강화학습 알고리즘 톺아보기
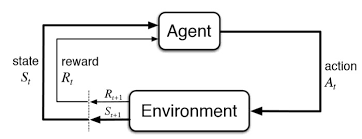
게시글의 내용은 밑바닥부터 시작하는 딥러닝 4권의 Ch 10. 한 걸음 더의 내용을 베이스로, 제가 공부한 내용을 추가한 것입니다.
10.1. 심층 강화 학습 알고리즘 분류
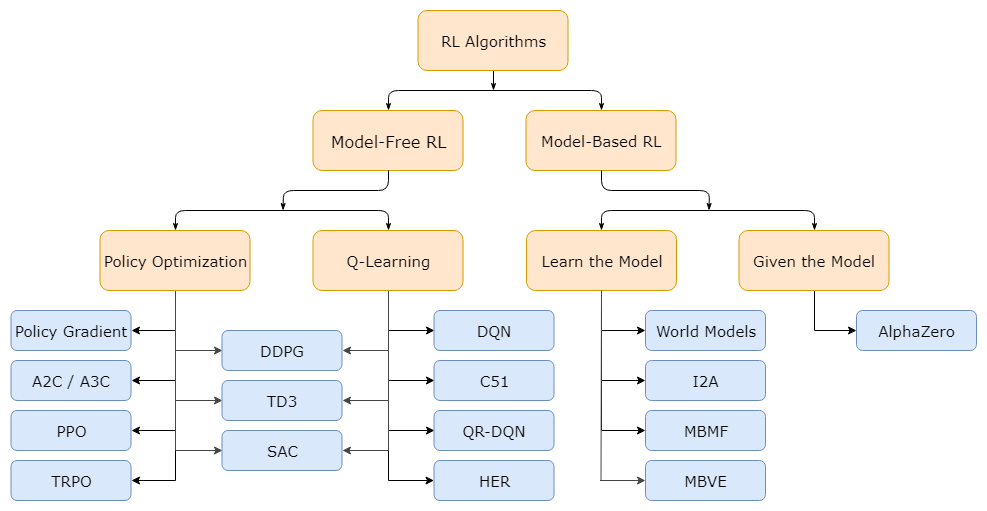
가장 큰 분류 기준
환경 모델, 즉 상태 전이 함수( $p(s’ s,a)$ )와 보상 함수( $r(s, a, s’)$ )의 사용 여부 - 환경 모델을 사용하면 모델 기반 기법(Model-Based method), 사용하지 않으면 모델 프리 기법(Model-Free method)이다.
Model-Based method
- 환경 모델이 주어지는 경우
- Agent는 행동 계획 없이 계획(planning)만으로 문제를 해결할 수 있다.
- 환경 모델이 주어지지 않은 경우
- 환경에서 얻은 경험으로 환경 모델을 학습하는 방법 활용 가능
- 학습한 환경 모델은 계획 수립뿐 아니라 정책의 평가와 개선에도 활용할 수 있다.
- ex ) World Models, MBVE(Model-Based Value Estimation)
- 현재 활발히 연구 중인 분야로, 앞으로 인간과 같은 범용 인공지능(AGI)를 구현하는 데 유용하게 활용될 것으로 기대됨.
- 환경에서 얻은 경험으로 환경 모델을 학습하는 방법 활용 가능
- Agent가 환경 모델이 생성하는 샘플 데이터의 일부만 얻을 수 있기 때문
- 학습한 환경 모델과 실제 환경 사이에 괴리(편향)가 생길 수 있다. → Agent가 학습한 모델에서는 적합했던 행동이 실제 환경에서는 바람직하지 않은 행동일 수 있다.
Model-Free method
- 정책 기반
- 정책 경사법
- REINFORCE
- 가치 기반 (가치 함수를 모델링하여 학습)
- DQN
- 정책 기반 + 가치 기반 (Hybrid)
- 행위자-비평자
10.2. 정책 경사법 계열의 고급 알고리즘
10.2.1. A3C, A2C (분산 학습 알고리즘)
A3C (Asynchronous Advantage Actor-Critic)
- 여러 Agent가 병렬(parallel)로 행동하며 비동기적으로(Asynchronous) 매개변수를 갱신한다.
신경망으로 모델링한 행위자-비평자를 이용하여 정책을 학습한다. 하나의 전역 신경망과 여러 개의 지역 신경망을 사용한다.
