해 소리의 semantic information을 자연스럽게 반영할 수 있다.
2. Related Work
Text-guided Image Manipulation
- Text-guided image manipulation은 가장 널리 연구된 분야 중 하나이다. 이전의 여러 연구들은 text description과 일치하는 방식으로 image를 수정하기 위해 GAN-based encoder-decoder 구조를 사용하였다.
- 이러한 연구들 중 StyleCLIP과 TediGAN은 사전 학습된(pre-trained) StyleGAN의 latent space와 CLIP model의 prior knowledge를 활용하였다.
- StyleCLIP은 사용자가 제공한 text prompt를 사용하여 image manipulation을 수행하고, TediGAN은 GAN inversion 기술을 사용하여 multi-modal mapping을 통해 image generation & manipulation을 가능하게 했다.
- Text와 image를 넘어, Sound는 장면의 더 복잡한 context를 표현할 수 있다. 더불어 Sound는 장면 안에서 발생하는 event와의 상관관계(correlation)가 존재한다.
Sound-guided Image Manipulation
Sound는 장면의 시간적 동적 정보(temporal dynamic information)를 포함하고 있으며, image manipulation의 source로 사용할 수 있다. 그러나 이전의 연구들은 주로 소리의 의미(sound semantics) 대신 음악에 초점을 맞추고 있으며, 음악에서 시각적 스타일로의 transfer와 같은 cross-modal style transfer를 포함한다.
음악에서 image로의 Style transfer을 시도한 연구들 중 TraumerAI는 음악을 StyleGAN의 style embedding으로 mapping하여 음악의 시각적 표현을 수행하였다. 그러나 이들 연구는 style transfer에만 초점을 맞추고 있어 소리의 의미보다는 소리의 반응을 중시한다. 따라서 소리의 의미를 반영하는 데에는 한계가 있다.
반면에, 이 논문에서는 소리의 의미를 반영하여 이미지의 감정(emoticon of face)을 수정하면서도 머리 색상과 같은 원본 이미지의 특정 부분을 유지할 수 있다.
Interpreting Latent Space in StyleGAN
사전 학습된 StyleGAN의 Intermediate Latent Space는 생성된 이미지의 latent space의 변화에 따라 생성된 image를 의미 있게 조작(manipulation) 할 수 있도록 한다. 확장된 latent space $W+$는 사전 학습된 GAN generator로부터 해석 가능한 제어를 통해 imgae manipulation을 가능하게 한다.
Audio-reactive StyleGAN은 오디오 신호의 크기를 계산하고 이를 StyleGAN의 latent space에서 이동시켜 각 시간 단계마다 이미지를 생성한다. 그러나 이 방법은 latent space에서 소리의 의미를 제어할 수 없으며, 소리의 크기에만 mapping된다.
Audio-visual Representation Learning
Cross-modal representation learning은 비디오 검색(Video retrieval)과 같은 Audio-Visual task나 Image Caption 생성, 시각적 question answering과 같은 Text-Image cross modal 작업에서 서로 다른 modality 간의 관계를 얻는다.
Audio-visual representation learning에 관한 연구들은 두 modality(audio, visual)를 동일한 embedding space로 mapping하는 것을 목표로 한다. modality 간의 상관관계(correlation)는 복합 audio-visual 쌍 간의 contrastive learning을 통해 학습된다.
그러나 audio-visual representation learning은 여전히 어려움이 있다. 왜냐하면 CLIP처럼 modality 간의 상관 관계를 학습할 충분한 data가 없기 때문이다.
CLIP은 4억 개의 image-text 쌍을 사용하여 multi-modal self-supervised learning(자기 지도 학습)을 통해 image와 text embedding 간의 관계를 학습하였으며, 대부분의 image-text benchmark dataset에서 supervised learning과 비슷한 zero-shot inference 성능을 보여주었다.
이 논문에서 audio encoder는 CLIP의 표현력을 활용할 뿐만 아니라 self-supervised 방식으로 audio data 자체로부터 감독 신호를 학습한다. 그 결과, 논문의 방법은 sound-guided image manipulation을 위한 audio-specific representation을 얻는다.
3. Method
이 논문은 이미 존재하는 text-guided image manipulation model인 StyleCLIP을 따른다. 이 논문의 모델과 StyleCLIP은 modality 간의 joint embedding space를 사용하여 StyleGAN의 latent code를 조작한다.
그러나 이 논문의 모델은 이전에 embedding되지 않았던 audio embedding space로 CLIP embedding space를 확장한다. (기존에는 text & image만 embedding)
또한 이 논문에서는 sound-guided image manipulation을 위해 새로운 Contrastive loss(대조적 손실)와 Adaptive masking(적응형 마스킹)을 도입한다.
이 논문의 모델은 두 가지 주요 단계로 구성된다.
