머신러닝 해석 가능성의 현 주소와 미래 전망에 대해
이 게시글은 ‘파이썬을 활용한 머신러닝 해석 가능성’의 Ch 14. ‘머신러닝 해석 가능성, 그 다음은?’의 내용 30%, 제 사견 70%를 첨가하여 정리한 내용으로 만들어졌습니다.
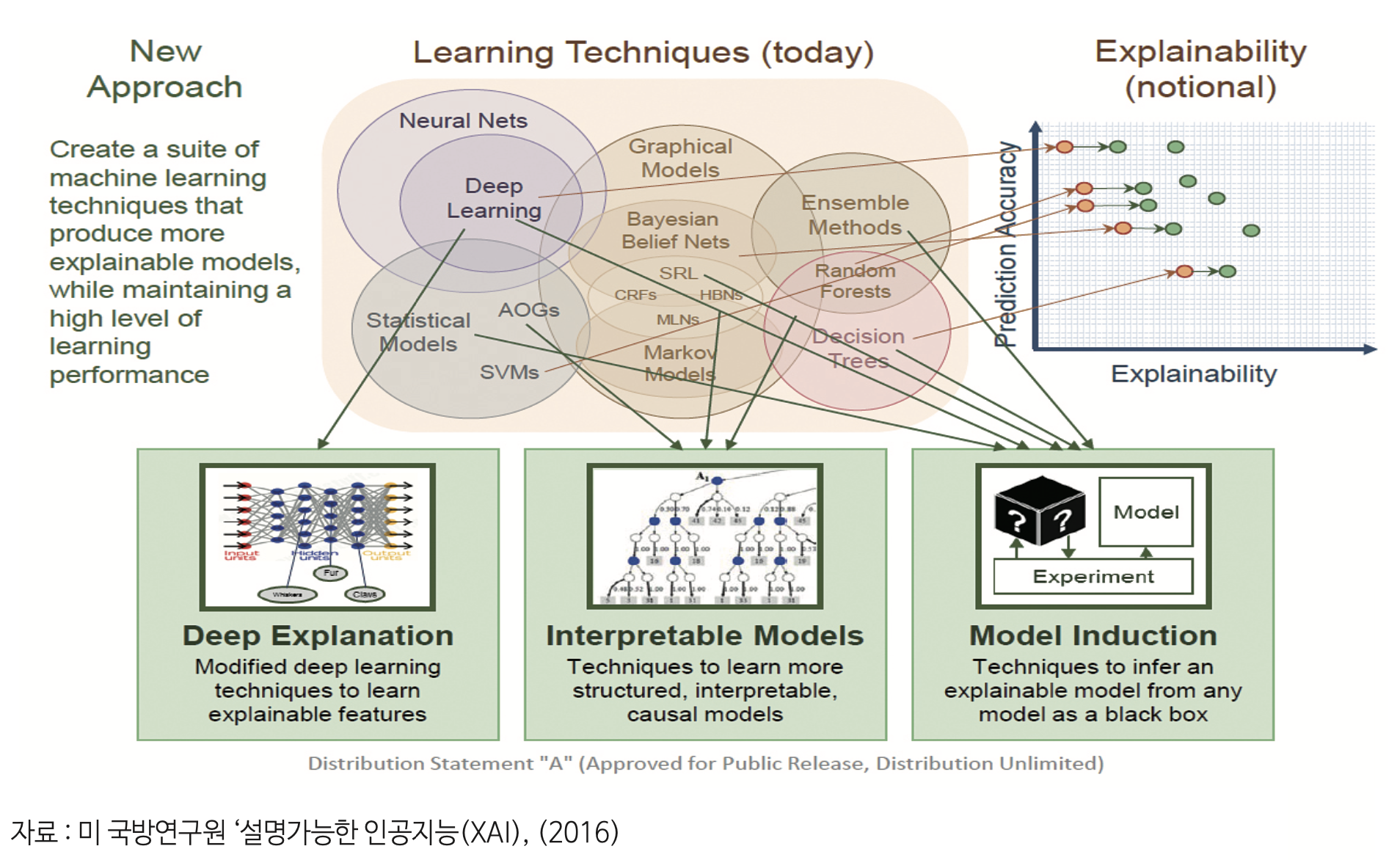
1. 머신러닝 해석 가능성의 현재 상황 이해
1-1. 전체 요약
ML 해석 가능성의 세 가지 주요 주제 : FAT + E
- 공정성 (Fairness)
- 책임성 (Accountability)
- 투명성 (Transparency)
- 윤리의식 (Ethics) : 가장 최근에 대두됨.