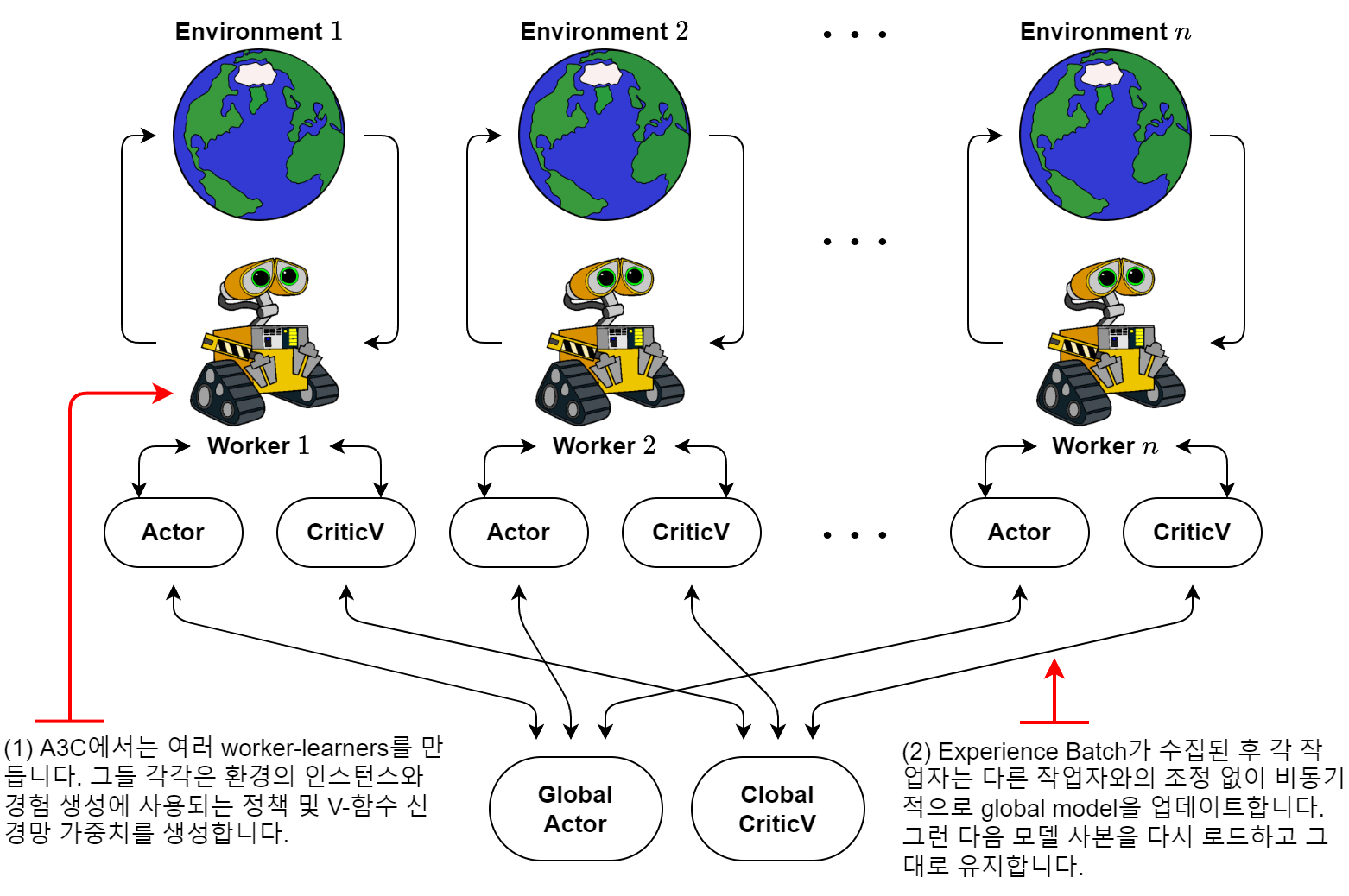
- 지역 신경망은 각자의 환경에서 독립적으로 플레이하며 학습한다. 그리고 학습 결과인 기울기를 전역 신경망에 보낸다.
- 전역 신경망은 여러 지역 신경망에서 보내온 기울기를 이용해 비동기적으로 가중치 매개변수를 갱신한다.
- 이렇게 전역 신경망의 가중치 매개변수를 갱신하는 동안 주기적으로 전역 신경망과 지역 신경망의 가중치 매개변수를 동기화한다.
- A3C의 장점은 여러 Agent를 병렬로 행동하게 하여 학습 속도를 높인다는 것에 있다.
Agent들은 독립적으로 행동(탐색)하기 때문에 한층 다양한 데이터를 얻을 수 있다.
→ 학습 데이터의 전체적인 상관관계를 약화시킬 수 있어 학습이 더욱 안정적으로 이루어진다.
