Instruction fine-tuning, Reinforcement Learning from Human Feedback(RLHF) - 미완
Instruction fine-tuning, Reinforcement Learning from Human Feedback(RLHF)
Upload: Proceeding…
** 이 게시글은 아직 제작 과정 중에 있습니다! 내용이 부실하더라도 감안하여 주세요!
https://youtu.be/SXpJ9EmG3s4?si=73A2nJoUpjFW5sqC
본 게시글은 2023년도 스탠포드 강의 CS224n의 lecture 11 -prompting, rlhf의 내용을 정리한 게시글입니다.
https://gyeongminsu.github.io/posts/Zeroshotlearning&Fewshotlearning/ 게시글과 이어서 보시는 것을 추천드립니다.
0. Introduction
0-1. Language modeling ≠ assisting users
언어 모델들의 창발적 능력인 Zero-shot, Few-shot 등의 prompting을 이용하여 우리는 여러 작업을 수월하게 완수하는 것을 보았다.
그러나 근본적으로 아직 해결되지 않은 문제가 남아있다.
(Transformer의 Attention mechanism에 기반한) 언어 모델은, Input query가 주어졌을 때 그 다음으로 어떤 내용 가장 그럴싸하게 이어질 지 예측하도록 설계되어 있다. 다시 말해, 우리가 언어 모델로 하여금 정확히 원하는 것들과는 다른 목표로 설계되었다는 것이다.

그 예시로 ‘달 착륙’에 대해 소수의 문장으로 6살 아이에게 설명해달라고 prompt하였을 때, GPT-3는 우리가 일반적으로 생각하는 설명의 방향과는 매우 다른 답변을 한다는 것이다. 그저 서로 다른 여러 개의 task를 늘여놓기만 한다.
다시 말해 언어 모델은 사용하는 유저의 의도와는 다르게 설계되어 있다. 그렇다면, 우리는 어떻게 언어 모델을 우리의 의도에 맞게 사용하도록 조절할 수 있을까?
0-2. Pre-training / Fine-tuning
우선적으로, 언어 모델을 우리의 의도에 맞게끔 사용하기 위해 parameter를 학습하는 과정인 pre-training과 fine-tuning을 생각해볼 수 있다.
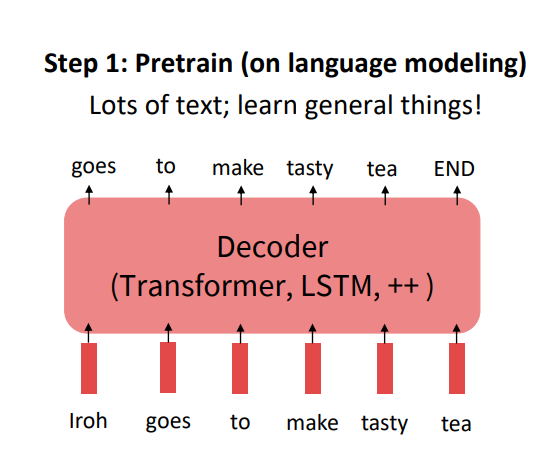
먼저, 가중치 초기화(parameter initialization)부터 시작하여 언어 모델을 NLP task에 적용하기 위해 pre-training을 진행한다.
그 다음 fine-tuning을 진행하지만, 이 과정은 우리가 알고 있던 기존의 fine-tuning과 살짝 다르다.
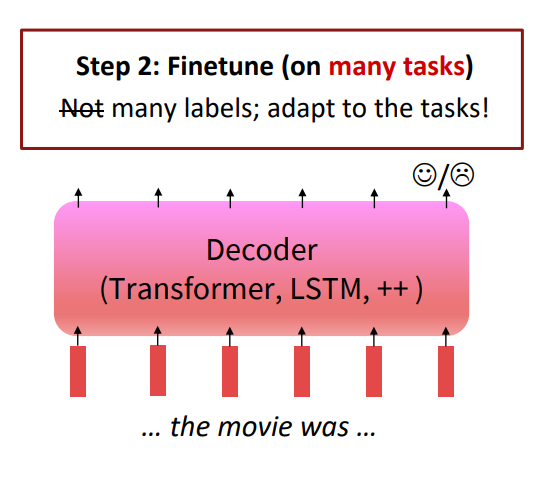
한 가지의 downstream task(ex. sentimental analysis)에만 fine-tuning을 진행하는 것이 아니라, 여러 가지의 다양한 task(many task)에 대한 fine-tuning을 진행한다. 이를 통해 다양한 새로운(unseen) task에도 성능을 보이도록 generalization performance를 향상시키는 것이다.
