추천시스템 프로젝트 진행 후기 - Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models (Dec. 2023)
0. Introduction
이번 학기에 전공수업 Term Project로 추천 시스템 알고리즘을 구현하는 프로젝트를 진행하였다. “추천 시스템” 이라는 테마 안에서 프로젝트 주제를 주체적으로 정하고 진행해야 했었기 때문에, 나는 연구 분야인 LLM을 이용한 추천 시스템 프로젝트를 진행하고자 했다.
프로젝트에서는 Dataset, Recommendation Algorithm, Benchmark를 직접 선정하여야 했다.
“Garbage In, Garbage Out” 이라는 격언을 생각해보면 뭐든지 Input data와 그 data를 이용한 Benchmark Evaluation, 즉 해결하거나 개선해야 하는 문제 정의가 최우선이다. 그래서 어떤 dataset을 이용하여 어떤 지표를 개선해야 할 지를 먼저 고민하였다.
팀원들이 독서에 관심이 있어서 책과 관련한 dataset 중 가장 대중적이고 row가 많은 Amazon-book Reviews dataset을 이용하기로 결정하였다.
1. Dataset
Amazon-book dataset의 metadata와 예시는 다음과 같다.
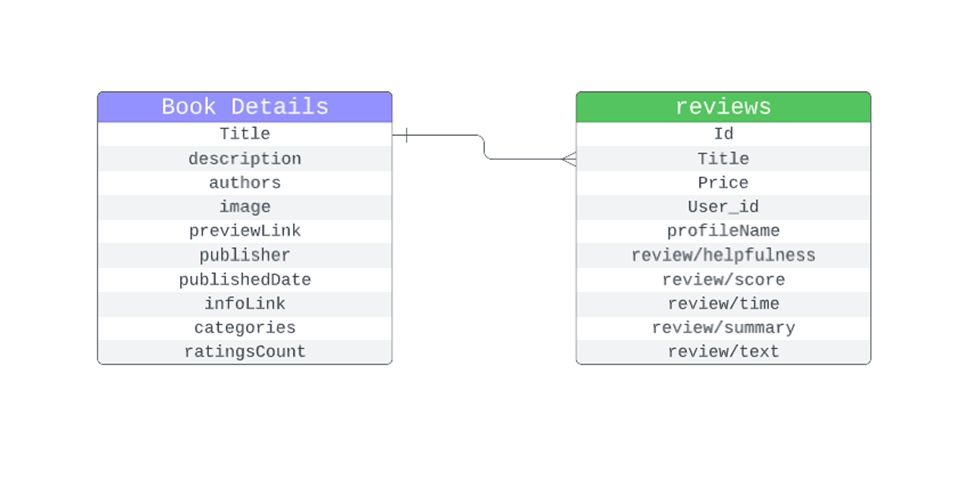
- Book Details (metadata info) Reviews (metadata info)
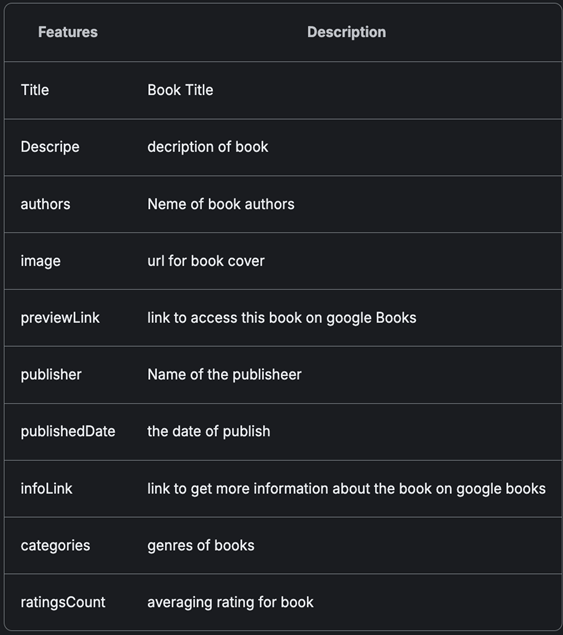
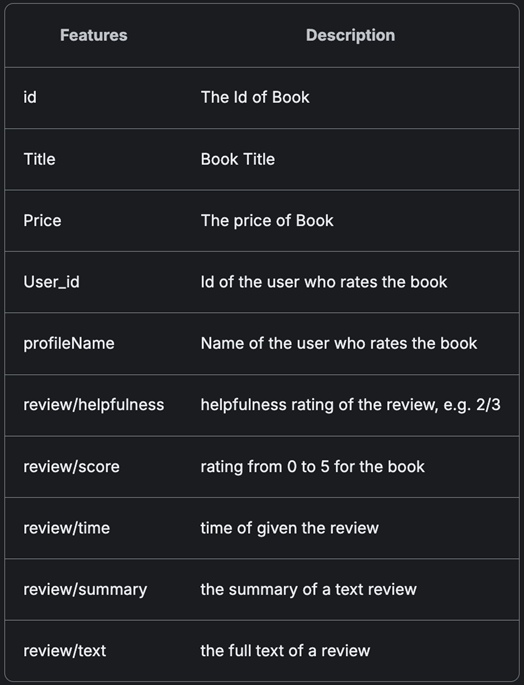
