Feature Selection & Feature Engineering 정리
이 게시글은 ‘파이썬을 활용한 머신러닝 해석 가능성’의 Ch 10. 해석 가능성을 위한 피처 선택과 피처 엔지니어링의 내용을 정리한 내용으로 만들어졌습니다.
Ch 10. 해석 가능성을 위한 피처 선택과 피처 엔지니어링
0. Introduction
Chapter 1, 2, 3 —> 복잡성이 머신러닝 해석 가능성을 어떻게 방해하는지에 대한 내용 전개.
예측 성능을 극대화하기 위해 복잡성이 필요.
But, 해석 가능성의 원칙인 공정성, 책임성, 투명성을 충족시키기 위해서는 모델에만 의존할 수 없다. 따라서 그 사이의 절충이 필요함.
10장은 해석 가능성을 위해 튜닝하는 방법에 초점을 맞춘 4개의 챕터 중 첫번째다.
해석 가능성을 향상시키는 방법 중 하나 : 피처 선택(feature selection)을 통한 방법.
→ 적절히 선택된 feature는 학습 속도 증가 & 모델 해석의 용이성 증가 등의 많은 이점을 준다.
r
일반적인 오해 : 복잡한 모델은 스스로 feature를 선택하면서 잘 수행될 수 있는데, 왜 귀찮게 feature를 선택해야 하는가?
→ 머신러닝 모델 알고리즘은 쓸모없는 feature를 처리할 수 있는 메커니즘을 갖고 있지만, 그 메커니즘이 완벽하진 않다. 그리고 남아도는 feature들이 많아질수록 과적합의 가능성이 증가한다. 과적합된 모델은 정확도가 더 높더라도 신뢰할 수 없다.
이러한 과적합을 피하기 위해 정규화와 같은 모델 메커니즘을 사용하는 것이 여전히 권장되긴 하지만, 그보다는 Feature selection이 첫 번째 단계다.
10장에서 다룰 주요 주제
- 상관성 없는 Feature의 영향력 이해
- 필터링 기반 Feature selection 방법론(ex. Spearan 상관계수) 탐색
- 임베디드 Feature selection 방법론(ex. Lasso & Ridge Regression)
- Wrapper(Sequantial Feature Selection), Hybrid(Recursive Featrure Elimination), GA(Genetic Algorithm) Feature selection 방법론 탐색
- Feature Selection 이후 Feature Engineering 고려
1. 미션
비영리단체의 운영 기금 마련
해마다 기부 수익은 증가했지만, 비영리단체가 직면한 문제가 몇 가지 존재한다.
- 기부자의 관심도는 변하기 때문에 한 해에 인기가 있었던 자선단체가 다음 해에는 잊혀질 수도 있다.
- 비영리단체 간의 경쟁 치열
- 인구통계학적 변화 : 미국의 평균적인 기부자는 1년에 두 번 기부를 하며 나이가 64세 이상이다.
잠재적인 기부자를 식별하는 것은 어려운 일이며, 이들에게 다가가기 위한 캠페인은 비용이 많이 들 수 있다.
비영리단체인 재향군인회(National Veterans Organizations)는 과거 기부자 약 190,000명의 메일링 리스트를 갖고 있으며 기부를 요청하기 위해 특별 우편물을 보내려고 한다. 그러나 특별 할인율을 적용하더라도 주소당 비용은 0.68달러이며 총 130,000 달러가 넘는다. 하지만 마케팅 예산은 35,000달러에 불과하다. 기부금 모금은 최우선 과제이므로 추가 비용을 정당화할 만큼 투자 수익률(ROI)이 높으면 그들은 기꺼이 예산을 확대할 의향이 있다.
제한된 예산의 사용을 최소화하기 위해 대량 우편 발송 대신에 과거의 기부금, 지리적 위치, 인구통계 데이터와 같이 이미 알려진 정보를 사용해 잠재적 기부자를 식별해 우편 발송을 하려고 한다. 그 외의 기부자들에게는 이메일을 통해 연락할 것이다. 이메일은 훨씬 저렴해 전체 수신자에게 월 1,000 달러를 넘지 않는다. 그들은 이 하이브리드 마케팅 계획이 훨씬 더 나은 결과를 낳기를 희망한다. 또한 고액 기부자는 개인적으로 전달되는 종이 우편물에 더 잘 응답하는 반면, 소규모 기부자들은 이메일에 더 잘 응답한다는 것을 인식하고 있다.
ML을 사용해 가장 가능성 있는 기부자를 식별할 뿐만 아니라 ROI도 보장하는 방식으로 모델을 만들어 달라고 도움을 요청. 이 모델은 ROI를 생성함에 있어 신뢰성도 있어야 한다.
비영리단체로부터 Train / Test 사이에 거의 균등하게 분할된 데이터셋을 받았다. Test 데이터셋의 모든 사람에게 우편물을 보내면 11,173 달러의 수익을 얻을 수 있지만 기부할 사람만 식별하는 방법을 사용하면 최대 수익은 73,136 달러에 도달한다. 목표는 높은 수익과 함께 합리적인 ROI를 달성하는 것이다. 캠페인을 실행할 때 전체 메일링 리스트에서 가장 가능성이 높은 기부자를 식별해 총 비용이 35,000 달러를 넘지 않기를 원한다. 그러나 데이터셋에는 435개의 칼럼이 있으며, 일부 간단한 통계적인 테스트와 모델링은 데이터가 너무 시끄럽기 때문에 과적합으로 인해 잠재적인 기부자에 대한 신뢰성에 한계가 있음을 보여준다.
2. 접근법
- 모든 Feature를 이용해 기본 모델 적합시키기 → Feature가 많을수록 과적합 경향 증가 살펴보
- 간단한 필터링 기반 방법론 ~ 고급 방법론까지 일련의 Feature selection 방법을 사용해 고객이 원하는 수익성 및 신뢰성 목표 달성 방법 결정.
- 최종 Feature 리스트 선택 후, 모델 해석 가능성을 높일 수 있는 Feature engineering 고려.
- 회귀 모델을 통한 예측 진행 후, 예측을 사용해 임곗값을 기준으로 분류를 할 것이며 따라서 튜닝할 임곗값이 하나만 있도록 하는 것이 가장 좋다는 것이다.
- 분류 모델의 경우 1달러 이상 기부한 레이블에 대한 임곗값 외에 예측된 확률에 대한 또 다른 임곗값이 필요하다. 회귀 모델은 기부금을 예측하며 이를 기반으로 임곗값 최적화 가능.
3. 준비
3-1. 라이브러리
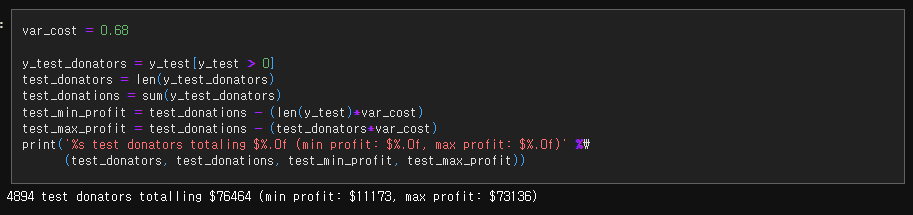

기본적으로 테스트 메일링 리스트에 있는 모든 사람에게 대량 우편을 보낸다면 약 11,000달러의 수익을 얻을 수 있지만, 이를 달성하려면 예산을 크게 초과해야 한다.