이것을 Instruction fine-tuning이라 부른다.
1. Instruction fine-tuning
1-1. Instruction fine-tuning의 진행 방법
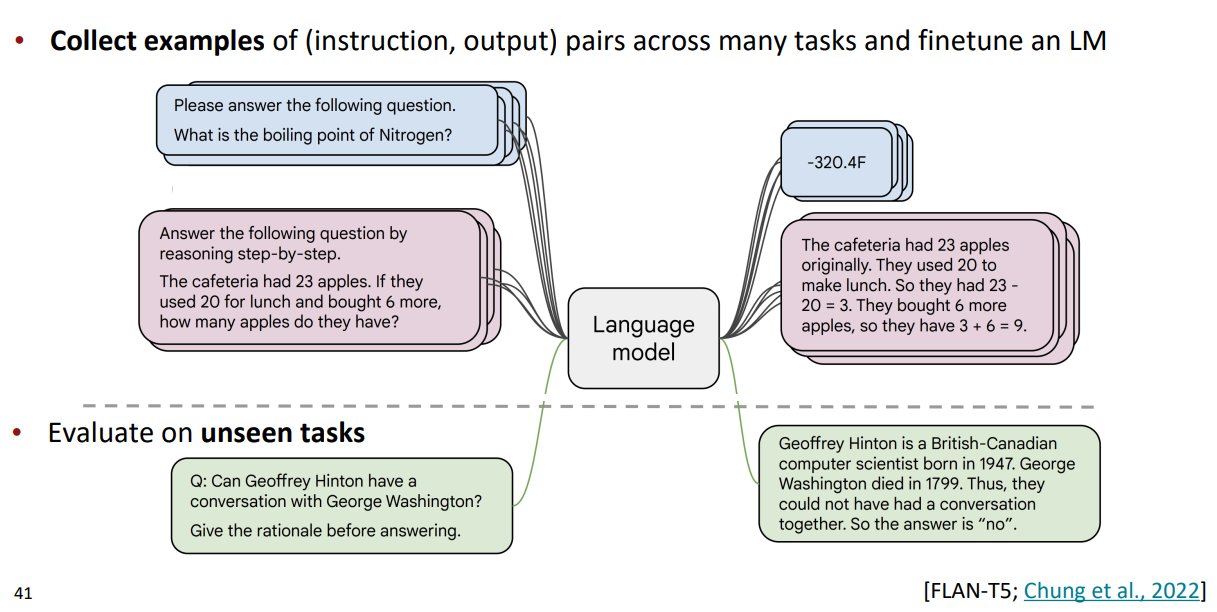
Instruction fine-tuning을 진행하는 순서는 다음과 같다.
- (instruction, output)의 쌍으로 이루어진 example data를 모은다.
- fine-tuning을 진행한 후 언어 모델의 unseen task에 대한 generalization evaluate를 진행한다.
fine-tuning을 위해 신경써야 할 가장 중요한 키 포인트 두 가지는 바로 fine-tuning에 사용되는 data와, model scale의 크기이다.
예를 들어 Super-NaturalInstructions dataset는 1,600개 이상의 task(Classification, sequence tagging, rewriting, translation QA, …)와, 3,000,000개 이상의 example data로 이루어져 있다.
여기서 들 수 있는 의문점으로, ‘이 Instruction fine-tuning의 과정이 pre-training이 아닌가?’ 라고 생각할 수 있다. 왜냐하면 모델 훈련 과정에서 어마어마하게 많은 데이터가 투입되기 때문이다.