- CLIP-based Multi-modal Latent Representation Learning
- Sound-Guided Image Manipulation
먼저, 이 논문에서는 새로운 Latent Representation을 생성하기 위해 audio, text 및 image encoder를 훈련시킨다.
이를 위해 사전 학습된 CLIP의 text 및 image encoder로부터의 표현과 정렬된 latent representation을 생성하기 위해 InfoNCE loss를 사용하여 audio encoder를 훈련시킨다.
이러한 정렬된 표현은 제공된 audio input을 사용하여 image manipulation에 사용할 수 있다.
사전 학습 단계 이후, 우리는 encoder를 사용하여 목표 소리 입력에 따라 image를 조작한다. (예 : 서로 다른 얼굴 표정을 가진 이미지 → 서로 다른 소리 입력으로 조작 가능)
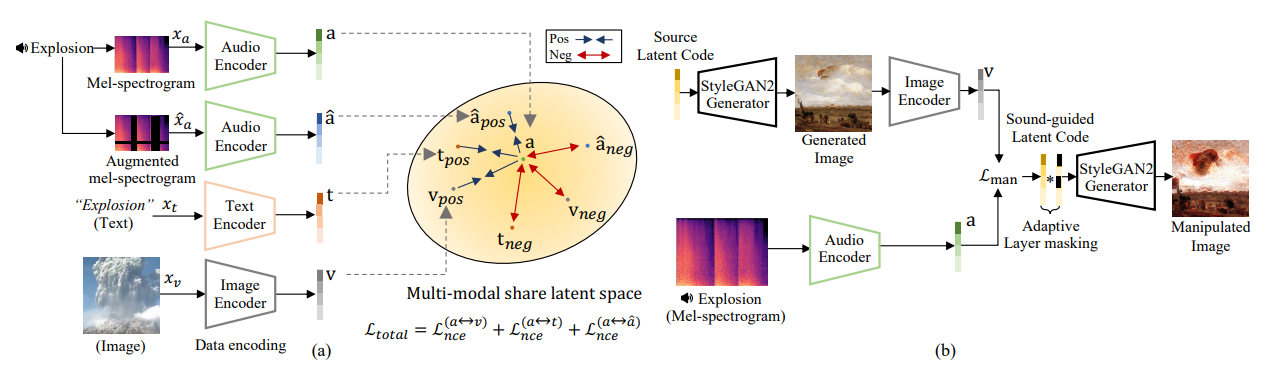
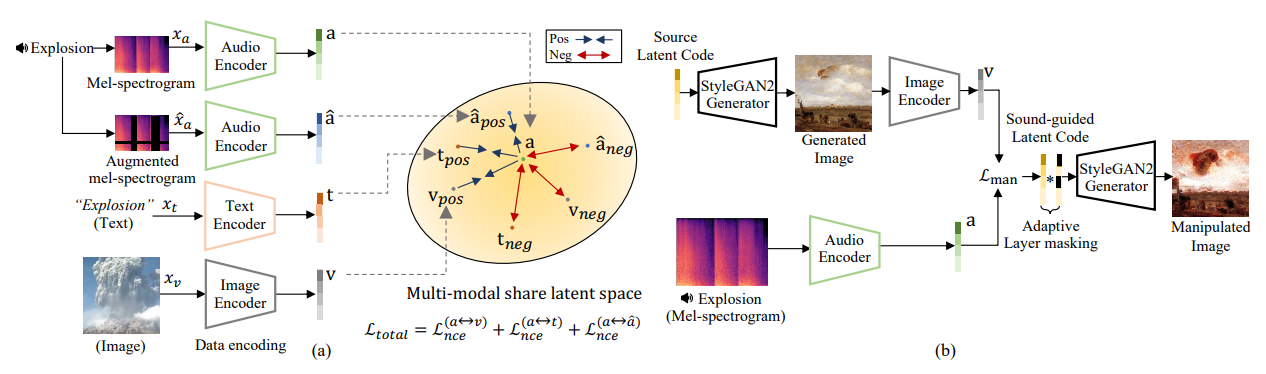
모델의 전체적인 구조도는 위와 같다.
3.1. Multi-modal Latent Representation Learning
- Audio, Text, Image의 세 가지 다른 Modality에 대한 Encoder set를 훈련한다.
- 이 Encoder들은 공통 embedding space에서 latent representation을 생성하여 audio input을 text 및 시각적 의미와 align한다.