- Book Details (describe)

- Reviews (describe)
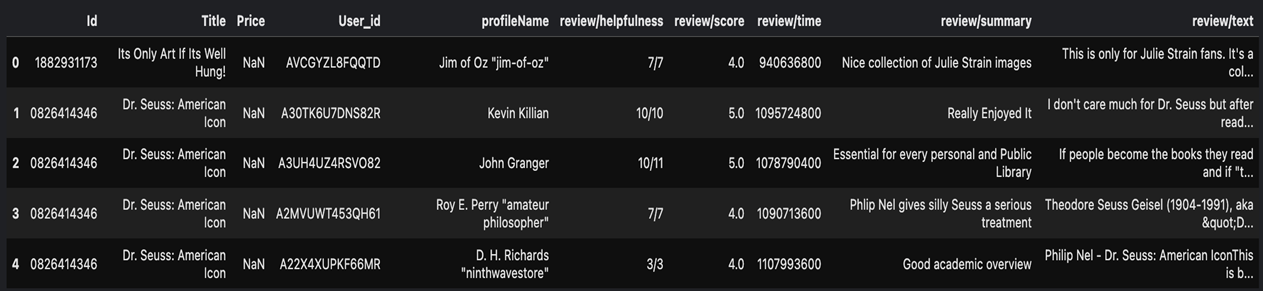
Amazon-book dataset은 2,370,585개의 상품 가짓수에 총합 22,507,155개의 방대한 리뷰가 있는 만큼 data가 풍성하다. 또한 metadata를 살펴보면, 단순한 정량적 정보인 ratings, helpfulness 뿐만 아니라 review text data, categories, description 등 여러 자료형의 정성적인 정보들도 많이 있다.
기초적으로 협업 필터링이나 여느 추천 시스템 알고리즘에 이용되는 데이터에는 주로 정량적 데이터만 input으로 이용되었다. 하지만 정성적 데이터가 풍부한 dataset에서 이 정보들을 이용하여 추천 시스템 알고리즘을 이용하면 더욱 다양한 정보를 반영할 수 있고 개인화된 추천 알고리즘을 만들 수 있을 것이라 판단하였다.
이러한 생각으로 인해, Amazon-book dataset의 평점 데이터 뿐만 아니라 리뷰 데이터를 반영하여 이용자에게 알맞은 책을 추천하는 Reranking Task에 대한 퍼포먼스를 향상시키는 것을 목표로 삼아 어떻게 알고리즘을 설계할 지 고민하였다.
2. Recommendation Model (Algorithm)
우리는 Amazon-book의 Review Text data의 정보를 가장 잘 반영하려면 결국 언어 모델의 힘이 필요할 것이라고 판단하였다. 이를 위해 RNN, LSTM, 또는 Transformer 계열의 언어 모델을 이용하여 Ratings, Review data 모두를 응용하는 추천 시스템 알고리즘에 대한 방법론을 탐색하였다.