사실 이 과정은 pre-training과 fine-tuning의 경계에 걸쳐 있다고 볼 수 있다. 그치만, Instruction fine-tuning은 언어 모델을 pre-training하는 것 보단 좀 더 task에 specific하게 학습을 진행하는 과정이라고 볼 수 있다.
이렇게 Instruction fine-tuning을 통해 여러 task에 대한 모델링을 진행한 후 한 가지의 질문이 따라온다. 우리는 과연 이 모델을 어떻게 평가(evaluate)할 수 있을까?
1-2. New benchmarks for multitask LMs
다양한 기능을 수행하는 언어 모델의 발전 이후 언어 모델을 평가하기 위한 벤치마크에 대한 연구도 굉장히 많이 진행되었다.

2021년에 발표된 MMLU(Massive Multitask Langauge Understanding)를 살펴보면 이는 언어 모델의 정말 다양한 task에 대한 퍼포먼스를 측정하는 것을 알 수 있다. 그리고 이러한 task는 일반적으로 고등학생~대학생 정도의 지식 수준이 필요한 task인 것을 알 수 있다.
벤치마크 지표를 잘 살펴보면, GPT-3가 매우 우수한 성능을 보여주진 않지만 모든 task에 대해서 Random baseline보단 높은 성능을 보여주고 있다.

또한 2022년에 발표된 Beyond the Imitation Game Benchmark, 줄여서 BIG-Bench라는 벤치마크도 존재한다. BIG-Bench는 엄청나게 많은 저자가 포함되어 있는데, 이는 엄청난 스케일의 협동적인 노력을 들인 것을 의미한다.

BIG-Bench에서 평가하는 task 중에는 매우 어렵고 전문적인 난이도의 task들도 포함되어 있다. 그 예시 중 하나로 텍스트와 특수문자를 조합하여 사진이나 그림을 흉내내는 ASCII art의 의미를 예측하는 것이 있다.
연구자들은 이렇게 언어 모델을 테스트하는 과정에서 매우 공을 들이고 있다.
1-3. Performance of Instruction fine-tuning
과연 Instruction fine-tuning을 진행한 모델의 성능은 얼마나 향상되었을까?

Span corruption을 통해 pre-train된 T5 encoder-decoder 모델에 Instruction fine-tuning을 이용하여 발전시킨 FLAN-T5 모델의 성능을 측정해 보았다. FLAN-T5 모델은 기존의 T5 모델에서 1,800개의 task에서 추가적인 학습을 진행한 모델이다.
이 모델의 BIG-bench와 MMLU 스코어의 평균을 비교해보면 모델의 크기와 상관없이 FLAN 계열의 모델이 훨씬 스코어가 높은 것을 볼 수 있다. 따라서 Instruction fine-tuning이 성능을 올린다는 것을 증명한 것이다. 그리고, 모델의 크기(파라미터)가 커질수록 Instruction fine-tuning을 통한 성능 상승폭도 더욱 커진다는 것 또한 주목할 만한 점이다.