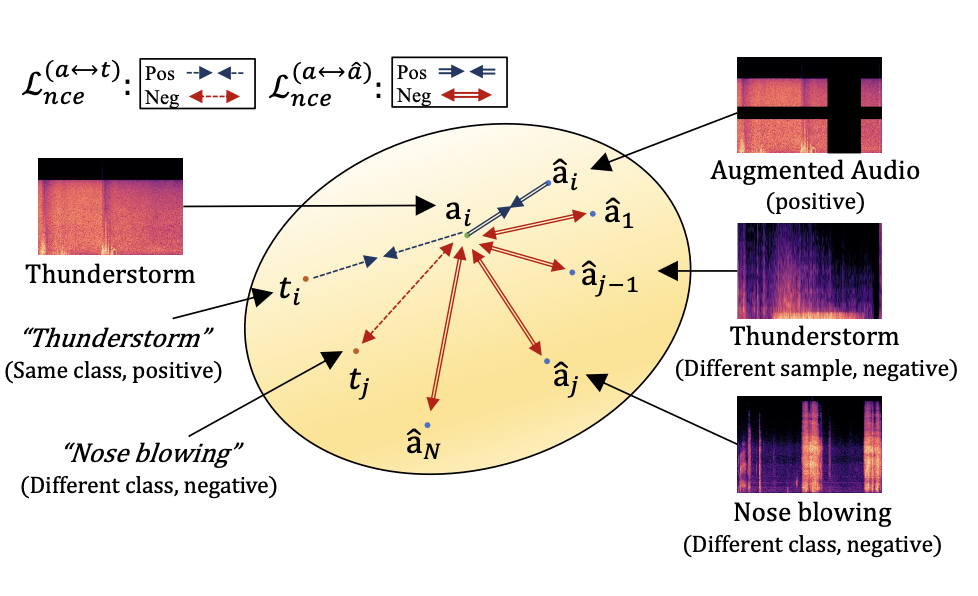
Matching Multi-modal Representations via Contrastive Loss
- Audio, Text, Image input $x_a, x_t, x_v$가 주어지면, Encoder는 각각 $d$차원 공간 $\R^d$에서 Latent representation $a, t, v$를 생성한다.
Constrative Loss
InfoNCE Loss를 사용하여 audio와 text embedding을 CLIP-based embedding space에서 정렬(align)한다. positive-pair는 서로 가깝게, negative-pair는 서로 멀어지도록 학습한다.
What is InfoNCE Loss?
- “System”에 대한 현재 지식 상태를 가장 잘 나타내는 확률분포 = 가장 큰 엔트로피를 갖는 분포”라는 원리인 최대 엔트로피 원리에 기반하여 대조 학습(Constrative Learning)에서 사용되는 손실 함수.
- 주어진 input pair의 embedding이 얼마나 일치하는 지 측정하며, 주로 자가 지도 학습(Self-Supervised Learning)과 비지도 학습(Unsupervised Learning)에서 사용된다.
Audio-Text pair Loss Function
$l_{i}^{(a \to t)} = -\log \frac{\exp(\langle a_i, t_j \rangle / \tau)}{\sum_{j=1}^N \exp(\langle a_i, t_j \rangle / \tau)}$
- $\langle a_i, t_j \rangle$ : cosine similarity를 나타내며, 이는 $a_i$와 $t_j$의 내적이다.
- $\tau$ : 온도 하이퍼파라미터로, 내적 값의 scale을 조절한다.
- 이 Loss function은 $N$-방향 분류기의 로그 손실로 해석될 수 있으며, ${a_i, t_j}$를 실제 표현 쌍으로 예측하고자 한다.
Text-Audio pair Loss Function
$l_{i}^{(t \to a)} = -\log \frac{\exp(\langle t_i, a_j \rangle / \tau)}{\sum_{j=1}^N \exp(\langle t_i, a_j \rangle / \tau)}$
- 이 손실 함수는 텍스트 $t_i$와 오디오 $a_j$의 cosine similarity를 사용하여 정의된다.
Audio-Text 간의 총 Constrative Loss = Final Loss Function
구체적으로, 각 minibatch 크기 N에서 모든 positive audio-text representation pair에 대해 위의 두 손실을 합산하여 다음과 같은 최종 손실 함수 $L _{nce}$를 최소화한다.
$L_{nce}^{(a \leftrightarrow t)} = \frac{1}{N} \sum_{i=1}^N (l_{i}^{(a \to t)} + l_{i}^{(t \to a)})$
Applying Self-supervised Representation Learning for Audio Inputs
Audio representation의 품질을 향상시키기 위해, 모델은 증강된 audio view 간의 constrative loss도 사용한다.
$L_{self}^{(a \leftrightarrow \hat{a})} = \frac{1}{N} \sum_{i=1}^N (l_{i}^{(a \to \hat{a})} + l_{i}^{(\hat{a} \to a)})$
Data Augmentation
- Audio input은 Mel-spectrogram 특징을 수정하는 SpecAugment를 사용하여 증강된다.
- Text input은 동의어 대체, 단어 순서 변경 및 무작위 단어 삽입으로 증강된다.
Loss Function
Encoder를 훈련하기 위해 최종적으로 minimize해야 하는 loss function은 아래와 같다.