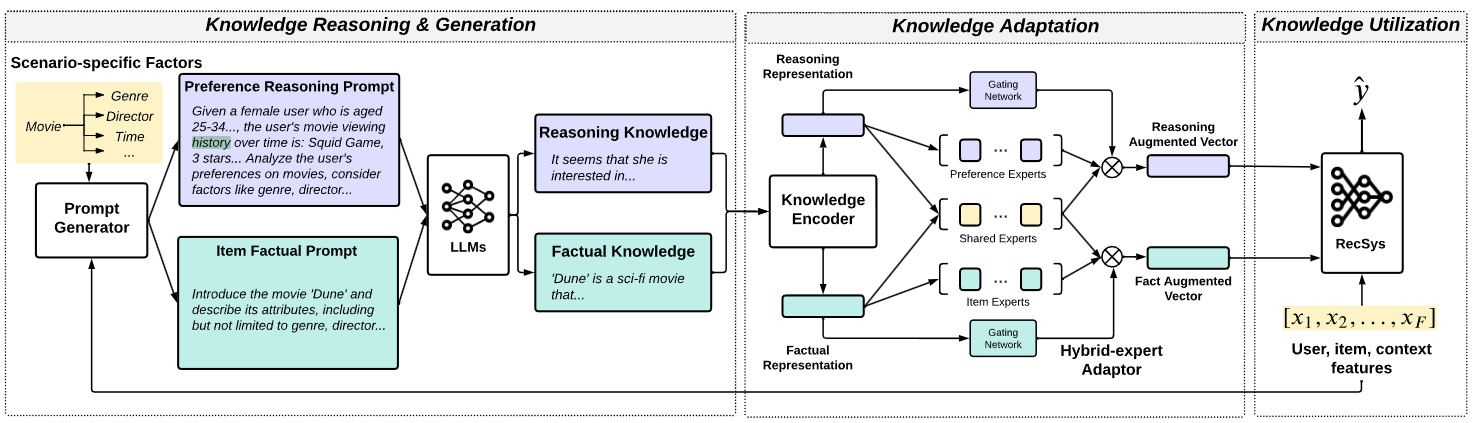
탐색을 진행한 결과 우리의 task에 가장 적합하게 들어맞는 task를 수행한 논문을 하나 발견하였다. 그 논문은 바로 2023년 6월에 공개된 “Towards open-world recommendation with knowledge augmentation from large language models.” Proceedings of the 18th ACM Conference on Recommender Systems. 2024. Xi, Yunjia, et al. 이다. 이 논문에선 Open-World Knowledge Augmented Recommendation (이하 KAR)이라는 Framework를 제안한다.
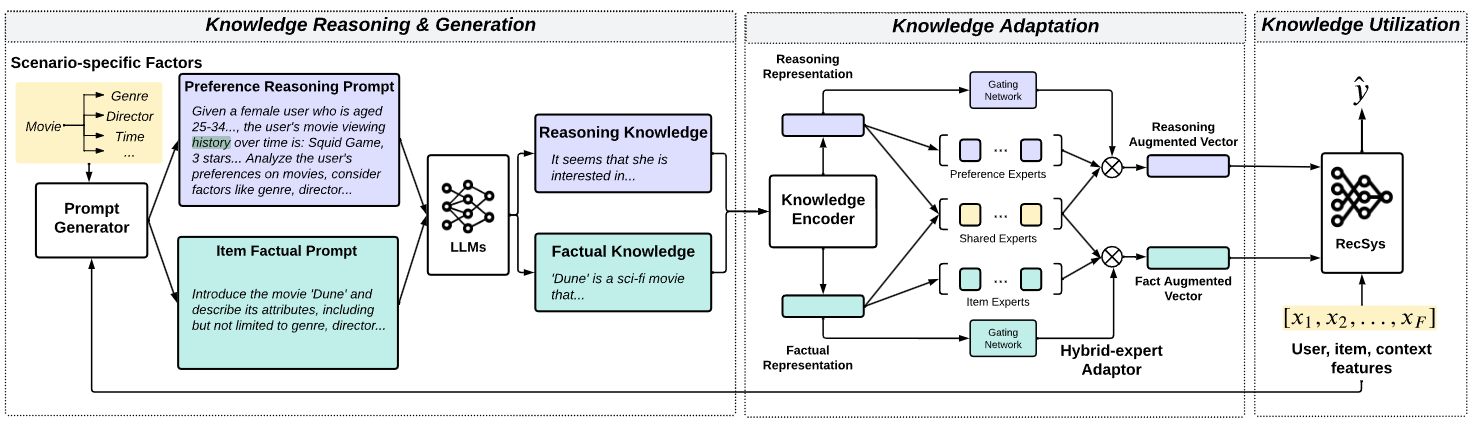
KAR Framework의 컨셉을 간략하게 설명하자면 다음과 같다.