FATE를 통해 인공지능 시스템의 개선 기회를 제공. → 모델 해석 방법론을 활용해 모델 평가, 가정을 확인하거나 이의를 제기, 문체 찾기
목표는 현재 ML 워크플로우의 어떤 단계에 있는지에 따라 달라진다. 모델이 이미 운영 중인 경우 목표는 전체 메트릭 세트로 모델을 평가하는 것일 수 있지만, 모델이 아직 초기 개발 단계에 있는 경우 목표는 메트릭으로 발견할 수 없는 더 깊은 문제를 찾는 것일 수 있다.
어쨌든 이런 목표 중 어느 것도 상호 배타적이지 않으며, 모델이 잘 작동하는 것처럼 보이더라도 항상 문제를 찾고 가정에 대해 이의를 제기해야 한다.
또한 목표와 주요 관심사에 대한 완벽한 기법이란 없을 뿐만 아니라 모든 문제와 목표는 상호 연관돼 있기 때문에 가능한 한 많은 해석 방법론을 사용하는 것이 좋다. 즉, 일관성 없이는 정의도 없고 투명성 없이는 신뢰성도 없다.
모델의 공정성을 평가하는 것이 목표인 경우에도 모델 견고성에 대한 스트레스 테스트 과정을 거쳐야 한다. 또한 모든 feature의 중요성과 그 상호 작용을 이해해야 한다. 그렇지 않다면 예측이 견고하지 않고 투명하지 않은 것이 당연하다.
1-1. 진단

1-2. 처치
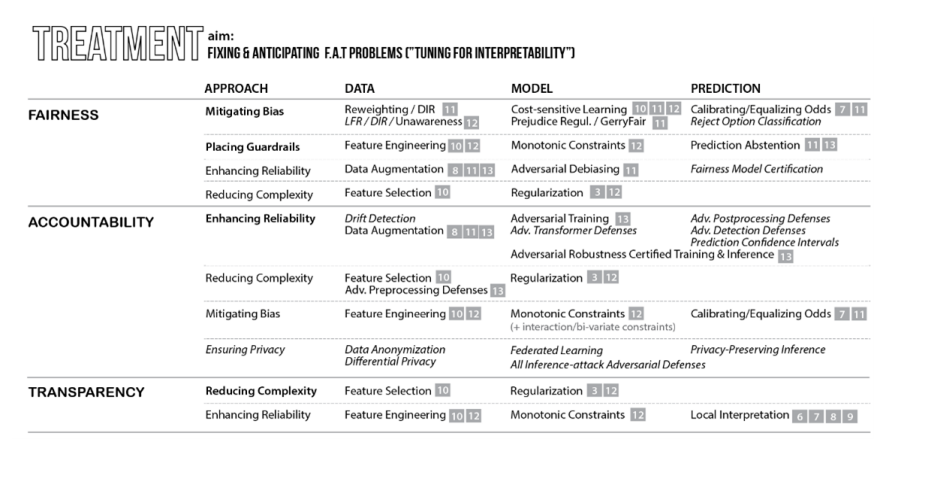
$\uparrow$ FAT 문제를 처리하기 위한 도구
처치를 위한 다섯 가지 접근법
- 편향 완화
- 편향을 처리하는 모든 수정 조치. 이 편향은 ML 워크플로우에 도입된 다른 편향과 함께 데이터의 샘플링 편향, 배제 편향, 편견 편향, 측정 편향 등을 말한다.
- 가드레일 배치
- 가드레일은 모델이 도메인 지식과 모순되지 않으면서 신뢰 구간이 없이도 예측할 수 있도록 보장하는 해결책이다.
- 신뢰성 향상
- 복잡성을 줄여 예측의 신뢰성과 일관성을 높이는 것이다.
- 복잡성 감소
- 희소성이 도입되는 모든 수단, 부수적인 효과로서 이 작업은 일반적으로 더 나은 일반화를 통해 신뢰성을 향상시킨다.