따라서 최소 수익보다 더 많은 수익을 안정적으로 산출하면서, 가급적이면 더 작은 비용으로 주어진 예산 내에서 캠페인을 수행하는 모델을 만들어야 한다.
4. 상관성 없는 피처의 영향력 이해
- Feature selection = Variable selection(변수 선택) = Attribute selection(속성 선택)
ML 모델 구성에 유용한 특정 Feature의 하위 집합을 자동 또는 수동으로 선택하는 방법론.
상관성이 없는 Feature는 학습 프로세스에 영향을 미쳐 과적합으로 인도할 수 있다. 따라서 학습에 부정적인 영향을 줄 수 있는 Feature를 제거하기 위한 몇 가지 전략이 필요하다. Feature의 더 작은 하위 집합을 선택하는 것은 다음과 같은 이점이 있다.
- 간단한 모델일수록 이해하기 더 쉽다.
- 변수 15개를 사용하는 모델의 Feature Importance는 150개의 변수를 사용하는 모델보다 훨씬 이해하기 쉽다.
- 학습 시간 단축
- 변수의 수 감소 시 → 컴퓨팅 비용 감소, 모델 학습 속도 향상, 추론 시간 빨라진다.
- 과적합 감소로 인해 향상되는 일반화
- 많은 변수는 잡음(noise)이 될 수 있다. ML 모델은 이러한 잡음도 학습하면서 과적합이 발생하고, 일반화 성능 하락 결과를 불러 일으킨다. 상관성이 없는(잡음이 되는) Feature를 제거하면 ML 모델의 일반화(Generalization) 성능 크게 향상 가능함.
- 반복적인 변수
- 데이터셋에는 일반적으로 공선성을 갖는 Feature들이 존재. → 반복성 의미 가능. 이런 경우 중요한 정보가 손실되지 않는 한 하나의 변수만 유지하고 다른 변수 삭제.
이제 기본적인 모델링을 통해서 너무 많은 Feature가 어떤 효과를 미치는 지에 대한 탐구를 시작한다.
4-1. 기본 모델 만들기
- XGBoost의 랜덤 포레스트 회귀모델인 XGBRFRegressor 사용 (max_depth = 4로 설정)
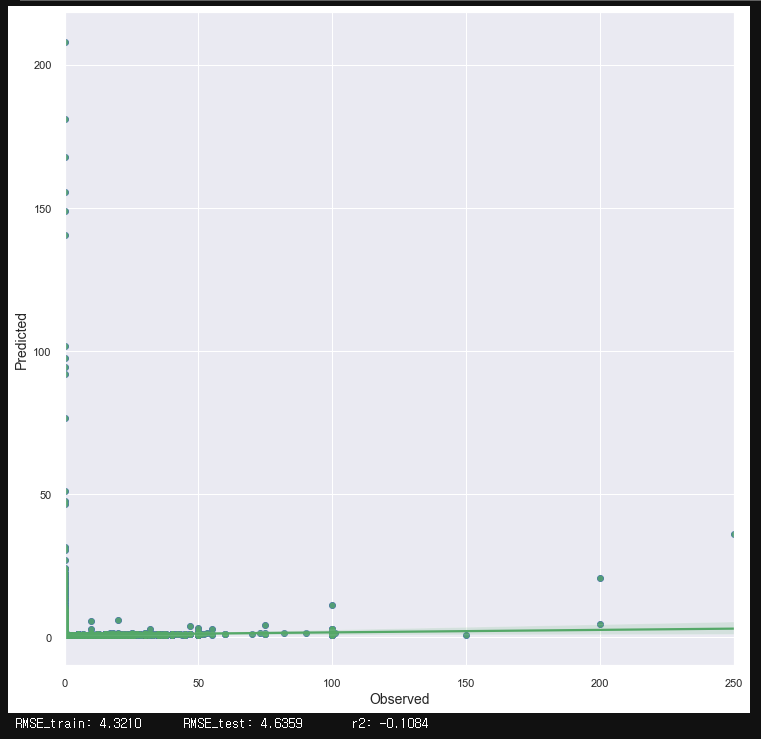
요약 Plot의 회귀가 대각선에 가까울수록 예측 성능이 높다. → XGBRFRegressor의 성능이 매우 낮음.
하지만 미션의 최종 목적은 분류이므로, 임곗값(Threshold) 조절을 통해 회귀 모델의 분류 성능을 측정해본다.
- 임곗값 조절을 통한 기본 모델의 분류 성능 측정
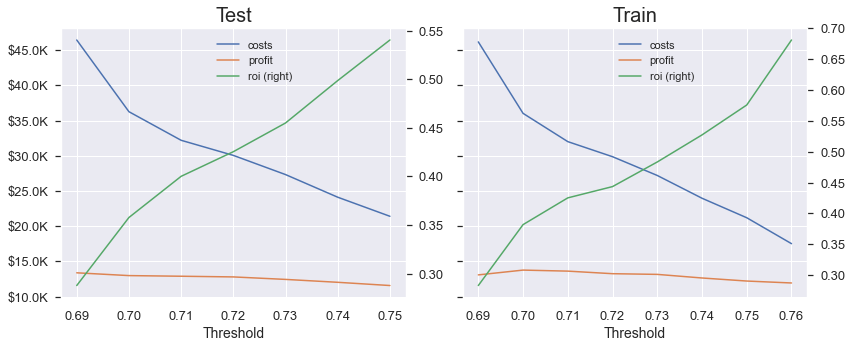
Train / Test 그래프의 추세가 거의 똑같다. → 과적합되지 않았다. ($\because$ 상대적으로 얕은 트리 사용)
중점적으로 볼 것 : ROI(투자 수익률) = $(profit - cost) / cost$
Test data에서의 ROI값이 양수로 관측되므로, 기본 모델의 회귀 성능은 떨어지지만 수익을 낼 수 있다고 볼 수 있다.
4-2. 서로 다른 최대 깊이로 기본 모델 학습
- max_depth = 12인 모델의 분류 성능 그래프
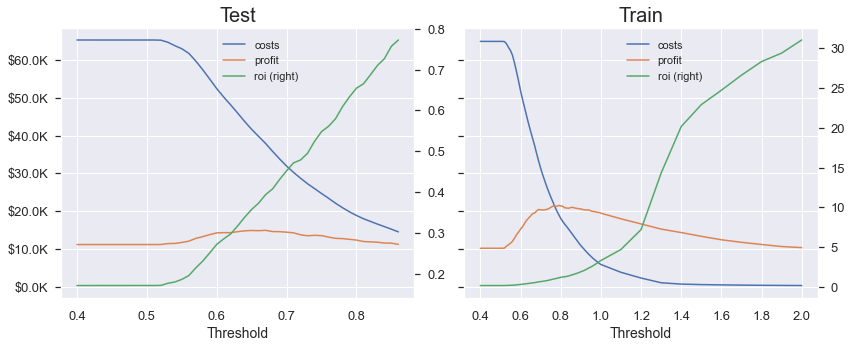
Test / Train 그래프의 차이가 존재한다.
Train dataset의 ROI가 Test dataset의 ROI보다 훨씬 높은 자릿수 기록. 임곗값의 범위도 매우 다르다.
→ 과적합 발생!