Review data가 주어진 dataset을 User-wise Reasoning Knowledge와 Item-wise Factual Knowledge의 두 세트로 전처리하여 나눈다. 이 두 가지 Knowledge를 LLM의 Input으로 사용하여, 언어 모델을 통해 최종 Output으로 산출된 Vector를 기존에 존재하는 추천 시스템 모델에 Input으로 이용하여 모델의 성능을 올리는 것이다.
논문의 메소드에 대한 자세한 설명은 뒤의 내용에 이어질 것이다.
나는 KAR Framework를 응용하여 Amazon-book dataset 위에서 Reranking Task에 대한 실험을 진행하고, 우리가 이용하는 모델들의 Benchmarking 결과를 확인하여 실험 결과에 대한 비교분석을 진행하고자 한다.
2.1. Dataset Preprocessing
이 프로젝트에서 Dataset Preprocessing을 진행하는 목적은 데이터를 언어 모델에 입력하여 추천 시스템이 dataset의 정보를 잘 반영하도록 하기 위함이다.
2.1.1. K-Core Filtering (Decomposition)
가장 먼저 데이터 가공을 진행하기에 앞서 K-Core Filtering (Decomposition 이라고도 부른다.)을 진행한다. K-Core Filtering을 진행하는 이유는 아래와 같다.
- 너무 적은 상호작용을 가진 사용자와 아이템을 제거
- 데이터의 밀도(density)를 높임.
- Cold-Start 문제 완화.
Amazon-book dataset에는 User가 책(Item)에 리뷰와 평점을 남기는 형식으로 저장되어있고, 이에 따라 User와 Item 간에 상호작용이 발생하게 된다. 여기서 각 User와 Item을 그래프의 노드로 표현한다면 User와 Item 간의 상호작용 수 만큼 연결이 생긴다. K-Core Filtering은 그래프의 각 노드가 최소 K개의 연결을 가지도록 가공하는 과정이다.
Amazon-book dataset에서 K-Core Filtering은 아래와 같이 구현된다.
- User와 Item의 상호작용 횟수 계산, 조건을 만족하는지 확인
- 조건을 만족하지 않는 User나 Item 제거, 제거 후 다시 조건 확인
- 모든 User와 Item이 조건을 만족할 때 까지 반복
- User Core : 60 (각 User는 최소 60개의 Item과 상호작용)
- Item Core : 40 (각 Item은 최소 40명의 User와 상호작용)
(K-Core Filtering에 대한 더 자세한 설명은 아래의 youtube 영상에 잘 나와있으니 참고하시길 바란다. https://www.youtube.com/watch?v=rHVrgbc_3JA)
2.1.2. RS history&LM history processing
K-Core Filtering을 거친 Amazon-book dataset을 LLM에 Prompt로 입력하기 위해 User-wise Reasoning Knowledge와 Item-wise Factual Knowledge로 재생성한다. 1차적으로 User-wise history와 Item-wise history를 만들어야 한다.
User-wise history
- 최근 평가한 10개 Item 포함
- 긍정(rating > 4)과 부정(rating ≤ 4) 모두 포함
- Item ID, 속성(category, brand), rating 정보 포함
Item-wise history
- User당 하나의 이력
- 긍정(rating > 4) 데이터만 포함 (Reranking을 위해)
- 최대 길이 15개 Item
- Item ID, 속성 정보, rating 정보 포함
2.2. Prompt Generating & LLM Encoding
이렇게 생성한 history를 LLM이 입력하도록 Prompt로 가공하는 Factorization Prompting 과정이 진행된다. 이것은 User의 preference를 여러 주요 요인으로 Factorization하여 LLM이 효과적으로 외부 지식을 추출할 수 있도록 하는 과정이다.