- 프라이버시 보호
- 제3자로부터 개인 데이터 및 모델 아키텍처를 보호하기 위한 모든 노력. 이 책에서는 이 접근법을 다루지 않았다.
처치 접근법 적용 영역
- 데이터(”전처리”) : 학습 데이터를 수정해 수행
- 모델(”프로세스 내”) : 모델, 모델의 매개변수 또는 학습 절차를 수정해 수행
- 예측(”후처리”) : 모델의 추론에 개입함으로써 수행
네 번째 영역 : 데이터 및 알고리즘 거버넌스
→ 특정 방법론이나 프레임워크를 명시하는 규제와 표준이 포함된다. 예를 들어 알고리즘 결정, 데이터 출처, 견고성 인증 등의 임곗값 등을 설명하기 위한 표준을 부과할 수 있다.
더 읽을거리 : https://gyeongminsu.github.io/posts/AIRegularization/
1-3. The Mythos of Model Interpretability
The mythos of Model Interpretability - Zachary C. Lipton, 2016
The Mythos of Model Interpretability.pdf
Abstract
머신러닝 지도학습 모델링은 예측 task에서 주목할만한 성과를 보여왔다. 그런데, 과연 그 모델을 신뢰(trust)할 수 있을까? 이 모델이 배포 환경에서 잘 작동할 수 있을까? 나아가서, 그 모델이 우리가 사는 세계에 대해 설명할 수 있을까?
우리는 머신러닝 모델에 대해서 좋은 성능 뿐 아니라 해석 가능성을 원하기도 한다. 그런데, 머신러닝의 해석 가능성은 아직 구체적으로 많이 밝혀지지 않은 분야이다.
현재 출판되는 논문들에서 표기되는 interpretability에 대해 각기 다른 의미를 내포하고 있고 다양한 뜻으로 사용하고 있다. 또한 모델의 어떤 항목이 이 설명 가능성에 기여하는 지에 관해 무수한 논지를 전개하고 있다.
이러한 모호함에도 불구하고 많은 논문에서 interpretability를 공리적으로(axiomatically) 얘기한 다음 자세한 설명은 생략하고 있다.
이 논문에서는 해석 가능성에 대한 여러 담론을 정리하고자 한다.
먼저 해석 가능성이라는 용어에 대해 사람들의 무의식에 깔린 기저를 조사하여 그 뜻의 부조화와 다양성이 존재하는 이유에 대해 밝힌다.
그 다음 해석 가능성을 부여하는 것으로 생각되는 모델 속성과 기술을 다루면서 인간에 대한 투명성과 사후 설명을 경쟁적인 개념으로 식별한다.
전체적으로 다양한 개념의 실현 가능성과 바람직성에 대해 논의하고, 그 다음 종종 제기되는 주장인 ‘선형 모델은 해석 가능하고 심층 신경망은 해석 불가능하다’는 주장에 대한 의문점을 제기할 것이다.
Contributions
- 머신러닝의 ‘해석 가능성’이라는 용어의 대대적인 합의를 위해, 이 문제를 공론화하여 비판적으로 논의하고 해석 가능성의 비호환성(사람간의 의미 차이)을 확인한다.
- 해당 분야의 실무자와 연구자 간의 의견 공유를 활발히 진행하여 비판적 글쓰기를 진행하여야 한다.
1-4. 실질적인 예시
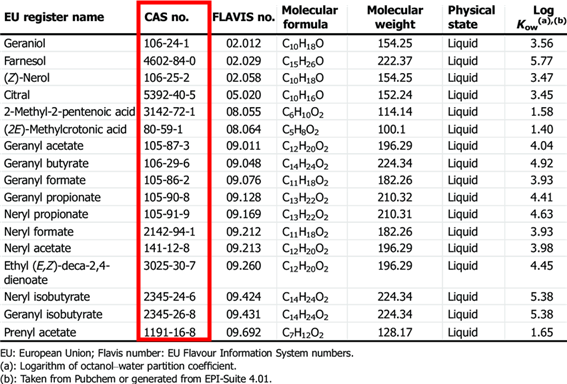
- 증상
- 20개의 제품 CAS no.와 독성 여부를 LLM(GPT-4)에게 입력했을 때(training), 나머지 200개 제품 CAS no.의 독성 여부 예측 정확도 100% 달성
- Discussion Point
- 언어 모델은 인터넷에서 생활화학제품, CAS number, 독성 여부가 적혀있는 표를 모조리 외워버린 걸까, 아니면 일련의 규칙을 만들어 예측률 100%를 달성한 걸까?