- 5 ~ 12 사이의 max depth로 각각 모델링 진행 결과
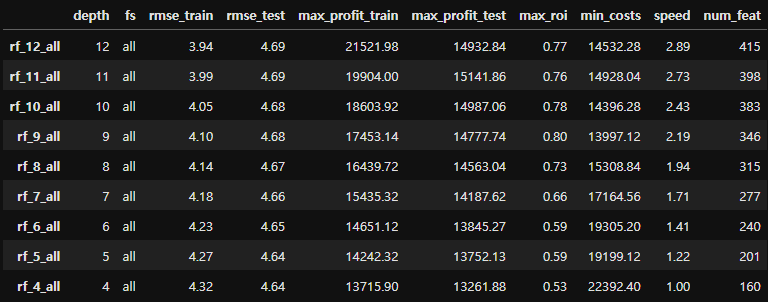
max_depth가 증가함에 따라 rmse_train은 감소, rmse_test는 증가한다. max_profit 또한 마찬가지의 추세를 보인다.
ROI는 max_depth와 학습 속도, 사용되는 feature의 수에 따라 증가하는 경향을 보인다.
5~12 사이의 max_depth에서 rf_11_all에서 max_profit_test가 가장 높으므로, rf_11 모델 기반으로 Feature Selection을 진행한다.
5. 필터링 기반 Feature 선택 방법론
ML을 사용하지 않고 데이터셋으로부터 Feature를 독립적으로 선택한다.
→ 변수의 특성에만 의존하며 상대적으로 효과적이고 계산 비용이 저렴하며 수행 속도 빠름. 가장 쉬운 방법이기 때문에, 일반적으로 모든 Feature 선택 파이프라인의 첫 번째 단계로 수행
두 가지 필터링 기반 방법론
- 단변량(univariate) : Feature 공간과 독립적으로 한 번에 하나의 Feature를 평가하고 등급을 매긴다. Feature 간의 문제를 고려하지 않기 때문에 필요 이상으로 필터링될 수 있다는 문제 존재.
- 다변량(multivariate) : 전체 Feature 공간과 그 내부의 Feature들이 서로 상호 작용하는 방식을 고려.
필터링 기반 방법론이 쓸모 있는 경우는 언제일까?
$\hookrightarrow$ 전반적으로 쓸모없고, 반복되고, 일정하고, 중복되고, 상관관계가 없는 feature를 제거할 때.
But, 필터링 기반 방법론에선 ML 모델만이 찾을 수 있는 복잡하고 비선형적이고 비단조적인 상관관계는 고려하지 않으므로 이런 관계가 두드러지는 데이터에서는 효과적이지 않다.
필터링 기반 방법론에는 기본, 상관관계, 순위의 세 가지 범주를 살펴본다.
5-1. 기본 필터링 기반 방법론
모델링 전 데이터 준비 단계, 특히 데이터 정리 단계에서 기본 필터링 방법론(basic filter method)를 사용한다. Why?
$\hookrightarrow$ 모델에 부정적인 영향을 미칠 수 있는 feature를 선택할 위험이 낮기 때문!
분산 임곗값을 사용한 상수 Feature 필터링
상수 feature는 train dataset에서 변화가 없으므로(Variance = 0) 정보를 전달하지 않는다 → 모델의 학습이 불가능!
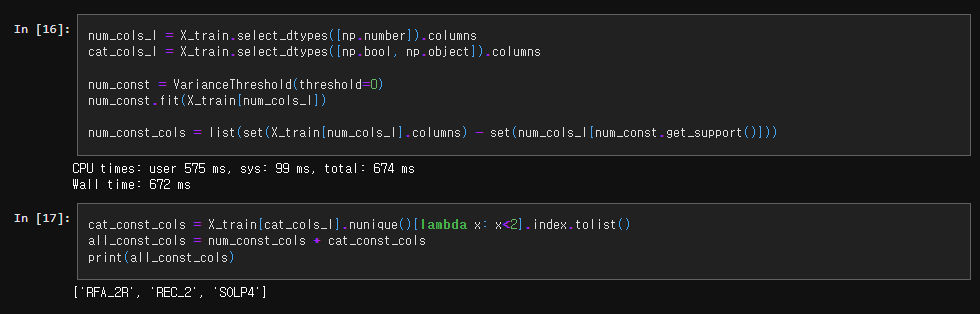
분산이 0인 feature를 학습에서 제외한다.
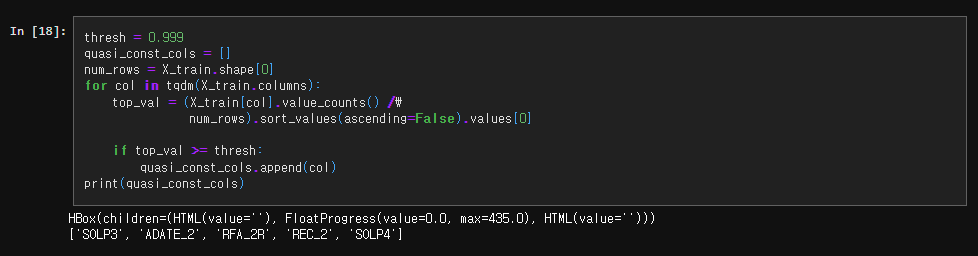
Value-Counts를 이용한 준상수 Feature 필터링
feature의 값들이 거의 동일한 feature를 준상수(quasi-constant) feature라 한다.
상수 필터링처럼 분산 임곗값을 사용하는 것은 높은 분산과 어느 정도의 일정함은 상호 배타적이지 않기 때문에 작동하지 않는다.
대신 모든 feature에 대해서 각 값에 대한 행 수를 반환하는 value_counts()를 적용하여, value_counts()의 수를 feature의 전체 행 수로 나눠 백분율을 구한 후 가장 높은 순으로 정렬한다.
중복 Feature 제거

Datafame의 row와 column을 반전시켜 중복된 column data 제거.
5-2. 상관관계 필터링 기반 방법론
상관계수 계산 방법
피어슨 상관계수(Pearson’s correlation coefficient)
: 두 Feature의 선형 상관관계를 -1~1 사이의 값으로 표현한다. 선형회귀와 마찬가지로 선형성, 정규성, 등분산성을 가정한다.
스피어만 순위 상관계수(Spearman’s rank correlation coefficient)
: 선형 상관 여부에 관계없이 두 Feature 간 단조성의 강도를 측정한다. -1~1 사이의 값으로 표현하며 0은 단조 상관관계가 없음을 의미한다. 분포에 대한 가정 X, 연속형 Feature 및 이산형 Feature 모두에서 작동할 수 있다. 그러나 비단조적 관계에서는 약점이 존재.
켄달 타우 상관계수(Kendall’s tau correlation coefficient)
: Feature 간의 서수적 상관성(순위)을 측정한다. -1~1 사이의 범위지만 각각 낮음과 높음을 의미한다. 이산 Feature에 유용하다.
https://butter-shower.tistory.com/231 ← 켄달 타우에 대한 자세한 설명
현재 미션의 dataset에는 연속형과 이산형 변수 모두 포함되어 있다. 이에 대해 선형 가정(linear assumption)을 할 수 없으므로 Spearman이 올바른 선택이다.