A2C (Advantage Actor-Critic)
A3C에서 Asynchronous가 빠졌다! → 매개변수를 동기식으로(Synchronous) 갱신한다.
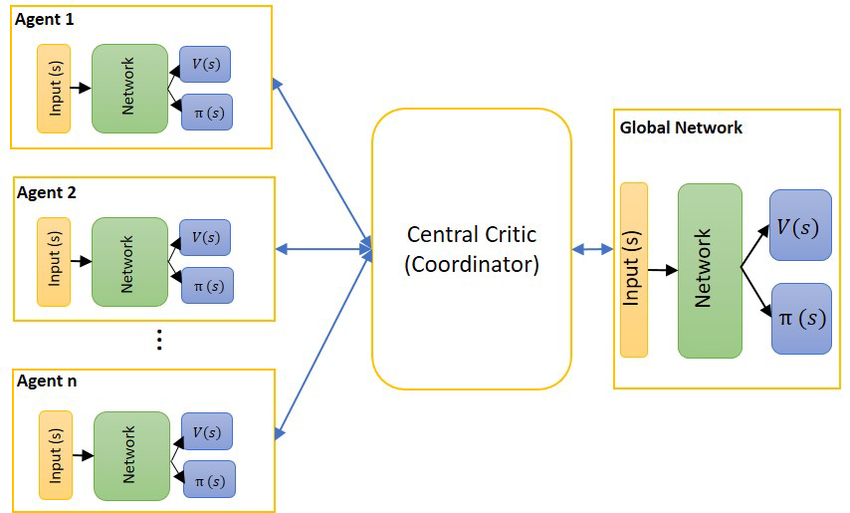
- 각각의 환경에서 Agent가 독립적으로 동작한다.
- 시간 t에서 각 환경의 상태를 배치로 묶어 신경망을 학습시킨다. 이 때 신경망의 출력(=정책의 확률 분포)에서 다음 행동을 샘플링하며, 샘플링된 행동을 각 환경에 전달한다.
실험 결과 A2C 방식의 동기식 갱신 성능이 A3C보다 떨어지지 않는다.
- 그러나 A2C가 A3C보다 구현하기 쉽고, GPU같은 컴퓨팅 자원을 더 효율적으로 사용할 수 있다. 이러한 장점 때문에 실무에서는 A2C를 더 많이 사용한다.
- A3C는 신경망을 환경별로 실행해야 하므로, n개의 환경을 준비한다면 이상적으로 GPU도 n개가 필요하다. 하지만 A2C에서는 신경망을 실행하는 부분이 하나로 통합되어 있어서 GPU 하나로 계산할 수 있다!
10.2.2. DDPG (결정적 정책을 따르는 알고리즘)
정책을 직접 모델링하는 정책 경사법 같은 기법은 행동 공간이 연속적인 문제에도 활용할 수 있다. 그 예시 중 하나가 DDPG이다!
DDPG (Deep Deterministic Policy Gradient method)
- DDPG의 정책은 특정 상태 $s$를 입력하면 행동 $a$가 고유하게 결정된다. (결정적 정책)
- 결정적 정책을 DQN에 통합한다.
- 정책을 나타내는 신경망을 $\mu_{\theta}(s)$라 하고, DQN의 Q함수를 나타내는 신경망을 $Q_{\phi}(s, a)$라 한다. $\theta$와 $\phi$ 는 각 신경망의 매개변수이다. 이 때 DDPG는 다음 두 가지 학습 과정을 거쳐 매개변수를 갱신한다.
- Q함수의 출력이 커지도록 정책 $\mu_{\theta} (s)$의 매개변수 $\theta$를 갱신
- DQN에서 수행하는 Q러닝을 통해 Q함수 $Q_{\phi}(s, a)$의 매개변수 $\phi$를 갱신
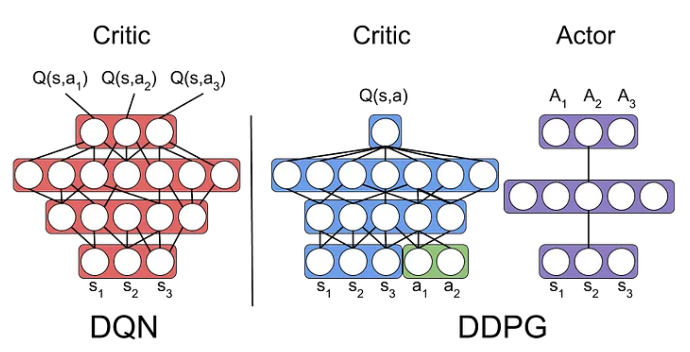
- $\mu_{\theta}(s)$ 가 출력하는 행동 $a$는 연속적인 값이고, 이 출력 $a$가 그대로 $Q_{\phi}(s, a)$의 입력이 된다.