→ 아무도 모른다.
2. 머신러닝 해석 가능성의 미래에 대한 추측
현재 시대 : “AI의 서부 개척 시대”, “AI 골드 러시” → “**The Jet Age of machine learning**”
Toward the Jet Age of machine learning
내용 요약
- AI의 세 가지 도전 과제
- Efficiency
현대 ML application의 복잡한 모델과 대규모 데이터 세트 사용, 상당한 Computing 및 Storage 리소스가 필요하다. 이를 위해 다양한 하드웨어 솔루션(GPU, TPU, 병렬 CPU, FPGA, NPU 등)이 개발 중
→ 다른 하드웨어 기종 간의 효율적 사용, 전력 소비, 대기 시간 등과 관련된 서비스 수준 계약(Service Level Agreements, SLA)를 충족시키기 위한 ML software 재설계 필요.
- Automation
ML application은 계산 집약적(computationally intensive)일 뿐 아니라 노동 집약적(labor-intensive)이기도 하다.
→ 엔지니어의 training, debugging, publishing / 하이퍼파라미터 튜닝 / parallel hardware computing 등의 노동 집약적 과정 자동화 필요.
- Safety
모델이 어떻게 결정을 내리는지 이해하고 있는가? / 개인의 결정과 관련된 불확실성은 무엇인가? / 모델의 예측이 개인이나 사회에 직접적인 위협을 가하는가? / 윤리적으로 더 크게 영향을 미치는 ML application은 어떤 것인가?
ML application은 이러한 질문에 대한 직접적인 답변을 제공하지 않는다.
→ 단순한 rule-based가 아닌, 데이터 기반으로 작동하는 Machine Learning 알고리즘이 작동하는 이유에 대한 근본적 이해가 부족하다. 기본적인 과학적 이해를 높이는 것 외에도 잠재적인 안전 위험을 완화해야 한다! 새로운 프로세스를 통해 ML application에 내재된 복잡성과 불확실성을 해결해야 한다.
2-1. 머신러닝의 새로운 비전
미래의 ML 실무자의 역량 : 위험을 더 잘 인식하기
- 위험이란? → 예측 및 처방적 분석(prescriptive analytics)이라는 새로운 영역에서의 위험.
ex) 모든 종류의 편향과 가정, 알려진 데이터 및 잠재적인 데이터의 문제, 모델의 수학적 특성과 한계 등
FAT 원칙을 준수하는 모델은 여러 분야(AI 윤리학자, 변호사, 사회학자, 심리학자, 인간 중심 디자이너 그리고 수많은 여러 직업의 더 많은 참여)와의 긴밀한 통합이 필요하다.
AI 기술자 및 소프트웨어 엔지니어와 함께 그들은 모범 사례를 표준 및 규정으로 코딩하는 데 도움이 될 것이다.
2-1-1. 적절한 표준화 및 규제 시행
- 확실하게 견고하고 공정하다.
- TRACE 명령을 사용해 하나의 예측에 대한 추론을 설명할 수 있으며 경우에 따라 예측과 함께 추론을 전달해야 한다.
- 확신하지 못하는 예측은 기권할 수 있다.
- 모든 예측에 대해 신뢰 수준을 산출한다.
- 학습 데이터 출처(익명화 포함)와 저작권이 포함된 메타데이터를 보유하고, 필요한 경우 규제 준수 인증서 및 공개 원장(블록체인 가능)에 연결된 메타데이터를 보유한다.
- 디지털 워터마킹, 원본 데이터 보존 필요성 대두
- 특정 수준의 신뢰를 보장하기 위해 웹사이트와 마찬가지로 보안 인증서를 보유한다.
- 만료일이 있어야 하고, 만료 시 새 데이터로 재학습될 때까지 작업을 중지한다.
- 모델 진단에 실패하면 자동으로 오프라인 상태가 되고 통과될 때만 다시 온라인 상태가 된다.
- 정기적으로 모델을 재학습하고 모델 진단을 수행할 때 모델 가동 중지 시간을 피하기 위해 도움이 되는 CT/CI (Countinuous Training / Continuous Integration) 파이프라인을 보유한다.