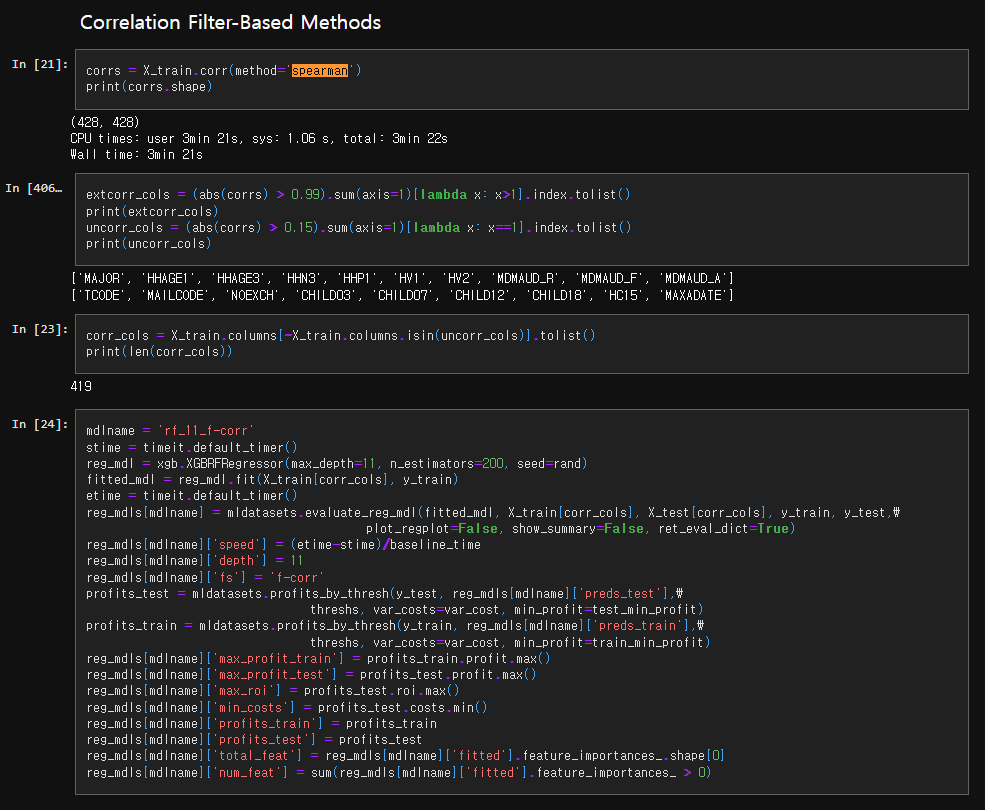
extcorr_cols : 자신이 아닌 다른 feature와 상관관계가 매우 높은(절댓값이 0.99 이상) feature의 리스트
uncorr_cols : 자신이 아닌 다른 feature와 상관관계가 없는(절댓값이 0.15 미만) feature의 리스트
두 리스트에 있는 feature와 다른 feature들, 종속변수 간의 상관관계를 유심히 살펴볼 필요 존재!
5-3. 순위 필터링 기반 방법론
목표 변수에 대한 Feature의 강도를 평가하는 통계적 단변량 순위 테스트를 기반으로 진행한다.
다음은 가장 인기 있는 방법 중 일부.
ANOVA F-검정
: 분산분석을 통해 Feature와 목표 변수 간의 선형 종속성을 측정한다. 정규성, 독립성, 등분산성 등 선형회귀와 유사한 가정을 진행한다.
카이제곱(chi-square) 독립성 검정
: 범주형 변수(음수 X)와 이진 목표 변수 간의 상관성을 측정한다. → 분류 문제에만 적합!
상호 정보량(Mutual Information)
: == 쿨백-라이블러 발산(KL Divergence)으로 논의된 개념이다. 정보 이론에서 파생되었다.
https://hyunw.kim/blog/2017/10/27/KL_divergence.html → KL Divergence에 대한 설명글
현재 미션에서의 데이터셋은 Feature 간 선형성을 보장할 수 없고, 대부분이 범주형 데이터가 아니다.
$\therefore$ MI가 가장 적절한 옵션!
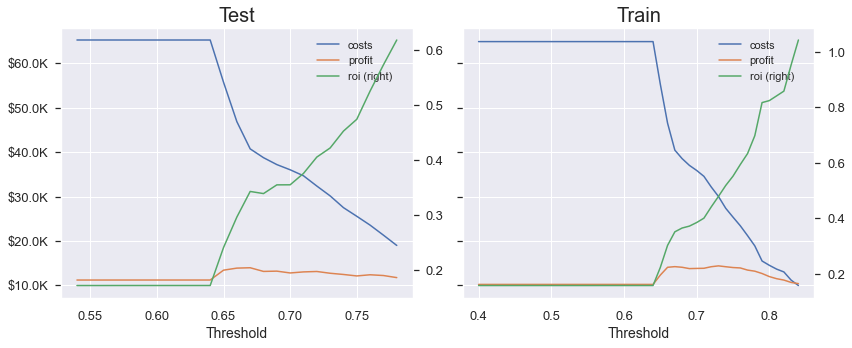
MIC(MI Classification) 모델을 적합한 결과, Test dataset과 Train dataset 사이에 차이가 존재하긴 하지만 과적합의 정도가 줄어든 것을 확인할 수 있다.
5-4. 필터링 기반 방법론 비교
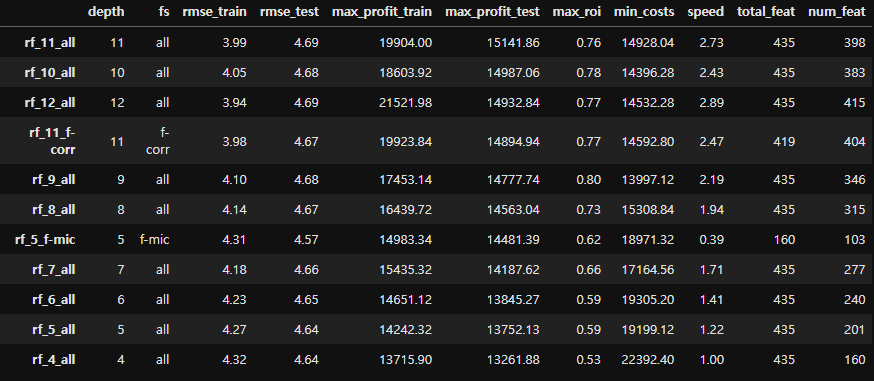
(max_profit_train - max_profit_test)의 값을 살펴보면, MIC 모델(rf_5_f-mic)이 가장 적게 과적합된 것을 알 수 있다.
심지어, 더 많은 feature를 가지고, 더 복잡한 모델보다 순위가 높고 다른 모델보다 학습하는 데 시간이 적게 걸렸다!
상관관계 필터링 모델(rf_11_f-corr)이 동일한 max_depth를 가진 모델보다 성능이 낮음을 알 수 있다. → 중요한 feature가 제거됐음을 시사
임곗값을 맹목적으로 설정하고 임곗값의 상위를 갖는 모든 feature를 제거하는 것은 실수로 유용한 feature를 제거할 수 있다는 문제가 생긴다.
극도로 상관된 feature와 극도로 상관되지 않은 feature가 모두 쓸모없는 것은 아니므로 추가적인 확인이 필요하다. → 사람의 감독이 덜 필요하도록 교차 검증이 포함된 방법론이 필요.
6. 임베디드 피처 선택 방법론 탐색
모델이 학습 중에 자연스럽게 Feature를 선택하도록 모델 자체에 임베디드된 방법론이다.
트리 기반 모델
: Feature importance의 임곗값을 지정하여 feature 선택하기, 또는 트리의 깊이를 제한함으로써 적은 수의 feature를 선택하도록 한다.
계수가 있는 정규화 모델
: 많은 모델 클래스에서 L1, L2, Elastic-net을 통해 패널티 기반 정규화를 진행한다. But, 이런 정규화 과정이 특별히 어떤 feature가 페널티를 받을지 결정할 수 있는 계수나 매개변수를 갖고 있지는 않다.
따라서 페널티 기반 정규화를 통합해 feature별 계수를 출력하는 몇 가지 모델 클래스가 존재한다.