- 이렇게 연결된 두 신경망에서 역전파를 수행하며, 그 결과로 $\nabla_{\theta}$$q$가 구해지고(q는 Q함수의 출력) 기울기 $\nabla_{\theta} q$를 이용해 매개변수 $\theta$를 갱신할 수 있다.
DDPG의 Q러닝에서는 결정적 정책 $\mu_{\theta}(s)$를 사용하여 계산 효율을 높일 수 있다.
DQN에서 Q함수의 갱신은 $Q_{\pi}(S_t, A_t)$의 값이 $R_t+\gamma \max_{a}Q_{\pi}(S_{t+1}, a)$가 되도록(또는 근접하도록) 하는 것이다.
DDPG에서는 앞선 첫 번째 학습을 통해 정책 \mu_{\theta}(s)는 Q함수가 커지는 행동을 출력한다. 따라서 다음 근사를 적용할 수 있다.
- $\max_{a}Q_{\pi}(s,a) \cong Q_{\pi}(s, \mu_{\theta}(s))$
일반적으로 최댓값을 구하는 $\max_{a}$ 연산은 계산량이 많다. 하지만 DDPG에서는 $\max_{a}Q_{\pi}(s,a)$ 계산을 $Q_{\pi}(s, \mu_{\theta}(s))$ 라는 두 개의 신경망 순전파로 대체한다. 이렇게 계산을 단순화하여 학습 효율을 높인다.
10.2.3. TRPO, PPO (목적 함수에 제약을 추가하는 알고리즘)
정책 경사법에서는 정책을 신경망으로 모델링하고 기울기 기반으로 매개변수를 갱신한다.
TRPO (Trust Region Policy Optimization)
- ‘신뢰 영역 정책 최적화’인 TRPO를 통해 갱신 폭의 문제 해결 시도!
- 신뢰할 수 있는 영역 안에서, 적절한 갱신 폭으로 정책 최적화 가능.
- 정책 갱신 전후의 쿨백-라이블러 발산(Kullback-Leibler Divergence, KL Divergence : 두 확률 분포의 유사도)을 지표로 삼아, 그 값이 임곗값을 넘지 않아야 한다는 제약 부과.
즉, 쿨백-라이블러 발산 제약이 걸린 상태에서 목적 함수를 최대화하는 문제로 보는 것. 이를 수식화하면 아래와 같다.
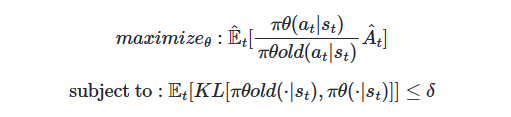
- 정책 간의 KL Divergence의 정확한 계산이 복잡하거나 불가능할 때, 테일러 급수를 이용하여 2차항까지 전개하여 근사값을 얻는다. 이를 ‘2차 근사’라고 한다.
- 2차 근사를 통해 목적 함수를 선형적으로 근사하고, 제약 조건을 2차적으로 근사하여 켤레 기울기 방법을 통해 정책 업데이트 방향과 크기를 결정한다.
- 2차 근사를 진행할 때, 2차 미분 계산이 필요하다.
PPO (Proximal Policy Optimization)
TRPO에서 제약이 걸린 최적화 문제를 풀려면 헤세 행렬(hessian matrix)이라는 2차 미분 계산이 필요하다.
헤세 행렬은 계산량이 많아 병목을 일으킨다.
이 문제를 개선한 방법이 PPO이다. PPO는 TRPO의 제약 조건을 직접 최적화 함수에 추가하였다.
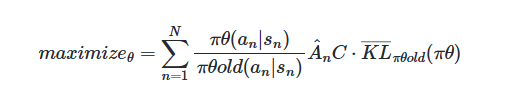
- 또한 PPO에서는 update 되는 $r_t(\theta)$에 대한 값을 [$1-\epsilon, 1+\epsilon$]으로 제한하여 Clipping을 시행하였다.
10.3. DQN 계열의 고급 알고리즘
10.3.1. 범주형 DQN
- Recap : Q함수의 수식은 다음과 같다.
$Q_{\pi}(s, a) = E_{\pi}[G_t S_t = s, A_t = a]$ - Q 함수의 특징 : 확률적 사건인 수익 G_t를 기댓값이라는 하나의 값으로 표현하는 것.
DQN과 Q러닝에서는 Q 함수, 즉 기댓값으로 표현되는 값을 학습한다.