- 추상화 단계의 고도화
- 치명적인 실패로 공적인 피해를 입힌 경우 공인 AI 감사관의 진단을 받는다.
2-2. 언어 모델의 관점
Deep Neural Network 기반의 Attention mechanism
- Encoder에서 encoding한 자연어 토큰을 기반으로 Decoder에서 생성하는 단어에 중요도를 매겨, 어떤 단어에 더 집중해야 할 지 계산한다.
- 입력된 시퀀스(sequence)의 다음 부분 가장 이어져 올 만한 토큰을 예측하여 내뱉는다 !
$\downarrow$ Attention mechanism의 시간 복잡도

일반적인 Self-Attention의 경우 토큰의 길이 $n$마다 $O(n^2)$의 시간 복잡도를 가진다.
$\hookrightarrow$ 계산 비용이 많이 든다.
2-2-1. Talk about interpretability of Attention mechanism
- Attention mechanism은 설명하는 능력이 존재할까?
→ Attention is not explanation vs Attention is not not explanation
$\uparrow$ 고려대 DSBA 연구실 설명
- Main Claims of Attention is not explanation
- Attention weight는 다른 설명력 측정 수단인 feature importance(e.g., gradient-based measures)와 상관관계가 낮다.
- 하나의 예측에 대한 Attention weight의 구성은 여러 가지가 존재할 수 있으므로, 이는 설명력이 있다고 볼 수 없다. → prediction에서 기존 Attention 가중치와 다른 결과를 산출해야 한다
- Main Claims of Attention is not not explanation
- Explanation의 다양한 정의와 J&W (Attention is not explanation 저자)의 불명확한 용어 정의
- J&W의 상관관계 기반 분석 연구의 설득 가능성 하락 (벤치마킹 지표의 attention mechanism 특성 반영 못함)
- 매우 높은 자유도로 설계되어 결과가 의미없는 실험과, 실험의 주장에 대한 직교성
- Conclusion : Attention == explanation의 여부는 Attention이 사용되는 모델의 아키텍처에 따라 결정된다.
$\downarrow$ 더 읽을거리
2-2-2. Replacement of RLHF
- RLHF(Reinforcement Learning from Human Feedback)의 계산적인 Overhead(by Reinforcement Learning)를 DPO(Direct Preference Optimization)로 대체하기 → Why?
RLHF의 특징
- Model-based RL Algorithm, Deterministic Policy 사용
- Model function이 non-differentiable</span<이다. $\therefore$ RL 사용.
- Actor model, Reward model, Critic model, Reference model 4가지 모델의 모델링이 필요 → 계산 오버헤드가 크다.
$\downarrow$ 강화학습에 대한 간단한 설명
DPO(Direct Performance Optimization)의 등장 (29 May 2023)

- Human preference를 강화학습의 Reward model 대신 classification loss를 통해 언어 모델을 직접 최적화한다 !
- Human preference를 직접 사용하여 언어 모델의 parameterization 진행
- RLHF와 비교해 안정적인 성능을 보이며 계산 요구량은 현저히 낮다.
$\downarrow$ 더 읽을거리
RLHF 외에 LLM이 피드백을 학습할 수 있는 방법은 무엇이 있을까?
3. 지식 표현 (Graph)
Vector Embedding → Graph Embedding(Node embedding / Relation embedding)으로 한 차원 더 높은 표현 가능
- Node embedding : node 간의 상대 거리를 보존할 목적으로 그래프의 노드를 연속적인 의미 공간(semantic space)에 임베딩
- Relation embedding : 그래프의 edge, 즉 node 간의 관계(relation)를 임베딩
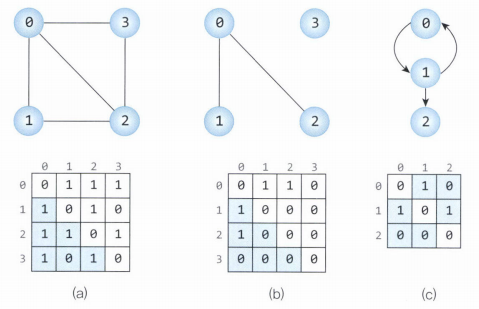
- Ontology
→ Class, Instance, Property, Relation 으로 지식 그래프 구성
Attention 기반의 LLM(Pre-trained)은 Ontological knowledge graph를 이해(encode)할 수 있을까?