LASSO (Least Absolute Shrinkage and Selection Operator)
: 손실함수에서 L1 penalty를 적용하기 때문에 LASSO는 계수를 0으로 설정할 수 있다.
LARS (Least-Angle RegreSsion)
: LASSO와 유사하지만 벡터 기반이며 고차원 데이터에 더 적합하다. 또한 서로 동등하게 상관된 feature에 대해 더 공정하다.
Ridge Regression
: 손실함수에서 L2 penalty를 사용하므로 상관성이 없는 계수를 0이 아닌 0에 가깝게 줄일 수 있다.
Elasticnet Regression
: L1, L2 penalty를 모두 사용한다.
Logistic Regression
: solver에 따라 L1, L2 또는 Elasticnet penalty를 처리할 수 있다.
또한 LASSO-LARS와 같이 LARS 알고리즘을 사용하는 LASSO 적합, 또는 이와 동일하지만 모델에 따라 AIC 또는 BIC 기준을 사용하는 LASSO-LARS-IC 등과 같은 몇 가지 변형도 있다.
AIC (Akaike’s Information Criteria)
: 정보 이론에 기초한 상대적인 적합도 지수
BIC (Bayesian Information Criteria)
: AIC와 공식이 비슷하지만 페널티 항이 다름.
https://blog.naver.com/sw4r/222956130752 → AIC, BIC에 대한 설명글
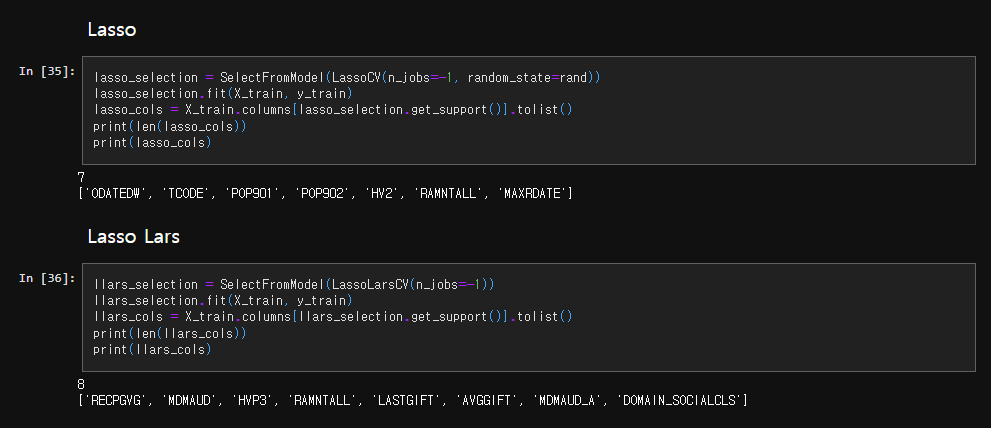
- LASSO Model의 교차 검증(CV)를 이용한 feature 추출
→ 7개를 제외한 모든 feature의 계수를 0으로 축소.
- LASSO-LARs Model의 교차 검증(CV)을 이용한 feature 추출
→ 8개를 제외한 모든 feature의 계수를 0으로 축소.
ASSO와 LASSO-LARs 의 feature list 사이에 겹치는 부분이 없다!
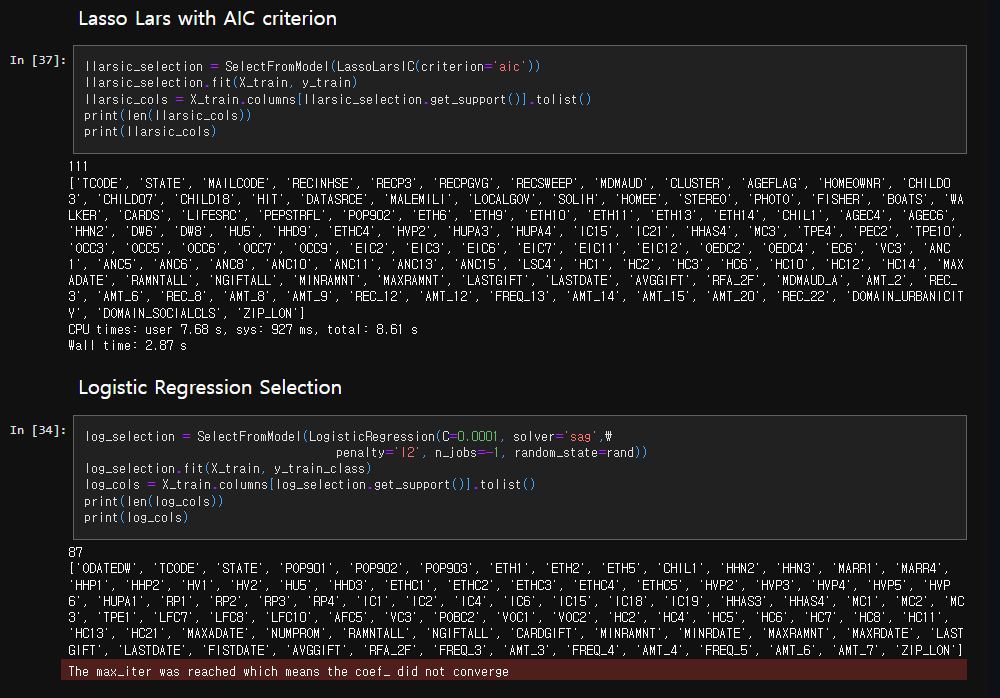
- AIC model selection을 LASSO_LARs에 통합한 LassoLarsIC 사용
→ 111개의 feature 사용 (덜 보수적임)
- L2 penalty를 이용한 로지스틱 회귀 사용
→ 87개의 feature 사용
지금까지 실행한 임베디드 피처 선택 모델의 성능을 확인해보자.
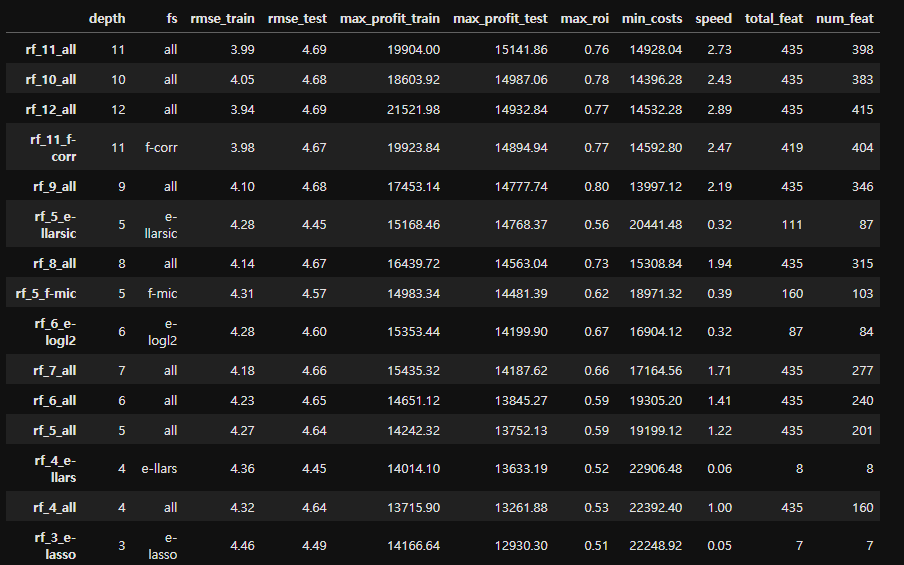
임베디드 모델이 지금까지 실행한 다른 모델보다 훨씬 빠르게 학습하고, 복잡성이 동일한 다른 모델보다 수익이 높다!