$L_{total} = L_{nce}^{(a \leftrightarrow v)} + L_{nce}^{(a \leftrightarrow t)} + L_{self}^{(a \leftrightarrow \hat{a})}$
3.2. Sound-guided Image Manipulation
Direct Latent Code Optimization
이 단계는 audio input에 따라 이미지의 latent code를 최적화(optimize)하여 audio-guided image manipulation을 달성한다. 최적화 문제는 다음과 같이 정의된다.
$L_{man} = \arg \min_{w_a \in W^+} d_{cosine}(G(w_a), a) + \lambda_{ID} L_{ID}(w_a) + \lambda_{sim} | g \cdot (w_a - w_s) |^2$
여기서 주어진 source latent code $w_s \in W$는 StyleGAN의 intermediate latent space 내에 있으며, audio-guided latent code $w_a \in W^+$는 확장된 latent space에 속한다.
$\lambda_{sim}$과 $\lambda_{ID}$는 hyperparameter이다. $g$는 특정 style layer를 adaptive-masking하기 위해 정의된 학습 가능한 벡터이다. $L_{ID}$와 $G$는 각각 ID 손실 함수와 StyleGAN-based generator이다.
- Source latent code $w_s$ : 이는 $G$로부터 무작위로 생성된 latent code 또는 GAN inversion을 통해 기존 input image로부터 얻은 latent code일 수 있다.
이러한 최적화 방식을 통해, 우리는 조작된 이미지 $G(w_a)$와 audio input a의 embedding vector 간의 Cosine 거리를 최소화한다.
- Optimization Problem
- $d_{cosine}(G(w_a), a)$ : manipulated image $G(w_a)$와 audio input $a$의 embedding vector 간의 코사인 거리
- $L_{ID}(w_a)$ : ID loss function으로, 얼굴 인식을 위한 사전 학습된 ArcFace model을 사용하여 정의된다. 이는 조작된 이미지가 개인의 identity를 유지하도록 한다.
- $\lambda_{sim} | |g \cdot (w_a - w_s) | |^2_2$ : Layer별 masking을 통해 스타일 변경을 적응적(adaptive)으로 제어한다.
Direct Latent Code Optimization의 방식을 통해 manipulated image가 audio imput의 의미를 반영하면서도 원본 이미지와의 유사성을 유지하도록 한다.
Identity Loss
조작 중에 image의 identity를 유지한다.
Identity Loss function은 다음과 같이 정의된다.
$L_{ID}(w_a) = 1 - \langle R(G(w_s)), R(G(w_a)) \rangle$
- $R$ : ArcFace model (얼굴 인식을 위해 사전 훈련됨)
- $G$ : StyleGAN generator
- $w_s$ : source Latent Code
- $w_a$ : Audio-based Latent Code
$\langle \cdot\rangle$ : Cosine Similarity
- 이 loss function을 통해 ArcFace network의 latent space에서 인수 간의 Cosine Similarity인 $\langle R(G(w_s)), R(G(w_a)) \rangle$을 최소화한다.
- 이를 통해 개인의 identity를 변경하지 않고 얼굴 표정을 조작할 수 있다.
Adaptive Layer Masking
StyleGAN의 latent code의 layer를 적응적(adaptive)으로 masking하여 Style Transfer를 제어한다. 여기서 L2 regularization은 이동된 latent code로 생성된 이미지가 원본과 다르지 않도록 유지하는 데 효과적이다.
그러나 StyleGAN의 latent code는 각 layer마다 다른 특성을 가지므로, 사용자 제공 속성이 변경되면 각 layer에 대해 다른 가중치를 적용해야 한다. 우리는 Style latent code 내의 압축된 콘텐츠 정보를 유지하기 위해 layer별로 다른(layerwise) masking을 적용한다.
- StyleGAN2 : StyleGAN2에서 latent code는 $w \in R^{L \times D}$로 표현되며, 여기서 $L$은 Network layer의 수이고, $D$는 latent code의 차원 크기이다.
- 우리는 $L$차원의 파라미터 벡터 $g$를 선언한다. Direct Latent Code Optimization 단계에서 $g$와 $w$는 layer별로 곱해진다.
- $g$는 반복적으로 update되며, 이를 통해 latent code를 adative하게 조작한다.
Sound and Text Multi-modal Style Mixing
Audio와 Text 기반의 multi-modal image manipulation은 StyleGAN의 스타일 혼합을 기반으로 진행한다. StyleGAN의 latent code $w$의 다양한 layer는 각기 다른 속성(attribute)을 나타낸다.
Audio와 Text는 새로운 multi-modal embedding space를 공유하기 때문에, audio와 text로 guided된 각 latent code의 특정 layer를 선택하여 audio와 text의 속성을 projection하여 image를 manipulation할 수 있다.
4. Experiments
Implementation Details
모델 구성
- CLIP을 기반으로 Vision Transformer (ViT)를 image encoder로 사용하고 Transformer를 text encoder로 사용한다. 이 encoder들은 CLIP의 논문에서 사전 훈련된 모델을 사용한다.