이를 발전시켜 Q 함수라는 기댓값이 아니라 ‘분포’를 학습시키자는 아이디어가 있다. 이 아이디어를 분포 강화 학습(distributional reinforcement learning)이라고 한다.
- 분포 강화 학습에서는 수익의 확률 분포(범주형 분포)인 $Z_{\pi}(s, a)$를 학습한다.
- 범주형 분포란? → 여러 범주(이산 값)중 어느 범주에 속할 것인지에 대한 확률 분포이다.
- 범주형 DQN에서는 수익을 범주형 분포로 모델링하고 그 ‘분포의 형태’를 학습한다. 이를 위해 범주형 분포 버전의 벨만 방정식을 도출하고, 그 방정식을 이용하여 범주형 분포를 갱신한다.
- 범주형 분포의 빈이 51개일 때 Atari 과제에서 성능이 가장 좋았다고 한다. (C51)
10.3.2. Noisy Network
- DQN에서는 $\epsilon$-탐욕 정책으로 행동을 결정한다.
- $\epsilon$의 확률로 무작위 행동을 선택하고, 나머지 1-$\epsilon$의 확률로 탐욕 행동(=Q함수가 가장 큰 행동)을 선택.
- 실전에서는 대체로 에피소드가 진행될수록 $\epsilon$값을 조금씩 낮추도록 스케줄링한다.
- $\epsilon$값은 하이퍼파라미터라서, 어떻게 설정하느냐에 따라 최종 정확도가 크게 달라질 수 있다. 하지만 $\epsilon$값의 후보는 매우 다양하다.
- 이러한 $\epsilon$ 설정 문제를 해결하기 위해 Noisy Network가 제안되었다. (효과적인 탐험을 위해!)
- 신경망의 가중치와 편향에 파라미터화된 노이즈를 추가한다.
- 에이전트의 정책에 확률성을 부여하여 탐험을 유도한다.
- 출력 쪽의 Fully Connected Layer에서 노이즈가 들어간 Fully Connected Layer를 사용한다.
노이즈가 들어간 Fully Connected Layer에서 가중치는 정규분포의 평균과 부산으로 모델링되며 순전파할 때마다 가중치가 정규분포에서 샘플링된다.
이렇게 하면 순전파할 때마다 무작위성이 스며들어 최종 출력이 달라진다.
10.3.3. 레인보우
- 지금껏 소개된 다양한 DQN 확장 알고리즘을 결합한 기법이다. 레인보우는 기존 DQN에 다음과 같은 기법들을 모두 조합하여 사용한다.
- Double DQN
- 행동 평가와 가치 평가를 분리하여 과대평가 문제를 해결한다.
- Online Network로 다음 상태의 최적 행동을 선택하고, Target Network로 해당 행동의 가치를 평가한다.
- Dueling DQN
- 가치 스트림과 이점 스트림으로 네트워크를 분리하고, 특별한 집계 방식으로 결합한다.
- Disributional RL과 결합되어 각 스트림에서 분포를 학습한다.
- 우선순위 경험 재생(Prioritized Experience Replay)
- TD 오차 대신 KL 손실을 우선순위로 사용하여 중요한 트랜지션을 더 자주 샘플링한다.
- Multi-step Learning
- 한 번에 여러 스텝을 학습하는 n-step 리턴을 사용하여 더 긴 시간 범위의 보상을 고려함으로써 장기적인 결과를 더 잘 반영할 수 있다.
- PER 및 Distributional Q-learning과 결합되어 n-step 분포형 손실을 계산한다.
- Distributional Q-learning
- Q-값의 단일 스칼라 값 대신 리턴의 전체 확률 분포를 학습한다. 불확실성을 더 잘 모델링하고, 복잡한 멀티모달 분포도 표현할 수 있다.
- Dueling Networks와 결합되어 각 스트림에서 분포를 학습한다.
- NoisyNet
- Fully-Connected Layer에 파라미터화된 노이즈를 추가한다.
- 이를 통해 탐색을 개선하고, 환경에 따라 적응적인 탐색이 가능해진다.
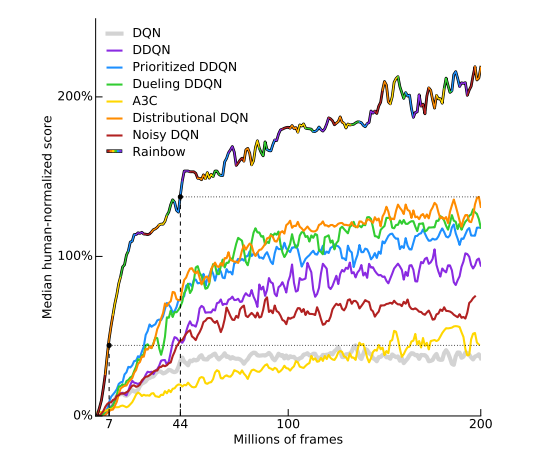
가로축 : 학습에 사용한 이미지 개수 (표기된 수치 * 100만) 세로축 : 일반인과 비교하여 정규화한 점수, 높을수록 성능이 좋다.