7. 래퍼, 하이브리드, 고급 피처 선택 방법론 탐색
1~6까지 언급된 Feature Selection 방법론은 모델 적합 & 더 단순한 화이트박스 모델 적합이 필요하지 않기 때문에, 계산 비용이 저렴하다.
7절에서는 사용 가능한 튜닝 옵션이 많이 있는, 좀 더 철저한 여러 방법론을 살펴본다.
7-1. 래퍼(Wrapper) 방법론
- 모델의 다양한 Feature 조합 중 최고의 목적함수 스코어를 달성하는 조합을 선택! → 여러 가지 조합 검색 방법
- 순차 순방향 선택 (SFS, Sequential Forward Selection)
: 0개부터 Feature를 하나씩 추가하면서 선택한다.
순차 순방향 유동적 선택 (SFFS, Sequential Forward Floating Selection)
: SFS와 동일한 방식을 모든 Feature가 추가될 때까지 수행하며, 목적함수가 증가하는 한 하나를 제거할 수 없다.
순차 역방향 선택 (SBS, Sequential Backward Selection)
: Feature 전체로 시작해서 하나씩 제거한다.
순차 역방향 유동적 선택 (SFBS, Sequential Floating Backward Selection)
: SBS와 동일한 방식을 모든 Feature가 제거될 때까지 수행하며, 목적함수가 증가하는 한 하나를 추가할 수 있다.
철처한 피처 선택 (EFS, Exhaustive Feature Selection)
: 가능한 한 모든 feature 조합에 대해 평가한다. (브루트포스)
양방향 검색 (BSD, BiDirectional Search)
: 순방향 및 역방향 Feature Selection을 동시에 허용해 하나의 고유한 솔루션을 얻는다.
위의 6가지 래퍼 방법론은 문제를 조각내 하나씩 풀면서 즉각적인 이점을 바탕으로 조각을 선택하기 때문에, 그리디 알고리즘(greedy algorithm)이다. 글로벌 최댓값보단 로컬 최댓값을 찾는 데 더 적합한 접근 방식을 취한다.
feature의 수에 따라, 특히 조합이 증가하는 EFS와 같은 경우에는 계산 비용이 너무 많이 들어 실용적이지 않을 수 있다.
일반적으로 래퍼 방법론은 필터링 기반 방법론이 할 수 없는 중요한 feature 상호 작용을 감지하기 때문에 과적합을 줄이고 예측 성능을 높이는 feature 하위 집합을 찾는 데 매우 효과적이다.
7-2. 하이브리드(Hybrid) 방법론
Feature 435개의 경우 이 중 27개를 선택하면 1,042개 이상의 조합이 생긴다. 따라서 EFS를 진행하면 너무 많은 계산 필요. → 필터링&임베디드의 효율성 + 래퍼의 철저한 접근 방식 섞기!
ex ) 필터링/임베디드 방법론을 사용해 상위 10개 Feature만 추출한 후 해당 Feature에 대해서만 EFS 또는 SBS를 수행한다.
7-2-1. 재귀적 Feature 제거(Recursive Feature Elimination)
모델의 고유 매개변수를 사용해 feature의 순위를 지정한 후 가장 낮은 순위의 feature만 제거하는 방법. → 임베디드 + 래퍼 방식의 하이브리드!
모델 고유의 feature importance를 도출할 수 있는 모델에서만 사용할 수 있다
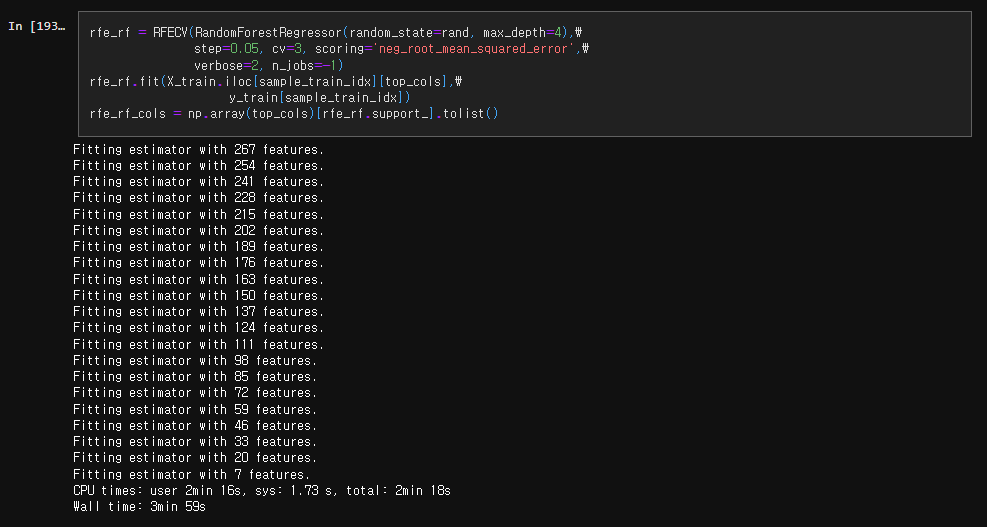
RandomForestRegressor를 이용하여 매 step마다 모든 feature의 5%를 제거한다.
7-3. 고급 피처(Advanced) 선택 방법론
7-3-1. 차원 축소
주성분 분석(PCA)와 같은 일부 차원 축소 방법은 feature에 의해 설명되는 분산을 반환할 수 있다. 요인 분석 등의 다른 경우에는 다른 출력으로부터 파생될 수 있다. 설명 가능한 분산은 feature importance의 순위를 정하는 데 사용될 수 있다.
PCA의 경우 주성분의 수를 feature의 수로 유지하고, SVD를 통한 분산 분해를 통해 Feature의 순위 판별한다.

7-3-2. 모델 독립적 Feature Importance
7-3-3. 유전 알고리즘(Genetic Algorithm)
다윈의 자연 선택에서 영감을 얻은 확률적 글로벌 최적화 기법으로, 래퍼 방법과 유사하게 모델을 래핑한다. 그러나 GA는 반복이 아니라 염색체 개체군을 포함하는 세대(generation)을 갖는다. 각 염색체는 Feature Space의 이진 표현이며 여기서 1은 feature 선택, 0은 선택하지 않음을 의미한다. 각 세대는 다음 작업을 통해 생성된다.
선택(selection)
: 자연 선택과 마찬가지로 부분적으로는 무작위(탐색), 부분적으로는 이미 효과가 있었던 것(이용)을 기반으로 한다. 효과가 있었다는 것은 그것의 적합성이다. 적합성은 래퍼 방법과 매우 유사한 “채점자”에 의해 평가된다. 적합이 불량한 염색체는 제거되는 반면에 적합성이 좋은 염색체는 “교차”를 통해 재생산된다.
교차(crossover)
: 무작위로 각 부모의 좋은 비트(bits) 또는 feature의 일부가 자식에게 전달된다.
돌연변이(mutation)
: 염색체가 효과적인 것으로 증명된 경우에도 낮은 비율로 돌연변이가 주어지며, 이는 때때로 염색체의 비트 또는 feature 중 하나를 돌연변이시키거나 뒤집는다.