- Preference reasoning prompt (User-wise Reasoning Knowledge)
User의 profile, 행동 이력 및 특정 요인을 바탕으로 사용자 선호 분석

- Item factual prompt (=Item-wise Factual Knowledge)
후보 항목의 설명과 시나리오 특정 요인을 포함하여 LLM이 사용자 선호와 일치하는 외부 지식을 보충하도록 유도

이렇게 만들어낸 Prompt를 LLM(Bert 이용)에 입력하여 최종적으로 추천 시스템에 이용할 수 있는 Augmented Vector로 변환하는 과정이 진행된다. 과정은 아래와 같다.
Knowledge Encoder
- Prompt Generating을 통해 생성한 history를 언어모델(Bert)에 입력
- 언어모델은 input prompt를 dense vector로 변환, aggregate 진행
- Final encoder output : preference reasoning representation (vector), Item factual representation (vector)
Hybrid-Expert Adaptor
- MLP(Multi-Layer Perceptron)으로 구성된 Shared Experts와 Dedicated Experts로 구성됨.
- Shared Experts는 User-wise Reasoning Knowledge와 Item-wise Factual Knowledge 사이의 공통적인 패턴을 포착
- Dedicated Experts는 각각의 Knowledge에 대해 고유한 패턴을 파악
- 언어모델이 생성한 dense vector를 추천 시스템에 입력하기 적합한 형태로 변환, 이를 통해 차원 불일치를 해결하며 noise를 감소시킴.
이러한 LLM Encoding을 통해 최종 Augmented Vector들은 기존의 Recommendation System에 추가 input feature로 활용된다. 모델은 이 vector들과 다른 feature들과의 상호작용을 통해 더 개인화된 추천을 할 수 있다!
2.3. Baseline Recommendation System Model
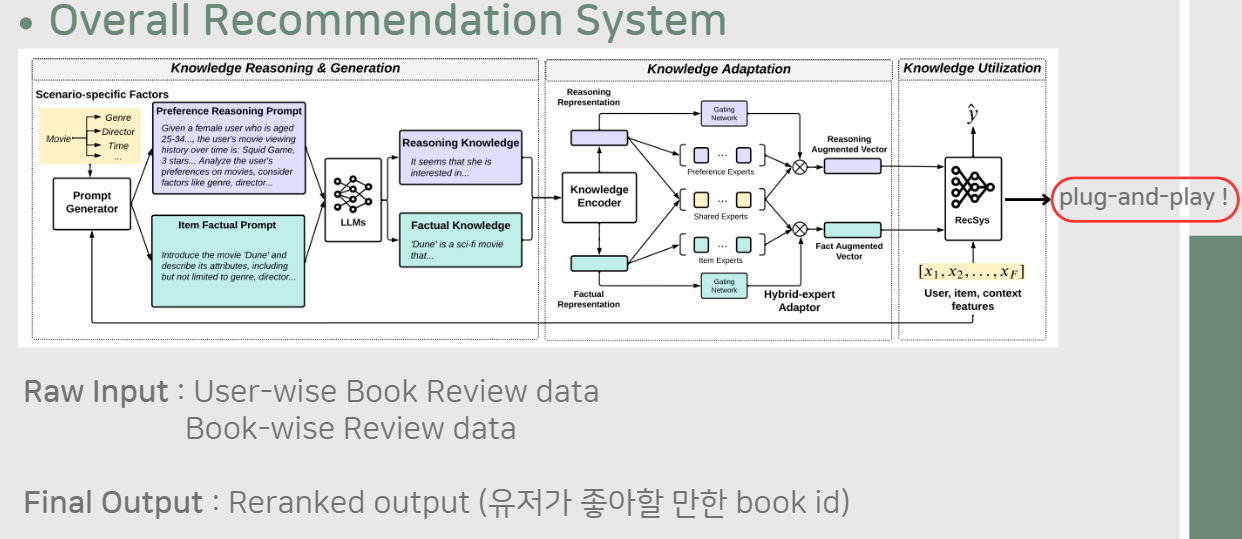
다시 한 번 프로젝트의 전체적인 모델 구조를 살펴보자. 우리의 목표는 Amazon-book dataset를 이용하여 Reranking 성능을 올리는 것이고, dataset의 Raw Input을 이용하여 Knowledge Adaption까지 완료하였다.