- Audio encoder는 ResNet50을 사용한다. audio encoder의 출력 차원은 image & text encoder와 동일하게 512차원이다.
- 먼저 audio input을 Mel-spectrogram 음향 특징으로 변환한다. 그런 다음 audio encoder는 이러한 특징을 input으로 받아 512차원의 latent representation을 생성한다.
Manipulation
- StyleGAN2의 사전 훈련된 generator를 사용한다. 생성된 이미지의 해상도에 따라 latent code의 크기를 설정한다. 여기서 10241024 크기의 이미지는 18512, 256256 크기의 이미지는 14512로 설정한다.
Training setting
- 모델은 SGD(Stochastic Gradient Descent)와 cosine cyclic learning rate scheduler를 사용하요 50 epoch 동안 훈련된다.
- Learning rate = 1e-3
- Momentum = 0.9
- Weight decay = 1e-4
- Batch size = 384
Direct Latent Code Optimization
- 위에서 언급된 Direct Latent Code Optimization의 식에서 $\lambda_{sim}$과 $\lambda_{ID}$는 FFHQ dataset의 경우 각각 0.008과 0.004로, LSUN dataset의 경우 0.002와 0으로 설정된다.
4.1. Qualitative Analysis
Sound-guided Image Manipulation
- 논문의 Sound-guided image manipulation model을 기존의 sound-based style transfer model(TraumerAI, Crossing you in Style)과 비교한다.

- 논문의 모델이 더 높은 퀄리티의 manipulated image를 생성하는 것을 볼 수 있다. 기존 모델은 주어진 audio input의 semantic information을 제대로 반영하지 못한다.
Comparison of Text-guided Image Manipulation
- 최신 text-based image manipulation model인 TediGAN과 StyleCLIP을 기준선으로 사용한다.
아래의 그림에서 볼 수 있듯이, 논문의 sound-guided image mainpulation method는 text-guided image manipulation model보다 더 극적인(radical) 결과를 보여준다.

Example
- TediGAN은 “crying”을 강조하고, StyleCLIP은 “baby crying” context가 주어졌을 때 아기에게 집중한다.
- 반면 논문의 방법은 “baby”와 “crying”을 동시에 핸들링할 수 있다.
Context of audio sample
각 audio sample은 고유한 context를 가지고 있어 텍스트보다 더 풍부한 가이드를 제공한다. (아래 그림 참고)

예를 들어, 천둥 소리의 크기를 변경하거나 오디오에 “Rain”과 같은 특정 속성을 추가하면 manipulation context가 text-guided image manipulation보다 더 다양해진다.
Visualize the direction vector with t-SNE
t-SNE를 사용하여 direction vector의 방향을 시각화한다. 각 modality와 source latent code의 vector를 추출하여 조작 방향의 분포를 보여준다.
- VGG-Sound(실험에서 사용한 audio-visual dataset)의 attribute를 선택하고 audio와 text prompt를 무작위로 sampling한다. 같은 label에서 audio와 text를 무작위로 sampling했음에도 불구하고, sound-guided latent code는 text-guided latent code보다 더 큰 전환(more significant transition)을 보여준다.
- 공정한 비교를 위해 다양한 text synonym(동의어)을 사용했지만, text-guided latent code는 변화에 덜 효과적인 것으로 보인다.
Multi-modal Image Manipulation
논문의 방법은 audio, text ,image가 동일한 embedding space를 공유하도록 한다.
세부 설명
- Embedding space : Multi-modal embedding이 동일한 latent space에 있다는 것을 입증하기 위해 text와 sound 기반 latent space를 보간한다.(추가 자료 참조)
- Multi-modal shareable latent space : 사용자가 제공한 text와 audio input을 동일한 embedding space에서 결합하여 대상 이미지를 공동으로 수정할 수 있다.
Multi-modal style transfer experiment
- Latent code의 특정 layer를 선택하고 audio와 text로 스타일을 혼합하는 실험을 수행한다.