- Double DQN
Rainbow가 다른 기법들에 비해 성능이 비약적으로 높다!
10.3.4. 레인보우 이후의 발전된 알고리즘
- Rainbow 이후 CPU/GPU를 이용한 여러 분산 병렬 학습(실행 환경을 여러 개 준비하여 학습을 병렬로 진행)이 큰 성과를 올렸다.
- Ape-X
- Rainbow를 기반으로 하여 여러 개의 에이전트를 각각의 CPU에서 독립적으로 행동시킨다. 이때 에이전트들의 탐색 비중인 $\epsilon$을 모두 다르게 설정하여 다양한 경험 데이터를 수집한다.
→ 분산 병렬화를 통해 학습을 빠르게 진행하는 동시에 경험 데이터를 다양하게 얻어 성능 향상
paper link : https://arxiv.org/abs/1803.00933v1
- R2D2
- Ape-X에 더해 시계열 데이터를 처리하는 순환 신경망(LSTM)을 사용하였다. R2D2의 이름은 Recurrent(순환)와 Replay(경험 재생)에서 ‘R’ 두 개를 가져오고, Distributed(분산)와 Deep Q-Network(DQN)에서 ‘D’ 두 개를 가져와서 만든 이름이다.
paper link : https://arxiv.org/abs/1906.06195
- NGU
- ‘Never Give Up’의 약자이다. R2D2의 토대에 내적 보상(intrinsic reward) 메커니즘을 추가하여 어려운 과제, 특히 보상이 적은 과제에서도 탐색을 포기하지 않도록 하였다.
내적 보상은 상태 전이가 예상과 다를수록, 즉 얼마나 ‘놀랐는가’에 따라 스스로 보상을 더해준다. 보상이 0에 가까운 희박한 작업에서 내적 보상은 보상의 크기가 아니라 ‘호기심’에 따라 행동하도록 유도한다. 이 과정에서 보상을 극대화하는 방법을 찾을 수 있다.
paper link : https://arxiv.org/abs/2002.06038
- Agent57
- NGU를 발전시켜, 내적 보상 메커니즘을 개선하고 ‘meta controller’라는 구조를 사용하여 에이전트들에 할당되는 정책을 유연하게 배분했다.
Atari 안에 있는 57개의 게임 모두에서 사람보다 우수한 성적을 거두는 데 성공하였고, 강화 학습 알고리즘으로서는 처음 이룬 쾌거였다고 한다.
paper link : https://arxiv.org/abs/2003.13350
- Ape-X
10.4. 사례 연구
10.4.1. 보드 게임
- 바둑, 장기, 오셀로 등의 보드 게임은 다음과 같은 특징을 지니고 있다.
- 보드의 모든 정보를 알 수 있음 (완전 정보)
- 한 쪽이 승리하면 다른 쪽은 패배함 (제로섬)
- 상태 전이에 우연이라는 요소가 없음 (결정적)
이러한 성질의 게임에서 가장 중요한 것은 ‘수 읽기’다.
“내가 이 수를 두면 상대가 저 수를 둘 것이고, 그러면 나는 이 수로 받아칠 것이다!” 처럼 앞으로 일어날 일을 다양하게 예측해볼수록 더 좋은 수를 찾을 수 있다.
- 게임 보드를 노드로, 다음 수를 Edge로 표현한 것을 게임 트리라고 한다.
- 게임 트리를 모두 펼칠 수 있다면 가능한 모든 결과가 드러나기 때문에 최선의 수를 찾을 수 있다.
- 하지만 바둑이나 장기는 가능한 상태(돌이나 말을 배치하는 패턴)가 천문학적으로 많아서 게임 트리를 모두 전개하기가 현실적으로 불가능하다. → 게임 트리를 효율적으로 탐색해야 한다!
몬테 카를로 트리 탐색 (Monte Carlo Tree Search, MCTS)
- 트리의 전개를 몬테 카를로법으로 근사하는 기법
- 돌들이 특정 형태로 놓여 있는 보드 상태가 얼마나 좋은지 평가할 때, 돌을 무작위로 두는 두 플레이어에게 승패가 결정될 때까지 계속 두게 한다.