Conclusion
- 사전 훈련된 LLM은 ontological knowledge의 일부를 기억(memorize)할 수 있고 ontology를 통한 존재론적 지식을 기반으로 추론(inference)를 진행할 수 있다. → 존재론적 지식에 대해 어느 정도 이해 가능!
- But, 암기(memorize)와 추론의 정확도가 완벽하지 않고 병렬적으로 표현된 지식을 처리할 때 어려움을 겪는다. ( $\because$ Attention 기반 언어 모델은 순서가 정해진 Vector로 학습하기 때문에)
- 현재의 LLM은 Ontology에 대한 지식과 이해가 제한적임.
4. Mamba with State Space Model (SSM) - replacement of Transformer ?

- Gemini의 의문점
$O(n^2)$의 Attention 계산으로 70만 개의 input token을 어떻게 한꺼번에 처리할까?
→ 아마 SSM이 쓰이진 않았을까…?
4-1. State Space Model (SSM)
- 기초 개념
- 물리학적 계(system)를 입력(input), 출력(output), 상태 변수(state variable)의 1차 미분 방정식으로 표현하는 수학적 모델. 기존에는 전기전자 공학 분야의 제어 이론에서 주로 사용되었다.
$x_i = Ax_{i-1} + Bu_i$ $x$ : hidden state, $u$ : input sentence
$y_i = Cx_i + Du_i$ $y$ : output sentence, $a, b, c, d$ : (Learnable Fixed) Parameter - 기존 제어 이론에서는 $a, b, c, d$를 고정. 하지만 ML에선 $a, b, c, d$를 학습하는 모델을 만들자!
- Attention 계산보다 시간적으로 훨씬 이득 → Why?
- Transformer와의 성능 비교
- 짧은 input token을 받을 경우 Perplexity에서 현저히 떨어진다.
- 긴 input token에 대해선 비교적으로 효율적이다.
- S4 (Structured State Space Sequence model) - Albert Gu. Jan. 2022
- SSM과 Transformer의 perplexity 성능 차이를 보완하기 위해 고안됨
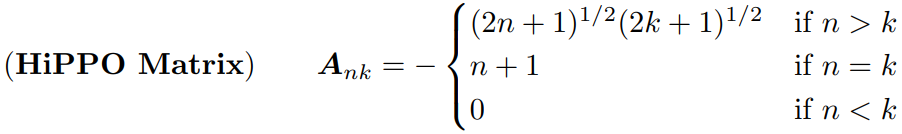
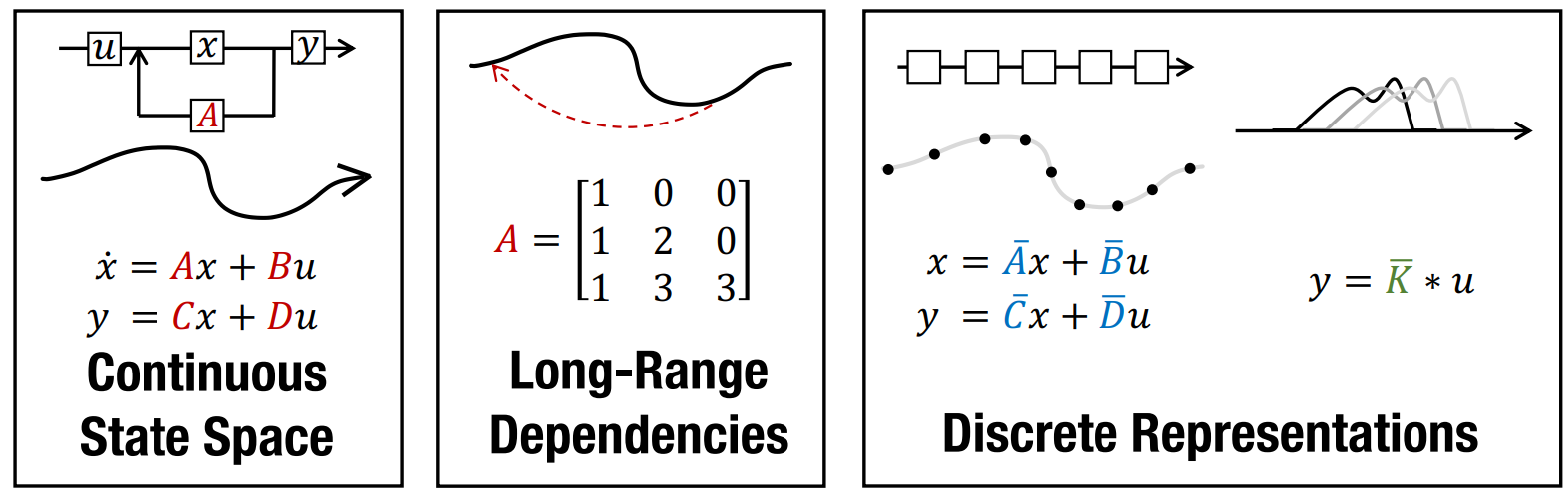
- HIPPO Matrix를 SSM의 parameter에 적용하여(시간의 변화에 따라 달라진다.) 연속적인 SSM을 이산적인 표현이 가능하게(Discrete Representations) 만들자!