Knowledge Utilization을 위해 마지막 단계에서 Plug-and-Play로 이용할 수 있는 추천 시스템 모델을 선정해야 한다. 우리는 여기서 Baseline으로 Deep Listwise Context Model(DLCM)을 선정하였다.
DLCM 모델을 간단하게 설명하자면 다음과 같다.
Input Document Representations
- 표준 Learning-to-Rank 알고리즘을 이용하여 Query-Document pair를 Feature vector로 변환, Initial rank list 생성
Encoding the Listwise Local Context
- GRU를 이용하여 상위 검색 결과들의 Feature vector를 순차적으로 Encoding
- 가장 낮은 순위부터 높은 순의 순으로 문서 처리 → Local Context를 표현하는 Latent vector 생성
Reranking with the Local Context
- RNN의 hidden output과 생성된 Context vector 이용
- Local Ranking 함수를 적용하여 상위 문서들의 순위 재조정 (Reranking)
3. Experiments
3.1. Evaluation Benchmark
NDCG (Normalized Discounted Cumulative Gain)
순위가 매겨진 결과의 품질을 측정하는 지표
NDCG = (DCG/IDCG) (0~1 사이, 1에 가까울수록 좋은 성능)
- CG (Cummulative Gain) : 검색 결과의 관련성 점수(relevance)의 단순 합계 (여기선 click 유무)
- DCG (Discounted Cummulative Gain) : 순위가 낮을수록 관련성 점수에 로그 기반 할인(discount) 적용
- IDCG (Ideal Discounted Cummulative Gain) : 이상적인 순위에서 얻을 수 있는 최대 DCG

- NDCG가 높다는 건?
- 사용자와 가장 관련성이 높은 아이템들이 상위에 위치한다.
- 사용자에게 유용한 정보에 빠르게 접근 가능.
Baseline Result
DLCM을 이용하여 NDCG 벤치마킹을 진행한 결과는 다음과 같다.
- 실험 조건
- Train data size : 320,368 / Test data size : 35,834
- Epoch : 4epoch
- NDCG
- @1 : 0.54783 / @3 : 0.64346 / @5 : 0.63721 / @7 : 0.62926
- Hyper Paramter (KAR) - 모든 모델에서 동일 고정
- batch size / learning rate / weight-decay(L2) / expert_num / specific_expert_num
3.2. Experiment Models
LightGCN
- LightGCN은 기본적으로 Collaborative Filtering(rating prediction)을 위해 만들어짐.
- 한편 KAR의 세팅은 Reranking, CTR(Click-through-Rate)을 평가지표로 활용 (LightGCN의 기본 세팅과 맞지 않음).
- LightGCN의 손실함수를 변경하여 Experiment 진행 필요.
NGCF (Neural Graph Collaborative FIltering)
- 전체적으로 LightGCN과 같은 구조
- Dropoout / L2 Norm / Regularization 추가
- LigthGCN과 마찬가지로 기본 세팅의 변경 필요.