소리 소스는 얼굴의 감정적인 요소(ex. “giggle”)를 효과적으로 조작할 수 있으며, text information은 대상 이미지의 배경 색상을 제어한다. (아래 그림 참조)
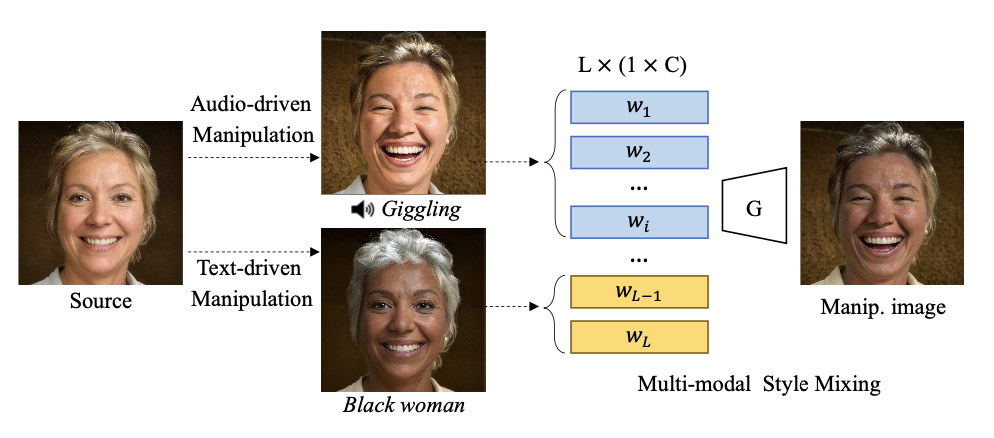
Style-mixing details
- TediGAN의 StyleGAN layerwise analysis를 따른다.
- 18*512 차원의 latent code에서 style mixing technique은 sound-guided latent code의 1번~9번 layer와 text-guided latent code의 10번~18번 layer를 선택하여 sound의 동적인 특성과 text의 human properties를 혼합한다.
Effect of Adaptive Layer Masking
StyleGAN에서는 각 layer마다 latent code가 서로 다른 style 속성을 가지기 때문에 Style layer를 adaptive하게 regularization하는 것이 필요하다.

세부 설명
- Adaptive Regularization : Latent code의 각 layer에 대해, 정규화 동안 다양성을 제어하는 훈련 가능한 매개변수를 곱한다.
- Adaptive Masking : Adaptive masking은 의미적 단서(semantic cue)에 기반하여 latent code를 변경함으로써 방향을 수정한다.
- Qualitative Comparison : 위의 Figure 8에 나타난 바와 같이, 결과물의 정성적 비교를 통해 Adaptive layer masking을 style layer에 적용하는 mechanism의 효과를 확인할 수 있다.
Example
- 천둥 소리와 비 소리 : 천둥 소리는 천둥과 비 소리의 혼합이다. 두 번째 row에선 천둥과 번개가 보이지 않지만, 마지막 row에서는 번개와 비가 나타난다. 이는 adaptive masking이 의미적으로 합리적(semantically reasonable)인 sound-guided image manipulation을 가능하게 함을 보여준다.
결론
- Hyperparameter setting : $\lambda_{sim}$과 $\lambda_{ID}$ 하이퍼파라미터에 따라 조작 결과가 달라진다. 이에 대한 결과는 supplemental material에 포함되어 있다.
- Adaptive layer masking은 sound-guided image manipulation의 의미적 정확성을 높이는 중요한 역할을 한다. 이는 audio input에 따라 이미지의 스타일을 세밀하게 조정할 수 있게 한다.
4.2. Quantitative Evaluation
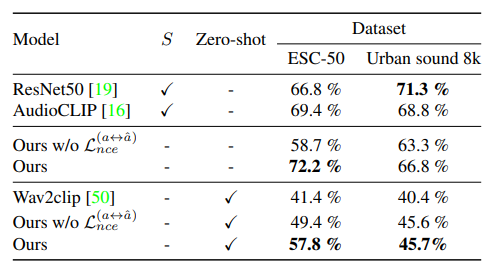
Zero-shot Transfer
논문의 모델을 Supervised method, 이미 존재하는 Zero-shot audio classification method와 비교한다.
먼저, supervised method로 훈련된 audio embedding을 비교한다. 여기에는 로지스틱 회귀(logistic regression), ResNet50 model(supervised by random initialization of weights as a baseline model), AudioCLIP 이 포함된다.
비교
- Supervised Learning method
- Logistic Regression : ResNet50 backbone을 사용하여 추가적인 finetuning 없이 audio embedding을 학습한다.
- AudioCLIP : ESResNeXt backbone을 사용하며, 논문에서는 audio head를 사용하여 test dataset을 finetuning한다.
- Zero-shot audio classification
- Zero-shot audio classification accuracy를 Wav2clip과 비교한다.
- 위의 Table에서 논문의 모델이 각 작업에서 기존의 연구보다 우수한 성능을 보이는 것을 알 수 있다.
결론
- 논문에서 제시된 Loss Function은 CLIP embedding space에서 세 가지(text, sound, image)의 modality를 학습하고, Constrative loss를 통해 더 풍부한 audio representation을 얻는다.
- Wav2clip은 audio와 시각적 관계만 학습하는 반면, 논문의 모델은 audio sample 간의 contrastive loss를 통해 더 풍부한 오디오 표현을 학습한다.
Semantic Accuracy of Manipulation
논문의 Audio-guided image manipulation method의 효과를 정량적으로 분석한다.
세부 설명
- 성능 측정 : semantic-level classification task의 작업에서 성능을 측정한다.