- 이러한 시도(특정 상태의 보드에서 시작하는 게임)를 수차례 반복하여, 그 승률로 해당 보드 상태가 ‘얼마나 좋은가’를 근사적으로 나타낸다.
알파고 (AlphaGo)
- 몬테 카를로 트리 탐색 + 심층 강화 학습의 결합 기법
- 두 개의 신경망이 사용된다. → MCTS를 더 정밀하게 수행할 수 있다!
- Value 신경망
- 현재 바둑판에서 이길 확률을 평가
- Policy 신경망
다음에 둘 수를 확률로 출력
ex ) (1,1) 위치에 둘 확률 : 2.4%, (1,2) 위치에 둘 확률 : 0.2%
- Value 신경망
- 인간의 바둑 기보 데이터를 이용해 두 신경망(Value, Policy)를 학습시키고, 그 다음 셀프 플레이(Self-Play) 형태로 대국을 반복하고 여기서 수집한 경험 데이터를 사용해 학습을 더욱 강화한다.
- 바둑을 두는 Agent가 있고, Agent의 복제체인 대전 상대가 환경 역할을 한다.
- 이 둘이 상호작용하면서 최종적으로 승리 혹은 패배라는 보상을 얻는다.
- 환경 속에서 상호작용하며 데이터를 수집한다는 점에서 강화학습이라 설명할 수 있다.
알파고 제로 (AlphaGo Zero)
- 인간의 기보를 학습 데이터로 사용한 알파고와 달리, 셀프 플레이를 통한 강화학습만으로 학습 진행.
- 알파고에서 사용하던 ‘도메인 지식(바둑 규칙)’을 이용하지 않았다.
- Policy 신경망과 Value 신경망을 하나의 신경망으로 표현.
- 몬테 카를로 트리 탐색으로 플레이아웃하지 않고, 신경망의 출력만으로 각 노드(상태)를 평가
전통적인 MCTS : 리프 노드에서 게임의 끝까지 무작위로 플레이하는 플레이아웃 수행.
플레이아웃의 결과를 사용하여 노드의 가치 추정.
AlphaGo Zero : 플레이아웃 대신 신경망을 사용하여 각 노드(상태)를 직접 평가.
신경망은 주어진 상태에 대해 정책, 가치 두 가지의 출력을 제공.
- 신경망의 가치 출력이 플레이아웃 결과를 대체한다.
- MCTS는 여전히 트리를 탐색하고, 가장 유망한 움직임을 선택하는 데 사용된다.
알파제로 (AlphaZero)
- 알파고 제로를 파인튜닝하여, 바둑 뿐 아니라 체스, 장기까지 둘 수 있다.
- 보드 게임의 종류에 상관없는 범용 알고리즘으로 진화!
MCTS를 이용한 AlphaDev Review :
https://gyeongminsu.github.io/posts/SortwithAI/
10.4.2. 로봇 제어
딥러닝을 이용한 로봇 제어
- 구글은 로봇 팔이 다양한 물건을 잡을 수 있도록 학습시키는 데 성공했다.

- 위쪽에 장착된 카메라가 보내주는 영상을 해석하여 어떻게 행동할지 결정한다.
- 행동의 결과로 물체를 잡으면 성공, 잡지 못하면 실패라는 보상을 준다.
10.4.3. NAS
- 딥러닝 신경망의 아키텍처(신경망 구조)는 보통 사람이 직접 설계한다. 뛰어난 아키텍처를 설계하기 위해서는 경험이 필요하여, 수많은 시행착오를 거쳐야 한다.
- 최근에는 최적의 아키텍처를 자동으로 설계하는 연구가 활발히 진행되고 있다. 이를 NAS(Neural Architecture Search)라고 한다.
- NAS를 수행하는 방법에는 베이지안 최적화(Bayesian optimization)와 유전 프로그래밍(genetic programming) 등 여러 가지가 있다. 그중 가장 유력한 후보가 강화 학습이다.
- https://arxiv.org/abs/1611.01578
- 강화 학습으로 신경망 구조를 자동으로 최적화하여 사람이 설계한 것 이상의 아키텍처를 발견하는 데 성공하였다.
10.5. 심층 강화 학습이 풀어야 할 숙제와 가능성
10.5.1. 현실 세계에 적용하기
- 현실 세계에 가상의 세계와 달리 제약이 많다. 예를 들어 로봇은 비싸고 대량으로 준비하기 어렵기 때문에, 경험 데이터를 충분히 수집하기 쉽지 않다.