- 시간에 따른 가변성을 만들기 위해 linear projection 연산이 수행된다. → 계산 효율성을 증가시킬 수 없을까?
Mamba - Albert Gu. Dec. 2023
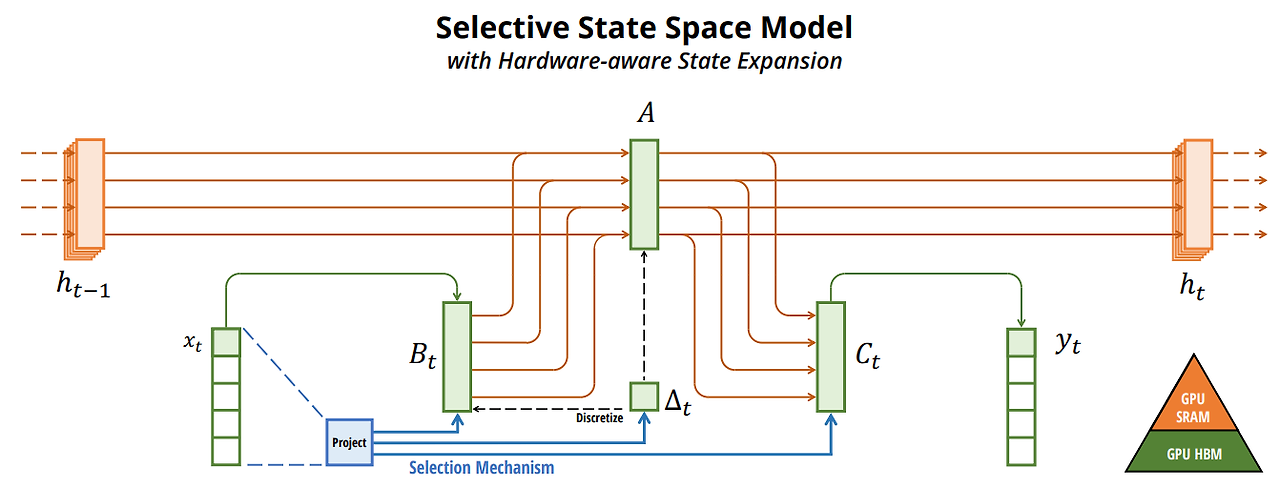
- Kernel Fusion
- GPU 내부에서 HBM(High Bandwidth Memory)이 아닌 SRAM(Static Random Access Memory, Cache)에서 parameter 저장 및 계산을 kernel로 융합하여 계산
- Recomputation
- 순전파 시 역전파에 필요한 intermediarte state를 저장하지 않고 역전파 시 재계산 → 메모리 공간복잡도 최적화
- Seletive State Spaces를 이용한 Linear-Time sequence modeling 달성
- Kernel Fusion
$\downarrow$ Mamba paper Link
4-2. Interpretability of SSM
- Input과 Output에 관한 상태 공간 식이 1차 선형 상미분방정식(1st-order ODE)으로 표현되어 있으므로, Attention model보다 훨씬 직관적인 해석이 가능하다.
- SSM은 과거의 데이터를 이용해 현재의 상태 표현을 나타내므로 그 자체로 causality를 가지고 있다.