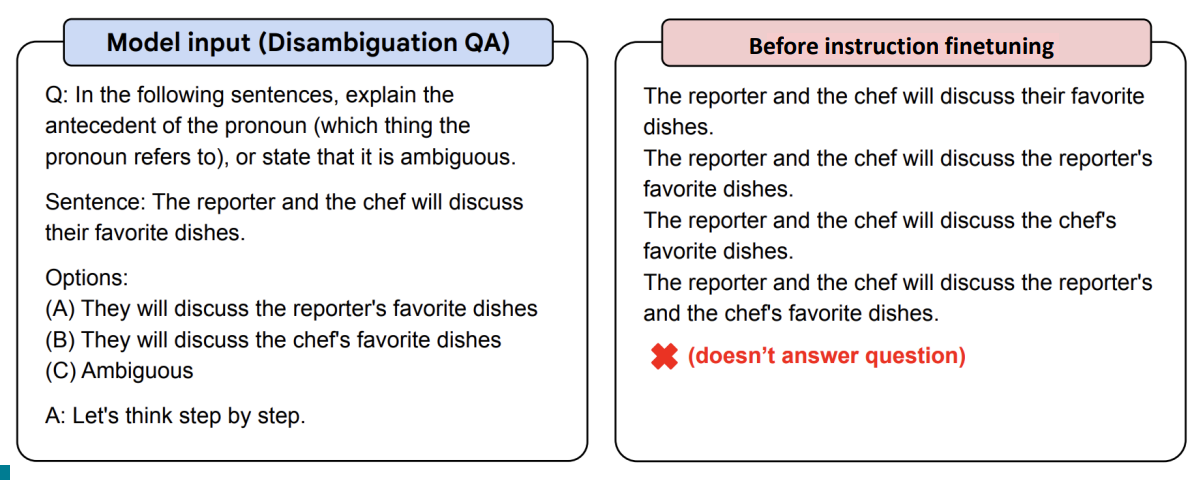
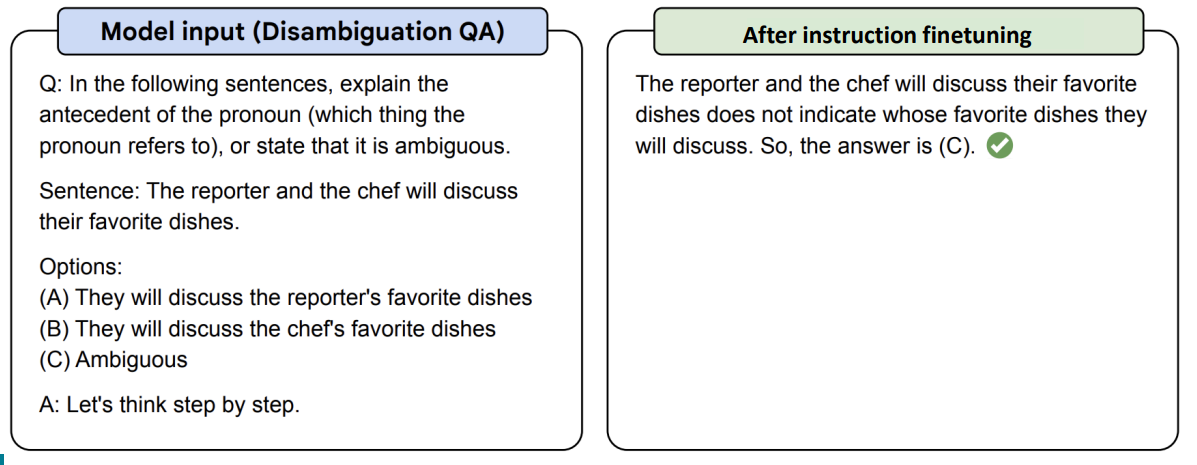
간단한 예시로, 위의 사진처럼 애매모호하게 주어진 질문에 대해 Instruction fine-tuning을 진행하지 않은 모델은 응답을 하지 못하였지만 Instruction fine-tuning을 진행한 후의 모델은 더 올바른 추론과 함께 문제에 대한 정답을 제시하였다.
결국 Instruction fine-tuning의 가장 큰 장점은 바로 처음 보는 생소한(unseen) task에서도 비교적으로 직관적이고 간단하게 수행할 수 있다는 점이다.
1-4. Limitations of instruction fine-tuning
Instruction fine-tuning의 단점 또한 분명히 존재한다. 명백히 개선해야하는 instruction fine-tuning의 단점은 다음과 같다.
- Ground-truth data를 수집하는 과정이 매우 어렵다
- Open-ended creative generation(창작을 위한 개방형 질문)과 같은 task의 정답을 구할 수 없다. 이러한 질문의 답은 여러 가지가 존재하기 때문이다. ex) Write me a story about a dog and her pet grasshopper.