- 사전 훈련된 audio encoder에서 audio embedding을 얻는다.
- 이 embedding을 사용하여 8개의 semantic label (giggling, sobbing, nose-blowing, fire cracking, wind noise, underwater bubbling, exploision, and thunderstorm)을 인식하는 linear classificer를 훈련시킨다.
모델 구성
- StyleGAN2 사용 : FFHQ dataset으로 사전 훈련된 StyleGAN2 weight를 사용하여 giggling, sobbing, nose-blowing attribute를 guide한다.
- text와 audio 간의 semantic-level classification accuracy를 비교한다.
- fire cracking, wind noise, underwater bubbling, exploision, thunderstorm attribute를 guide할 때는 LSUN (church) dataset으로 사전 훈련된 StyleGAN2 weight를 사용한다.
결과
아래 그림에 나타난 바와 같이, 논문의 방법은 일반적으로 기존의 text-guided manipulation method보다 더 나은 성능을 보인다.
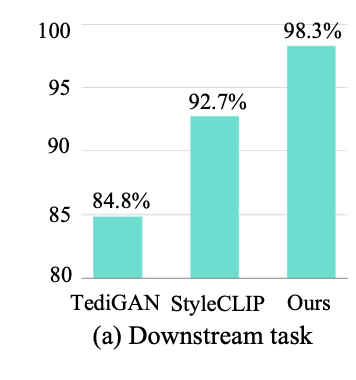
이는 의미적으로 풍부(semantically-rich)한 latent representation을 통해 더 높은 정확성을 달성할 수 있음을 보여준다.
Distribution of Manipulation Direction
Latent code가 얼마나 변했는지를 source latent code와 manipulated latent code 간의 cosine similarity를 통해 확인한다.
Text-guided latent representation과 sound-guided latent representation의 cosine similarity를 비교한다.
세부 설명
- 평가 항목 : Source latent code $w_s$, Audio-driven latent code $w_a$, Text-driven latent code $w_t$ 사이의 cosine similarity의 평균 및 분산을 평가한다.
- High-level characteristic : Latent representation을 일반적으로 contents의 고수준 특성을 나타낸다.
Latent space of StyleGAN2
- Sound-guided latent code는 text-guided latent code에서 더 큰 변화를 보이며, 이는 더 의미 있는 조작을 가능하게 만든다.
- Text-guided manipulation에 비해 sound-guided mainpulation이 더 풍부하고 다양하게 image를 변화시킬 수 있음을 시사한다.
4.3. User Study
- Amazon Mechanical Turk (AMT)에서 100명의 참가자를 모집하여 제안된 방법을 평가한다.
- 참가자들은 TediGAN, StyleCLIP, 논문의 모델이 생성한 세 가지 조작된 이미지를 보여주었다.
- 참가자들은 다음 질문에 답변하였다.
- (i) Perceptual Realism - 어느 이미지가 제일 나은가?
(ii) Naturalness - 제공된 이미지가 자연스럽게 조작되었는가?