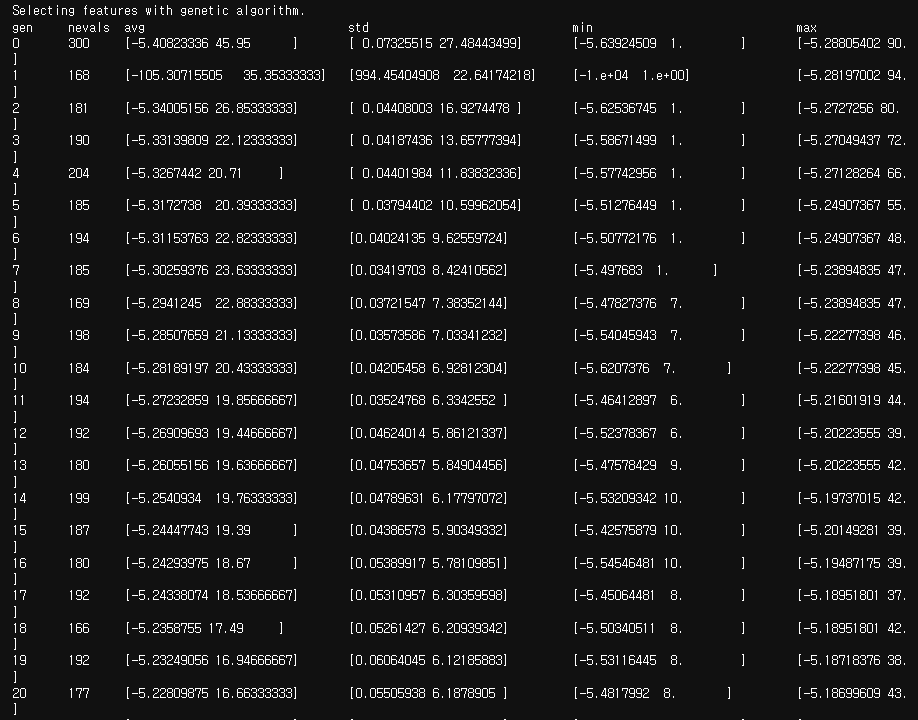
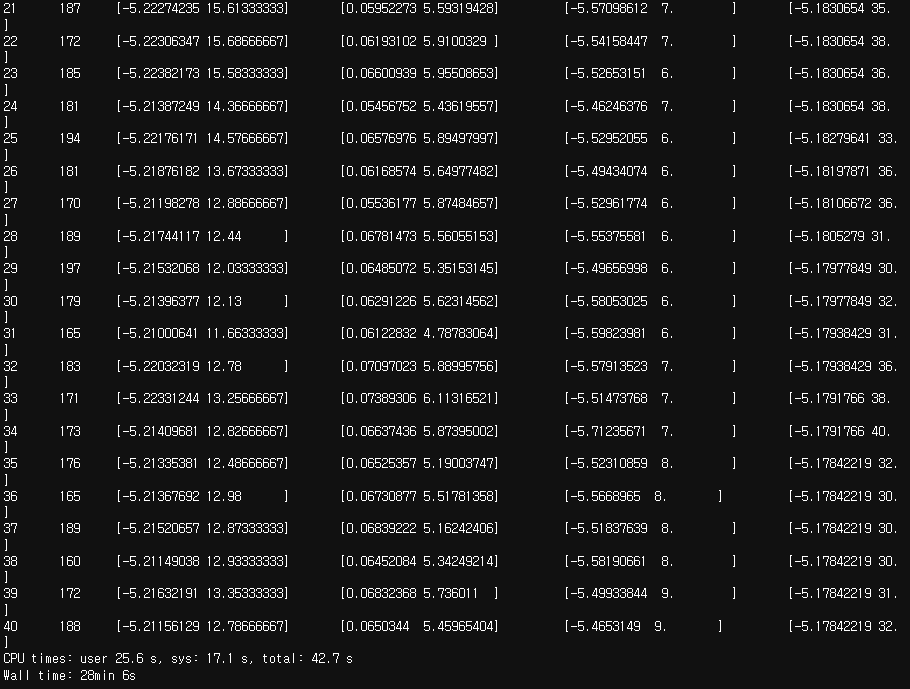
40세대(Generation)에 걸쳐 GA 모델 학습 진행.
7-4. 모든 Feature Selection 모델 평가
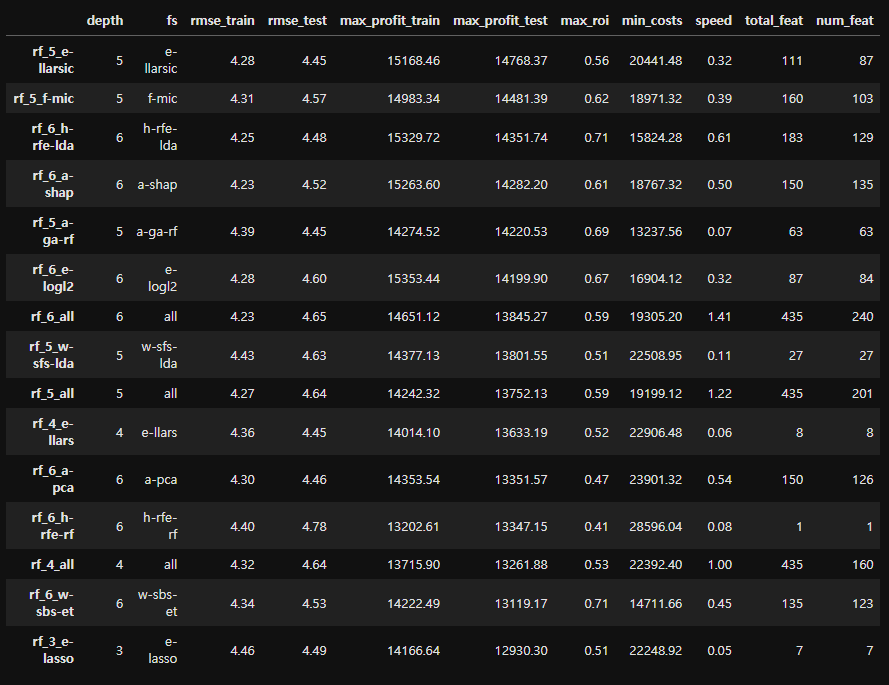
Feature Selection model이 모든 feature를 선택하는 모델보다 수익성이 더 높다!
또한 AIC를 사용한 임베디드 Lasso-LARS(e-llarsic) 방법과 MIC 필터 방법(f-mic)이 다른 모든 래퍼, 하이브리드, 고급 방법론을 능가한다.
But, 래퍼, 하이브리드, 고급 방법론의 시간 효율성을 위해 프로세스 속도를 높이고자 학습 dataset의 샘플만을 사용하였다.
→ 여유를 두고 많은 방법론을 실행해보면 다른 결과가 나올 수도 있다.
8. 피처 엔지니어링 고려
지금까지 설명한 Feature Selection 간의 비교를 통하여 최종 모델을 정할 수 있다. 어떤 모델을 사용할 지 확정한 후에 Feature Engineering을 통해 정해진 모델을 더 개선할 수 있는지 여부를 평가하려고 한다.
더 쉬운 모델 해석 및 이해
: 예를 들어 feature에 직관적이지 않은 척도가 있거나, 척도는 직관적이지만 분포를 이해하기 어려운 경우가 있다. 모델 성능을 악화시키지 않는 선에서 해석 방법론의 출력을 더 잘 이해하기 위해, feature를 변환하는 방법이 있다. 엔지니어링된 더 많은 feature에 대해 모델을 학습시키면 어떤 feature가 효과가 있고 왜 효과가 있는지 알게 된다.