- 또한 강화 학습에서는 시행착오를 거치면서 경험 데이터를 수집하는데, 이 과정에서 로봇을 고장내거나 주변에 위험을 초래하는 행동은 피해야 한다.
이러한 문제를 막아주는 유력한 해결책들 몇 가지를 아래에서 소개한다.
시뮬레이터 활용
- 현실 세계의 제약 상당수는 시뮬레이터로 해결할 수 있다. 시뮬레이터 안에서는 에이전트와 환경의 상호작용을 빠르게 반복할 수 있다. 게다가 에이전트가 위험한 행동을 하더라도 아무런 문제가 없다.
- 하지만 현실 세계와 시뮬레이터 속 세계 사이에는 간극이 있다. 시뮬레이터는 실제 환경을 완벽하게 모방할 수 없기 때문에 시뮬레이터에서 학습한 모델(에이전트)이 실제 환경에서 기대한 대로 동작하지 않는 경우가 많다.
이 문제에 집중하는 연구 분야를 Sim2Real이라고 한다.
- Sim2Real에는 여러 가지 유력한 기법이 있고, 그 중 Domain Randomization 기법이 있다.
- 시뮬레이터에 무작위 요소를 추가하여 다양한 환경을 만들고, 그 다양한 환경 속에서 에이전트를 행동시키고 학습시킨다.
- 무작위 요소를 통해 일반화 성능을 높여 실제 환경에서도 더 잘 동작하리라 기대할 수 있다.
오프라인 강화 학습(offline reinforcement learning)
- 과거에 수집한 경험 데이터(=오프라인 데이터, Ex. 자율주행이나 로봇 제어 등에서 사람이 조작한 많은 경험 데이터의 축적, 대화 시스템에서 사람들이 주고받은 대화 이력 수집)를 잘 활용하여, 에이전트를 학습시킬 수 있다.
- 나아가 환경과 상호작용을 전혀 하지 않고도 오프라인 데이터만으로 최적의 정책을 추정하는 것도 가능하다. 이를 오프라인 강화 학습이라 한다.
모방 학습
- 전문가의 시연을 참고하여 그 동작을 모방하는 것을 목표로 정책을 학습한다.
- Ex) 인간 전문가가 아타리를 플레이하는 모습을 모방
- ‘Deep Q-Learning from Demonstrations (Todd, Et al. 2017)’ 논문에서는 전문가의 플레이에서 얻은 ‘상태, 행동, 보상’의 시계열 데이터(전문가 데이터)를 DQN의 경험 재생 버퍼에 추가하고, 그 위에서 DQN으로 학습을 수행한다.
- 경험 재생 버퍼에서 전문가 데이터가 선택될 확률을 높이고 동시에 전문가 데이터에 가까워지도록 DQN의 갱신식을 조정한다.
10.5.2. MDP로 공식화하기 위한 팁
- 강화 학습의 많은 이론은 마르코프 결정 과정(Markov Decision Process, MDP)을 전제로 한다.
- 실제 문제를 강화 학습으로 풀려면 우선 문제를 MDP 형식에 맞는 공식으로 표현할 수 있어야 한다. 그리고 MDP로 어떻게 공식화하느냐가 최종 결과에 큰 영향을 준다.
MDP가 지닌 유연성
- 현실에 존재하는 모든 문제를 MDP 문제 형식에 맞출 수는 없지만, 많은 문제가 MDP로 공식화할 수 있다!
- MDP는 환경과 에이전트가 ‘상태, 행동, 보상’이라는 세 가지 정보를 서로 ‘던져주는’ 구조이다. 이때 어떤 센서를 사용할지, 행동을 어떻게 제어할지, 보상을 어떻게 설정할지 등 세부 정보는 문제에 따라 유연하게 결정할 수 있다.
- 에이전트의 행동 : 고차원~저차원적인 것까지 생각할 수 있다. 로봇 제어 문제의 경우 ‘쓰레기 버리기’나 ‘충전하기’ 같은 행동을 고차원, ‘모터에 $x$볼트 전류를 흘려보내기’와 같은 행동을 저차원적인 결정이라고 볼 수 있다.
MDP에서 설정이 필요한 사항
- 새로운 현실 문제를 MDP로 공식화하려면 다음과 같은 사항들을 결정해야 한다.
- 해결하고자 하는 문제는 일회성 과제인가, 아니면 지속적 과제인가?
- 보상의 가치는? (보상 함수 설정)
- 에이전트가 취할 수 있는 행동은 무엇인가?
- 환경의 상태를 무엇으로 규정할 것인가?
- 수익의 할인율은?
- 어디까지를 환경으로, 어디까지를 에이전트로 할 것인가?