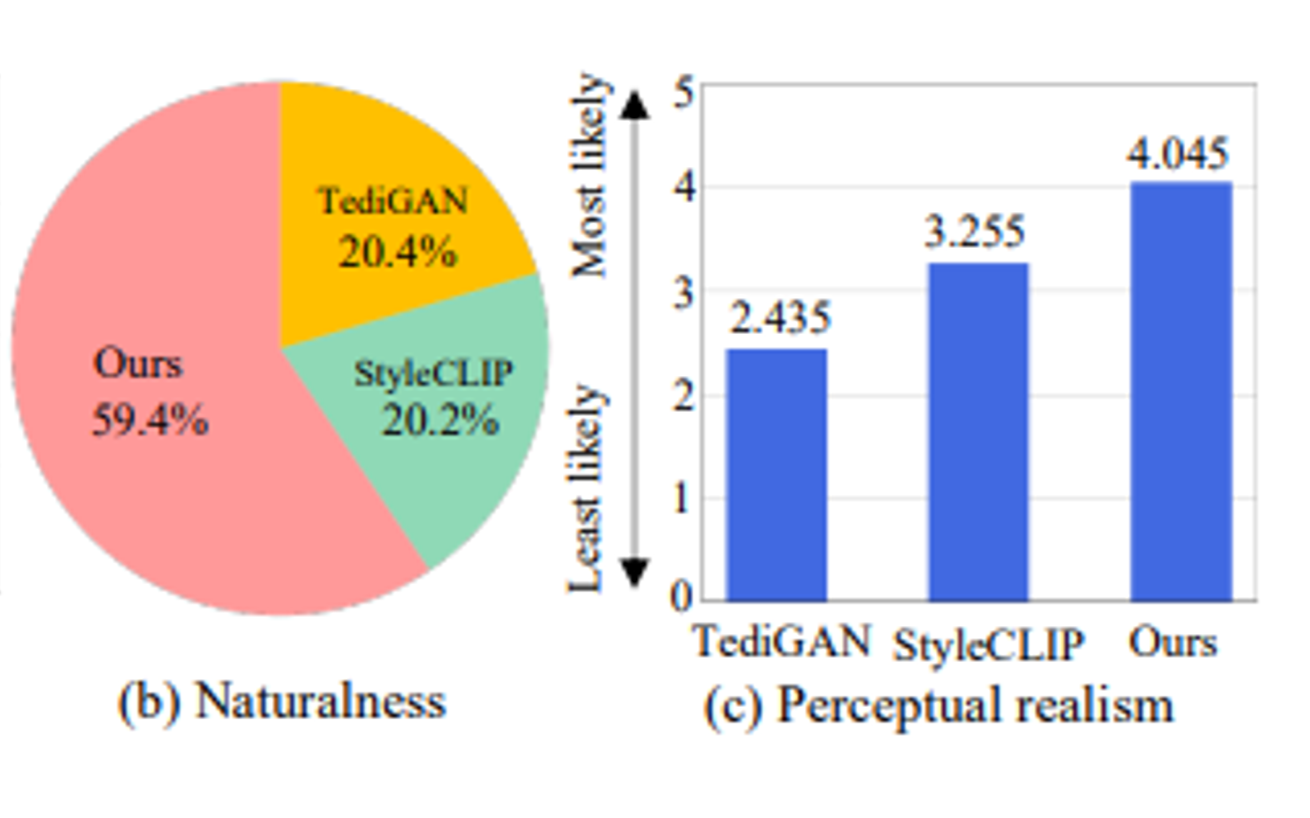
- 설문 결과표인 위의 그래프를 살펴보면 논문의 모델이 지각적 현실감(perceptual realism) 및 자연스러움(naturalness) 측면에서 다른 최신 접근 방식들보다 우수하다는 것을 보여준다.
5. Application
Sound-Guided Artistic Paintings Manipulation
StyleGAN2 generator 사용, WikiArt dataset을 사용하여 미술 작품에 대해 pre-training 진행함.

위의 그림은 주어진 audio input에 따라 예술 작품을 manipulate한 결과를 보여준다.
Music Style Transfer
방법
- 다양한 음악 장르에 대한 오디오 입력을 사용하여 이미지 스타일을 조작.
- 제안된 모델은 오디오 입력을 사용하여 이미지의 스타일을 변경한다.
결과(실패 사례)
일부의 경우 style transfer가 너무 극적이여서 image의 identity를 유지하기 어려운 상황이 발생할 수 있다. 아래의 그림은 이러한 실패 사례를 보여준다.

- 폭발 소리와 바람 소리 입력에 대해 조작된 이미지가 원래 이미지의 아이덴티티를 유지하지 못하는 경우가 존재한다.
- 이러한 실패 사례는 모델의 한계를 강조하며, 향후 연구에서 개선의 여지가 있음을 시사한다.
6. Discussion and Conclusion
6.1. Discussion
이 논문에서는 주어진 audio input에 대한 semantic-level understanding에 기반하여 이미지를 편집하는 방법을 제시하였다.
유저가 제공한 audio input을 StyleGAN2와 CLIP embedding space를 활용하여 사용자가 제공한 audio input을 Latent space에 투영한다. 그런 다음, latent code를 오디오와 정렬하여 오디오의 문맥을 반영하면서 의미 있는 image manipulation을 가능하게 한다.
우리의 모델은 바람, 불, 폭발, 천둥, 비, 웃음, 코 풀기 등의 다양한 audio input에 반응하는 조작을 생성할 수 있다. audio input은 image maniuplation을 위해 의미 있는 단서를 성공적으로 제공할 수 있음을 관찰하였다. 그러나 이미지 스타일의 급격한 변화로 인해 모든 경우에 동일성(identity)을 유지하는 것은 어려울 수 있다.
우리의 multi-modal embedding space 탐색 방법은 다양한 multi-modal context에서 여러 응용 프로그램에 사용할 수 있다. 우리의 접근 방식은 text에 기반한
6.2. Conclusion
이 논문은 주어진 audio input의 의미를 반영하여 이미지를 조작하는 방법을 제안하고, 이를 통해 생성된 이미지가 자연스럽고 다채로움을 입증하였다. 이 접근 방식은 다양한 응용 프로그램에서 효과적으로 사용할 수 있으며, 향후 연구를 통해 더욱 발전할 수 있는 가능성을 보여준다.
향후 연구 방향으로는 더 다양한 audio input에 대한 반응을 탐구하고, 이미지 동일성을 유지하면서도 더 복잡한 조작을 가능하게 하는 방법을 개발하는 것이다. 또한 multi-modal embedding space를 활용하여 audio, text 및 image 간의 더 정교한 상호작용을 탐구하는 것도 중요하다.