- 언어 모델의 token-level에서의 penalizing은 모든 token에게 같은 가중치로 적용되지만, 실제 문맥상 어떤 에러는 다른 에러보다 더 최악일 수 있다.
- Instruction fine-tuning을 진행했음에도 불구하고, 여전히 언어 모델의 설계 목적과 이용자의 이용 목적(satisfy human preferences) 간의 차이가 존재한다.
그러면, 우리는 수학적 프레임워크를 이용하여 어떻게 이용자의 목적(human preferences)을 만족시킬 수 있을까?
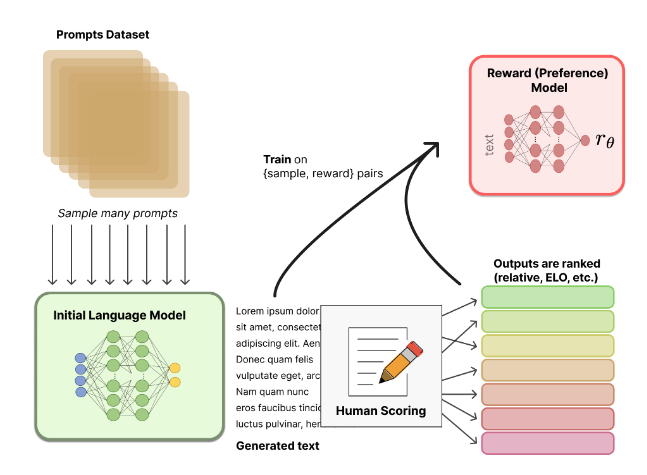
2. Reinforcement Learning from Human Feedback (RLHF)
2-1. Optimizing for human preferences
만약, 임의의 task(ex. 요약)에서 언어 모델을 training하고 있다고 생각을 해보자.
training하는 언어 모델을 $s$라고 했을 때, 우리는 모델 $s$의 요약에 대한 human reward(보상함수) : $R(s) \in \R$ 를 얻고자 한다. $R(s$$)$의 값이 클수록 요약을 잘 한 것으로 평가한다.

위 사진과 같이, 주어진 article에 대해 더 높은 보상 함수를 받은 요약을 더 잘 한 것(task를 더 잘 수행한 것!)으로 판단한다.
우리는 언어 모델을 통해 주어진 샘플에 대한 reward의 기댓값 (=$\Bbb{E}{\hat{\s} ~ p{\theta}}[R(\hat{\s})]$) 을 최대화해야 한다.
여기서 $p_{\theta}$는 주어진 파라미터 $\theta$에 대한 언어 모델 $p$를 의미한다. 그리고, 수학적 간결성을 위해 reward function에서 prompt나 task는 하나만 주어진 것으로 여긴다.
2-2. Reinforcement learning for the rescue
이렇게 주어진 reward function의 최적화는 강화학습을 통해 달성할 수 있다.
내용 전개를 하기에 앞서, 이 글을 읽는 독자의 수준은 강화학습에 대한 선행 지식이 없는 것으로 가정하고 진행할 것이다.
우선, 강화학습에 대한 간단한 설명을 시작하겠다.
강화학습 분야에 대한 연구는 시뮬레이션 최적화에 관한 문제를 해결하기 위해 몇십 년 전부터 진행되어 왔다. https://link.springer.com/article/10., https://ieeexplore.ieee.org/document/712192
2-3. How do we model human preferences?
any arbitrary, non-differentiable reward function R(s), we can train our language model to maximize expected reward
Not so fast!
- human-in-the-loop is expensive
- instead of directly asking humans for preferences, model their preferences as a seperate problem!
- human judgements are noisy and miscalibrated
- instead of asking for direct ratings, ask for pairwise comparisons, which can be more reliable
2-4. Limitations of RL + Reward Modeling
3. What’s next?
- RLHF is still a very underexplored and fast-moving area
- RLHF gets you further than instruction fine-tuning, but is still data expensive
- Recent work aims to alleviate such data requirements
- However, there are still many limitations of large LMs (size, hallucination) that may not be solvable with RLHF