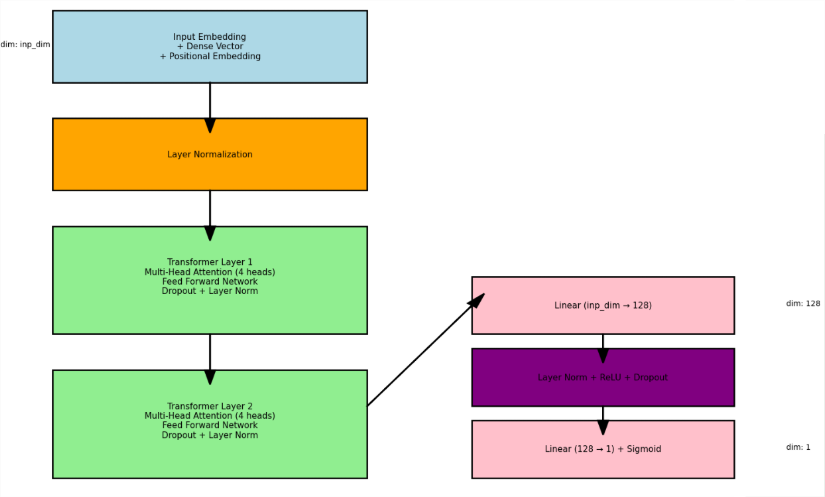
Transformer4Rerank (Custom)
- Transformer-Encoder based Reranking Score prediction model
- Multi-head Attention / FFN / Dropout / LayerNorm / Positional Embedding
- Leveraging Encoder Layer to Rerank
3.3. Experiment Results & Analysis
앞서 DLCM에서 진행했듯이 KAR 모델에 대한 Hyper Parameter는 모든 모델에서 같은 값으로 고정하여 진행하였다.
- batch size (256) / Learning rate (0.0005) / Weight decay (L2) (0.0) / Expert_num (4) / Specific_expert_num (5)
Experiment Results
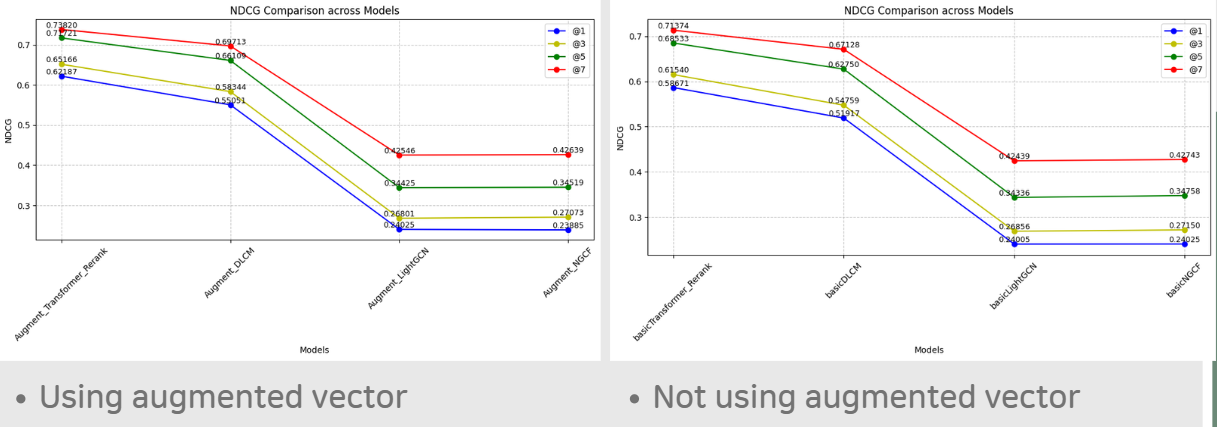
Experiment Analysis
- Graph-based 모델(LightGCN, NGCF)에서 Augmented vector를 이용하는 경우, NDCG 값이 떨어진다.
- KAR 아키텍처가 Graph-based model에서는 적합하게 사용되지 않음을 의미?
- Transformer 모델에 기반하여 생성해낸 Augmented vector가 Transformer-based Architecture의 추천 시스템 모델에서 가장 효율적이다.
- 모든 추천 시스템 모델이 KAR 아키텍처를 이용했을 때 향상되는 것은 아니다!
4. Conclusion & Future Work
Conclusion
Feature Interaction Model vs User Behavior Model
- 논문에 나와있듯이, KAR 아키텍처가 User Behavior Model(LightGCN, NGCF)보다 Feature Interaction Model(DLCM, Transformer4Rerank)에서 더 효과적으로 적용된 것을 직접 cumtomize한 모델로 재현하여 검증하였다.
Graph-based RS model is not effective in Reranking process
- Graph-based 모델 아키텍처의 한계 때문으로 판단된다.
Future Work
- Graph-based 아키텍처의 추천 시스템이 Reranking Task에서 유용하게 이용될 수 있도록 발전이 필요하다.
- KAR 아키텍처가 User Behavior Model에서 유용하게 응용될 수 있도록 발전되어야 한다.