개별 Feature에 가드레일 배치
: Feature의 분포가 고르지 않고 모델이 Feature 히스토그램의 희소 영역이나 영향력 있는 이상치가 존재하는 곳에 과적합되는 경향이 있다.
직관적이지 않은 상호 작용 제거
: 모델에서 발견한 일부 상호 작용은 의미가 없으며, Feature들 간의 상관관계가 때문에 존재할 뿐 항상 타당한 것은 아닐 수도 있다. 이들은 혼란을 일으키는 변수일 수도 있고, 반복적인 변수일 수도 있다. 상호 작용 Feature를 엔지니어링하거나 반복적인 Feature를 제거하기로 결정할 수 있다.
비영리단체는 Lasso-LARS를 feature를 선택한 모델(e-llarsic)을 사용하기로 정했지만, 더 개선할 수 있는 지의 여부를 평가하려 한다.
예측 성능을 약간만 향상시킬 뿐 대부분이 잡음인 300개 이상의 feature를 제거했으므로 상관성이 높은 feature만 남았다.
But, GA(a-ga-rf)에 의해 선택한 63개의 feature가 111개의 feature와 동일한 RMSE를 생성하였다는 것을 볼 수 있다. 즉, 이 추가 feature들은 수익성을 향상시키지만 RMSE는 향상시키지는 못했다.
현재 111개의 feature가 남았지만 이 feature들이 목표변수 또는 다른 feature들과 서로 어떻게 상관되어 있는 지 전혀 모른다. → 먼저 feature importance 방법론을 통해 중요도 파악.
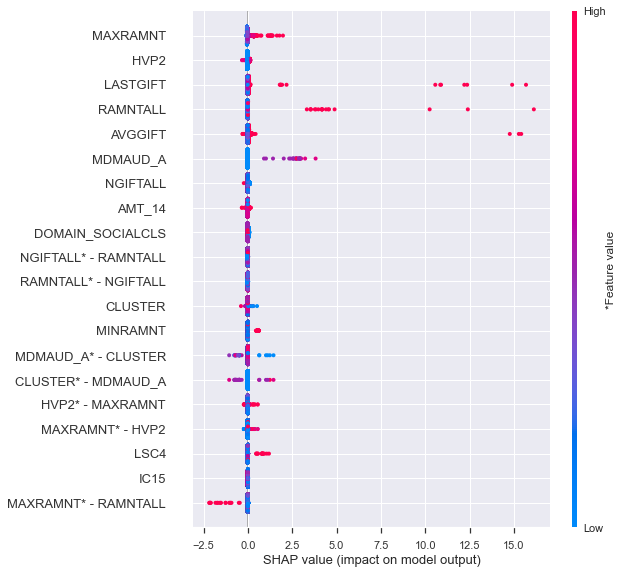
- SHAP 상호 작용 요약 Plot
feature 및 상호 작용의 순위와 이들 간의 몇 가지 공통점을 식별하는 데 유용함. 그러나 이 상호 작용에 대한 더 깊은 조사를 위해, 상호 작용의 영향력을 정량화해야 한다.
→ SHAP 값의 절대 평균 기준상위 상호 작용만 포함하는 히트맵 생성
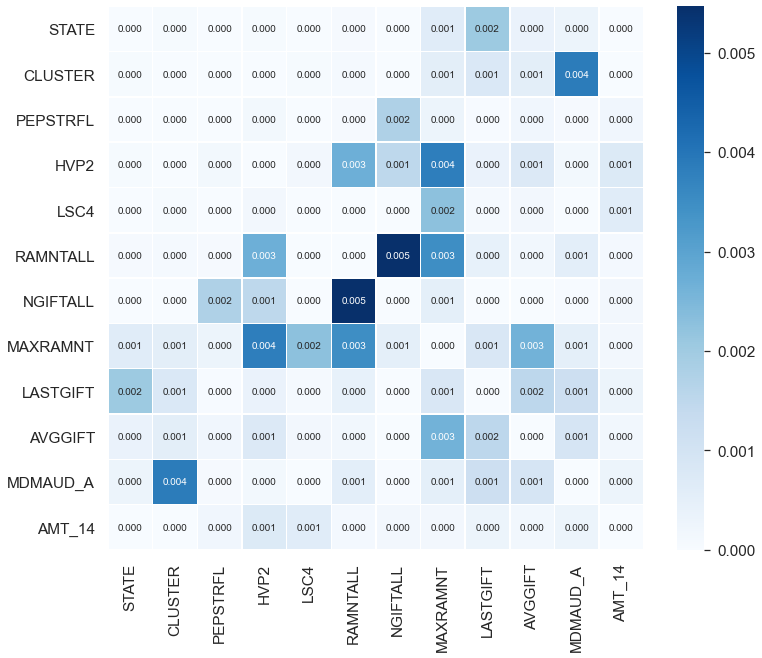
- SHAP 상호 작용 히트맵
이 히트맵은 SHAP 상호 작용 절대 평균에 따라 가장 두드러진 feature 상호 작용을 나타낸다.
But, 평균을 나타낸 히트맵이므로 대부분의 feature들의 관측값이 오른쪽으로 치우친 것(skewness)을 고려할 때 실제 관측값들은 히트맵의 평균보다 훨씬 높을 수 있다.
Feature Engineering의 목적은 모델이 이미 잘 하고 있는 것을 다시 발명하는 것이 아니라, 직접적인 모델 해석을 하는 것이다.
9. 미션 완료
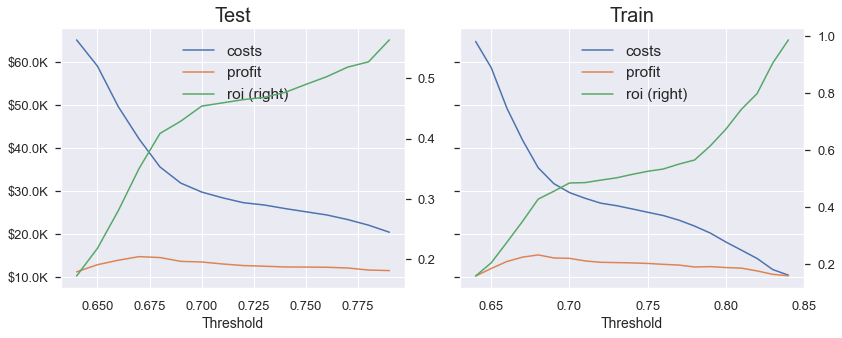
- 최종 모델(rf_5_e_llarsic)의 Test/Train 성능 그래프
이번 미션에 접근하기 위해 주로 Feature Selection 도구를 사용해 과적합을 줄였다.
비영리단체는 Test dataset의 모든 사람에게 우편물을 보내는 데 드는 비용보다 30,000달러 적은 비용으로 총 35,601달러의 비용으로 수익이 약 30% 증가한 것에 만족하고 있다.
다음 캠페인을 염두에 두고 모델링을 진행했지만, 이 모델은 재학습 없이 향후의 마케팅 캠페인에 사용될 가능성이 높다. 그러나, 모델의 재사용 시 시간이 지남에 따라 모델이 학습에 사용한 feature의 값이 변동되어 학습 내용이 더 이상 유효하지 않은 “Feature Drift” 또는 “Data Drift”가 발생할 수 있다.
또한, 학습 feature의 정의 자체가 시간이 지남에 따라 변해버리는 “Concept Drift”가 발생할 수도 있다.
인간 행동의 변화에 따라 이러한 drift 현상은 얼마든지 동시에 발생할 수 있다.